编辑:好困 Aeneas
【新智元导读】备受关注的UC伯克利LLM排位赛又更新了!GPT-4依然岿然不动稳居榜首,GPT-3.5紧随其后,团队自家新发布的330亿参数Vicuna则冲至第五,代表了一众开源模型的最好成绩。就在刚刚,UC伯克利主导的「LLM排位赛」迎来了首次重磅更新!
这次,团队不仅在排行榜中加入了更多模型(目前已达到28个),而且还增加了2个全新的评价标准。

与此同时,团队还发布了更新的Vicuna-v1.3系列模型,参数量为70亿、130亿和330亿,且权重已公开。

增强版LLM排行榜
不难看出,GPT-3.5、Claude-v1和Claude-instant-v1这三个模型之间实际难分伯仲。不仅在MT-bench得分上咬得很紧,而且在诸如Elo和MMLU得分上还有后者还有反超。
和这些专有模型相比,开源模型们则有着明显的差距,即便是作为开源第一的Vicuna-33B也是如此。
当然,事情总有例外。比如谷歌的PaLM2,就落后于一众开源模型。
全新评价机制:MT-bench
虽然,现在已经有了不少用来评估大语言模型(LLM)性能的基准测试,比如MMLU、HellaSwag和HumanEval等。
但是,在评估LLM的人类偏好时,这些基准测试存在着明显的不足。
举个例子,传统的基准测试通常是在封闭式问题(例如,多项选择题)上对LLM进行测试,并提供一些简洁的输出作为评价。

此外,团队还在最新的论文「Judging LLM-as-a-judge」中进行了一项系统研究——揭示了LLM评判者的可靠性问题。
结果显示,像GPT-4这样强大的LLM评判者,可以与专家组和众包组的人类裁判的偏好非常好地对齐,一致性均超过了80%。
这种一致性水平,已经可以和两个人类评判者之间的一致性相媲美。
而基于GPT-4的单个答案评分,也可以有效地对模型进行排名,并与人类偏好很好地匹配。
因此,如果使用得当,LLM评判者完全可以作为人类偏好的可扩展、可解释的近似值。
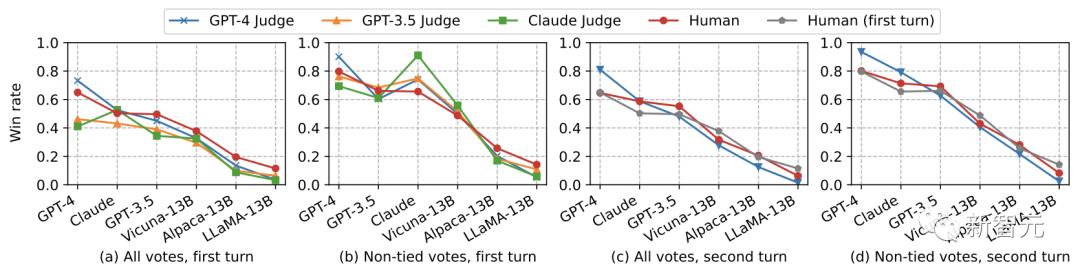
不过,当LLM作为评判者时,依然会存在一些潜在限制:
1. 位置偏差,即LLM评判者可能偏向于在成对比较中选择第一个答案。
2. 冗长偏差,即LLM评判者可能偏向于更长的回答,而不考虑其质量。
3. 自我增强偏差,即LLM评判者可能偏向于自己的回答。
4. 推理能力有限,即LLM评判者在给数学和推理问题打分时,会存在一些缺陷。
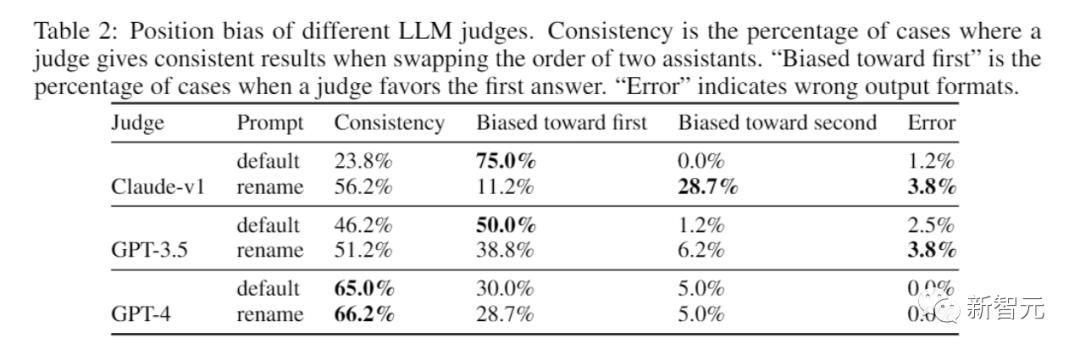
不同LLM评判者的立场偏见
其中,所谓的「一致性」是指评判者在LLM顺序交换时,给出一致性结果的案例百分比
对于这些限制,团队探讨了如何利用少样本评判、思维链评判、基于参考的评判和微调评判来进行缓解。
结果分析
MT-Bench有效地区分了LLM之间的性能差异
在这次的「排位赛」中,团队针对28个模型进行了全面评估。
结果显示,不同能力的LLM之间存在明显的区别,而它们的得分与Chatbot Arena Elo评分呈高度的相关性。
特别是MT-Bench的引入,非常鲜明地显示出:GPT-4与GPT-3.5/Claude之间,以及开源和专有模型之间,有着明显的性能差距。
为了更深入地了解LLM之间的差距,团队选择了几个有代表性的LLM,并分析了它们在每个类别下的表现。
结果显示,与GPT-3.5/Claude相比,GPT-4在编码和推理方面表现出更高的性能,而Vicuna-13B在几个特定的类别中(包括提取、编码和数学)明显落后。
这表明,开源模型仍有很大的改进空间。
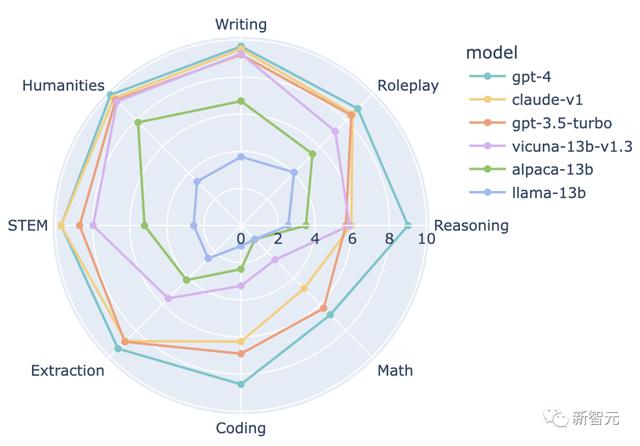
比较6个模型的8种能力:写作、角色扮演、推理、数学、编码、信息提取、自然科学、人文科学
多轮对话能力的评估
团队接下来分析了所选模型在多轮对话中的得分。
开源模型在第一轮和第二轮之间的性能显著下降(如Vicuna-7B,WizardLM-13B),而强大的专有模型却始终保持着一致性。
另外,基于LLaMA的模型和更宽松的模型之间(如MPT-7B、Falcon-40B和调整后的Open-LLaMA),也存在明显的性能差距。
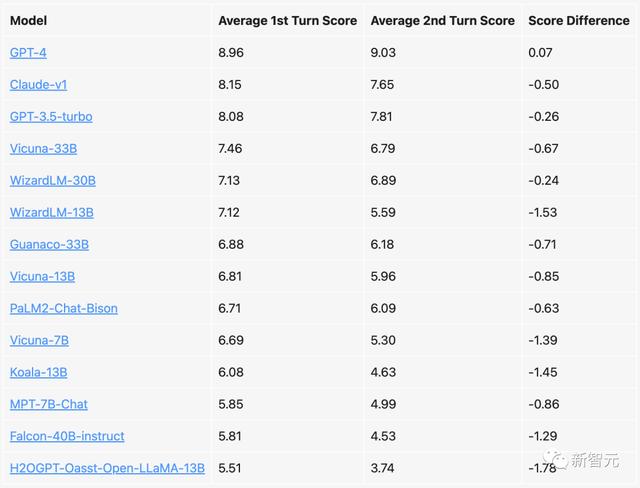
模型在第一轮和第二轮对话中的MT-bench得分,满分为10分
LLM评判者的可解释性
用LLM进行评判的另一个优势在于,它们能够提供可解释的评估结果。
下图展示了GPT-4对一个MT-bench问题的判断,其中包括了来自alpaca-13b和gpt-3.5-turbo的回答。
可以看到,对于自己给出的判断,GPT-4提供了详细全面、逻辑清晰的反馈。
而UC伯克利的研究也认为,这种评价有利于指导人类做出更明智的决策。

MT-bench在评估LLM的人类偏好方面提供了更多的可解释性
总之,MT-Bench可以有效地区分不同的聊天机器人。
不过在使用时,仍然应该谨慎。因为它还是有出错的可能,尤其是在数学/推理问题打分时。
下一步计划
发布对话数据
团队计划发布Chatbot Arena的对话数据,以供更广泛的研究社区使用,敬请期待。
MT-bench-1K
目前,团队正在积极扩展问题集,将Chatbot Arena的高质量提示集成进来,并利用LLM自动生成新的问题,进而建立更丰富的MT-Bench-1K数据集。
参考资料:
相关文章






关于作者

猜你喜欢
成员 网址收录40394 企业收录2981 印章生成234944 电子证书1036 电子名片60 自媒体46963































