我们都知道ChatGPT4的综合能力肯定是大于ChatGPT3.5,

1:那么官方提供的 GPT3.5 API 能力和官方的 GPT3.5 能力相当吗?
(友情提示:ChatGPT3.5和ChatGPT3.5API是不一样的)
2:GPT4.0和GPT4.0配合联网搜索哪个效果好?
3:另外, Github 的 copilot chat 能力又怎样?
带着这些问题,我们用一个简单的编程问题,逐个进行测试,看看他们的表现如何?
问题:
帮我写一段python完整的代码,我希望用最快的效率爬取10000个网页,并存储在本地的mysql数据库。
ChatGPT3.5 APIimport requestsfrom bs4 import BeautifulSoupimport mysql.connector# 设置MySQL数据库连接db = mysql.connector.connect( host="localhost", user="your_username", password="your_password", database="your_database")cursor = db.cursor()# 爬取网页并存储到数据库def crawl_and_store(url): try: response = requests.get(url) soup = BeautifulSoup(response.text, 'html.parser') # 解析网页内容并提取需要存储的数据 # 这里只是一个示例,你需要根据具体的网页结构进行解析 title = soup.title.text.strip() content = soup.find('div', class_='content').text.strip() # 将数据插入到数据库中 query = "INSERT INTO webpages (url, title, content) VALUES (%s, %s, %s)" values = (url, title, content) cursor.execute(query, values) db.commit() print(f"成功爬取并存储网页: {url}") except Exception as e: print(f"爬取网页失败: {url}") print(f"错误信息: {str(e)}")# 待爬取的网页列表urls = [ "https://example.com/page1", "https://example.com/page2", # 添加更多的URL...]# 遍历网页列表进行爬取和存储for url in urls: crawl_and_store(url)# 关闭数据库连接cursor.close()db.close()
总结:
GPT3.5 API的代码写的简单明了。没什么大问题,但是却忽略了我的要求,我要求需要以最快的效率,但是它忽略了我的要求,依然用了最简单方法写了代码。
ChatGPT3.5import requestsimport mysql.connectorfrom concurrent.futures import ThreadPoolexecutor# 创建数据库连接db = mysql.connector.connect( host="localhost", user="your_username", password="your_password", database="your_database")cursor = db.cursor()# 创建表格cursor.execute("CREATE TABLE IF NOT EXISTS web_pages (id INT AUTO_INCREMENT PRIMARY KEY, url VARCHAR(255), content TEXT)")def fetch_and_store(url): try: response = requests.get(url) content = response.text # 存储到数据库 sql = "INSERT INTO web_pages (url, content) VALUES (%s, %s)" val = (url, content) cursor.execute(sql, val) db.commit() print(f"成功爬取并存储网页: {url}") except Exception as e: print(f"爬取网页 {url} 失败: {str(e)}")# 要爬取的网页列表urls = ["https://example.com/page1", "https://example.com/page2", ...] # 添加更多的URL# 创建线程池executor = ThreadPoolexecutor(max_workers=10) # 设置适当的线程数# 使用线程池并发地爬取和存储网页for url in urls: executor.submit(fetch_and_store, url)# 等待所有任务完成executor.shutdown()# 关闭数据库连接cursor.close()db.close()
总结:
ChatGPT3.5的网页版本是比API的效果要好的。有两点,第一,它分析出来,我在插入MySQL的之前是要创建表的,并且它注意到了我强调了要高效率的实现,代码也引入了多线程。
ChatGPT4import concurrent.futuresimport requestsimport pymysql.cursors# TODO: 替换为实际的网址列表url_list = ["http://www.example.com/1", "http://www.example.com/2", "..."]# 爬取单个网页的函数def fetch_url(url): response = requests.get(url) return url, response.text# 连接到 MySQLconnection = pymysql.connect(host='localhost', user='your_username', password='your_password', database='your_database', charset='utf8mb4', cursorclass=pymysql.cursors.DictCursor)try: # 创建一个线程池 with concurrent.futures.ThreadPoolExecutor(max_workers=10) as executor: # 使用线程池异步地爬取所有网页 future_to_url = {executor.submit(fetch_url, url): url for url in url_list} for future in concurrent.futures.as_completed(future_to_url): url = future_to_url[future] try: data = future.result() except Exception as exc: print('%r generated an exception: %s' % (url, exc)) else: print('%r page is %d bytes' % (url, len(data[1]))) # 存储到数据库 try: with connection.cursor() as cursor: sql = "INSERT INTO `your_table` (`url`, `content`) VALUES (%s, %s)" cursor.execute(sql, (data[0], data[1])) connection.commit() except Exception as error: print('Failed to update database: {}'.format(error))finally: connection.close()
总结:
ChatGPT4比ChatGPT3.5又升级了一版,理解了我要高效率的意思,不仅用了多线程还在注释里面强调:使用线程池异步地爬取所有网页。异步使得程序的抓取效率又上升了一个档次,而且还考虑到插入表的时候会报错。还打印出来了报错信息。可谓是非常规范了。
科大星火import requestsfrom bs4 import BeautifulSoupimport pymysql# 连接MySQL数据库def connect_db(): db = pymysql.connect(host='localhost', user='root', password='your_password', database='your_database', charset='utf8') return db# 爬取网页内容def get_html(url): try: response = requests.get(url) response.raise_for_status() response.encoding = response.apparent_encoding return response.text except: print("获取网页失败") return None# 解析网页内容def parse_html(html): soup = BeautifulSoup(html, 'html.parser') # 根据网页结构提取所需信息,这里需要根据实际情况修改 titles = soup.find_all('h1') for title in titles: yield title.text# 将数据存储到MySQL数据库def save_to_db(data): db = connect_db() cursor = db.cursor() sql = "INSERT INTO your_table (title) VALUES (%s)" try: cursor.executemany(sql, data) db.commit() except: db.rollback() print("保存数据失败") finally: cursor.close() db.close()if __name__ == '__main__': urls = ['https://www.example.com/page{}'.format(i) for i in range(1, 10001)] data = [] for url in urls: html = get_html(url) if html: parsed_data = parse_html(html) data.extend(parsed_data) if len(data) >= 10000: save_to_db(data) data = [] else: print("跳过无效网页") continue if data: save_to_db(data)
总结:基本效果等于ChatGPT3.5API
Copilotimport asyncioimport aiohttpimport pymysqlimport aiomysql# MySQL数据库配置信息DB_SETTINGS = { "host": "localhost", "database": "your_database", "user": "your_username", "password": "your_password",}# 你需要爬取的URL列表URLS = ["http://www.example.com"] * 10000async def fetch(session, url): async with session.get(url) as response: return await response.text()async def save_to_db(pool, url, content): async with pool.acquire() as conn: async with conn.cursor() as cur: # 根据你的数据表结构,写入具体的SQL语句 insert_sql = "INSERT INTO table_name(url, content) VALUES(%s, %s)" await cur.execute(insert_sql, (url, content)) await conn.commit()async def fetch_and_save(pool, session, url): content = await fetch(session, url) await save_to_db(pool, url, content)async def main(): async with aiohttp.ClientSession() as session: pool = await aiomysql.create_pool(**DB_SETTINGS) tasks = [] for url in URLS: task = asyncio.create_task(fetch_and_save(pool, session, url)) tasks.append(task) await asyncio.gather(*tasks)if __name__ == "__main__": asyncio.run(main())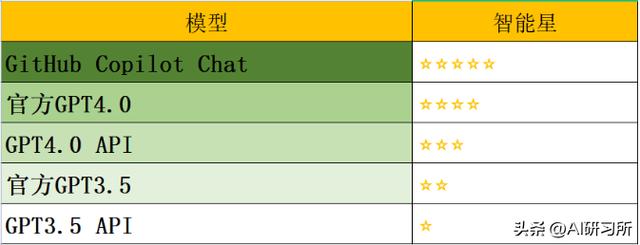
总结:
Github 的 copilot chat给了我心中最好的答案,采用asyncio和aiohttp,甚至使用了aiomysql,全程异步,最大程度的保证了代码的效率。代码写的也很优雅。综合评分如上图。
相关文章






关于作者

猜你喜欢
成员 网址收录40384 企业收录2981 印章生成228250 电子证书1002 电子名片58 自媒体44154































