如图2-2所示,我们先看一下Notion 问答对话AI案例的效果。你问一个问题,它会进行回答,然后它会告诉你,信息来源在什么地方,要看具体的信息,可以按照它提供的信息来源,去看具体的Notion内容。

图2- 2 Notion 问答对话AI演示页面
这是LangChain官方提供的一个案例,包括Notion本地的数据,里面会有项目的数据、进度管理的数据,也会有企业服务的一些数据。作者曾经做过一个分布式项目,团队使用Notion写作的方式,它里面会有整个项目、整个团队、会议等信息。在这个案例里面,可以以对话的方式获得整个Notion的信息,这显然是一件很有价值的事情,假设整个企业使用Notion平台,已经用了5年的时间,Notion里面会有海量的信息,要查询信息和定位信息,这是一个很费时费力的过程,如果我们使用一个简单的接口,用自然语言的方式询问LangChain,让LangChain以大模型驱动为基础,跟企业的私有数据进行交互,显然这对于提升我们的工作效率或者满意度,促进团队协作具有很大的价值。
我们问一个问题,输入信息:“how long is the probation period?”(“试用期有多长?”)
how long is the probation period?
它给我们的回复如下,已经告诉我们结果了,“试用期为一个月”,同时告诉你,具体的内容在哪里,“Blendle's Employee Handbook”是Blendle公司的员工手册,这样一个对话的方式,展示了我们描述的项目流程,我们会不断的优化这个流程,尤其是一些大的项目,将综合使用各个组件。
Answer: The probation period is one month. Sources: Notion_DBBlendle's Employee Handbook a834d55573614857a48a9ce9ec4194e3Your 1st month 5f253fc3413b427f8df1c4d0155ac153.md
如图2-3所示,是Notion_DB本身的数据,没什么特殊的地方。
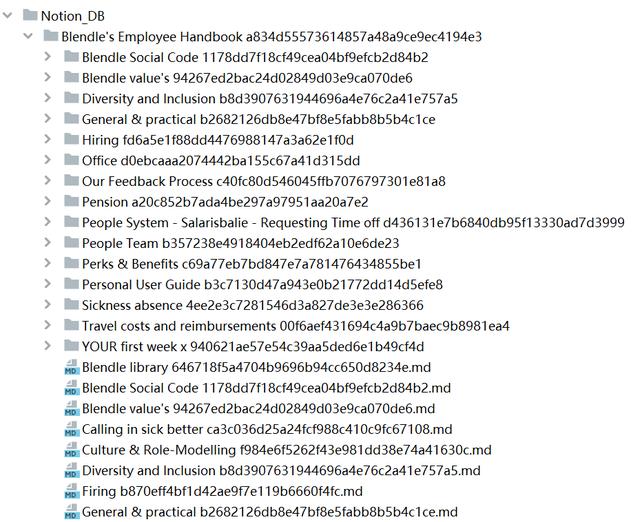
图2- 3 Notion_DB数据库
我们先看一下main.py主文件,实现了一个简单的聊天机器人,用于与用户进行对话。使用Streamlit框架作为用户界面,定义一个文本输入框,用于用户输入问题。当用户输入问题后,代码将使用模型来生成答案,并将答案和相关来源返回给用户。用户之前的输入和机器人的回答被存储在session_state中,以便用户可以查看之前的对话历史。界面或者基础的内容先不谈,跟大家谈几个很重要的点,首先传入一个OpenAI的大模型参数,构建一个VectorDBQAWithSourcesChain的实例,LangChain有很多链,可以认为这是一个用户用例,大多数情况下,在企业的经典场景中,可能要跟一个向量数据库进行交互等等。这里使用faiss向量数据库,这是Facebook提供的高效检索的向量数据库工具,使用相似度来进行检索, 相似度是一种很简单的思维,会跟大家谈很多企业级的技巧,远远不止于此,这里面会涉及到一些问题,比如速度问题等等,在代码中,将OpenAI的温度参数(temperature)设置为0,以获得相同的结果,store是基于faiss构建的向量索引库,接下来,根据用户的输入,基于输入信息,跟OpenAI大模型进行交互,它的核心代码本身是很简单的。
main.py的代码实现:
"""Python file to serve as the frontend"""import streamlit as stfrom streamlit_chat import messageimport osimport openaiimport faissfrom langchain import OpenAIfrom langchain.chains import VectorDBQAWithSourcesChainimport pickleimport pathlibtemp = pathlib.PosixPathpathlib.PosixPath = pathlib.WindowsPathopenai.api_key = os.getenv("OPENAI_API_KEY")# 加载 LangChain.index = faiss.read_index("docs.index")with open("faiss_store.pkl", "rb") as f:store = pickle.load(f)store.index = indexchain = VectorDBQAWithSourcesChain.from_llm(llm=OpenAI(temperature=0), vectorstore=store)# StreamLit UI页面st.set_page_config(page_title="Notion QA Conversational AI", page_icon=":robot:")st.header("Notion QA Conversational AI")if "generated" not in st.session_state:st.session_state["generated"] = []if "past" not in st.session_state:st.session_state["past"] = []def get_text():input_text = st.text_input("You: ", "Hello, how are you?", key="input")return input_textuser_input = get_text()if user_input:result = chain({"question": user_input})output = f"Answer: {result['answer']}nSources: {result['sources']}"st.session_state.past.append(user_input)st.session_state.generated.append(output)if st.session_state["generated"]:for i in range(len(st.session_state["generated"]) - 1, -1, -1):message(st.session_state["generated"][i], key=str(i))message(st.session_state["past"][i], is_user=True, key=str(i) "_user")看一下 qa.py文件,它本身使用检索的方式,如果使用LangChain框架,它帮你简化了很多内容,在这边直接使用了一个VectorDBQAWithSourcesChain,看上去很神奇。程序使用LangChain库中的RetrievalQAWithSourcesChain链来处理问答,使用ChatOpenAI作为语言模型,并使用存储器store作为检索器,存储器store是一个基于faiss构建的向量索引库,用于快速的相似度搜索。使用这个模型,程序可以快速地查找数据库中与问题相关的信息,并返回答案和相关来源。
qa.py的代码实现:
""" 向notion 数据库提问"""import faissfrom langchain.chat_models import ChatOpenAIfrom langchain.chains import RetrievalQAWithSourcesChainimport pickleimport argparseimport pathlibtemp = pathlib.PosixPathpathlib.PosixPath = pathlib.WindowsPathparser = argparse.ArgumentParser(description='Ask a question to the notion DB.')parser.add_argument('question', type=str, help='The question to ask the notion DB')args = parser.parse_args()# 加载LangChain.index = faiss.read_index("docs.index")with open("faiss_store.pkl", "rb") as f:store = pickle.load(f)store.index = indexchain = RetrievalQAWithSourcesChain.from_chain_type(llm=ChatOpenAI(temperature=0), retriever=store.as_retriever())result = chain({"question": args.question})print(f"Answer: {result['answer']}")print(f"Sources: {result['sources']}")上段代码中第22行调用了from_chain_type函数,进入源码看一下,from_chain_type方法用于从特定的chain类型中加载一个QAWithSourcesChain,并返回一个BaseQAWithSourcesChain类型的实例。方法接受一个BaseLanguageModel类型的语言模型,以及一个可选的chain_type_kwargs字典和其他关键字参数,通过调用load_qa_with_sources_chain函数来加载特定的chain类型,并使用它来初始化一个BaseQAWithSourcesChain实例。其中,chain类型是由用户指定的,可以是不同的内容。通过使用不同的chain类型,用户可以创建不同的语言模型和信息检索模型,以适应不同的应用场景。同时,这个方法也可传入一个可选的chain_type_kwargs字典,以便用户可以对模型进行自定义和优化。
base.py的代码实现:
@classmethoddef from_chain_type(cls,llm: BaseLanguageModel,chain_type: str = "stuff",chain_type_kwargs: Optional[dict] = None,**kwargs: Any,) -> BaseQAWithSourcesChain:"""从链型加载链."""_chain_kwargs = chain_type_kwargs or {}combine_document_chain = load_qa_with_sources_chain(llm, chain_type=chain_type, **_chain_kwargs)return cls(combine_documents_chain=combine_document_chain, **kwargs)在load_qa_with_sources_chain方法中,加载问题和回答的源链,第一个参数是大语言模型,第二个参数是chain_type,跟本地私有数据进行交互的时候,会涉及到两个问题,第一个是数据规模的问题,第二个是处理速度的问题。
loading.py的代码实现:
def load_qa_with_sources_chain(llm: BaseLanguageModel,chain_type: str = "stuff",verbose: Optional[bool] = None,**kwargs: Any,) -> BaseCombineDocumentsChain:"""加载问题回答与源链参数:llm:在链中使用的语言模型chain_type:要使用的文档组合链的类型. 是以下类型之一 "stuff", "map_reduce", "refine".verbose: 链是否应该以verbose模式运行。请注意适用于构成最终链的所有链。返回:一个链,用于用源回答问题"""loader_mapping: Mapping[str, LoadingCallable] = {"stuff": _load_stuff_chain,"map_reduce": _load_map_reduce_chain,"refine": _load_refine_chain,"map_rerank": _load_map_rerank_chain,}if chain_type not in loader_mapping:raise ValueError(f"Got unsupported chain type: {chain_type}. "f"Should be one of {loader_mapping.keys()}")_func: LoadingCallable = loader_mapping[chain_type]return _func(llm, verbose=verbose, **kwargs)《企业级ChatGPT开发入门实战直播21课》报名课程请联系:
Gavin老师:NLP_Matrix_Space
Sam老师:NLP_ChatGPT_LLM
我们的两本最新书籍年底即将出版:
《企业级Transformer&ChatGPT解密:原理、源码及案例》《企业级Transformer&Rasa解密:原理、源码及案例》《企业级Transformer&ChatGPT解密:原理、源码及案例》本书以Transformer和ChatGPT技术为主线,系统剖析了Transformer架构的理论基础、模型设计与实现,Transformer语言模型GPT与BERT,ChatGPT技术及其开源实现,以及相关应用案例。内容涉及贝叶斯数学、注意力机制、语言模型、最大似然与贝叶斯推理等理论,和Transformer架构设计、GPT、BERT、ChatGPT等模型的实现细节,以及OpenAI API、ChatGPT提示工程、类ChatGPT大模型等应用。第一卷介绍了Transformer的Bayesian Transformer思想、架构设计与源码实现,Transformer语言模型的原理与机制,GPT自回归语言模型和BERT自编码语言模型的设计与实现。第二卷深入解析ChatGPT技术,包括ChatGPT发展历史、基本原理与项目实践,OpenAI API基础与高级应用,ChatGPT提示工程与多功能应用,类ChatGPT开源大模型技术与项目实践。
ChatGPT 技术:从基础应用到进阶实践涵盖了ChatGPT技术和OpenAI API的基础和应用,分为8个章节,从ChatGPT技术概述到类ChatGPT开源大模型技术的进阶项目实践。
1. ChatGPT技术概述:主要介绍了GPT-1、GPT-2、GPT-3、GPT-3.5和GPT-4的发展历程和技术特点,以及ChatGPT技术的基本原理和项目案例实战。
2. OpenAI API基础应用实践:主要介绍了OpenAI API模型及接口概述,以及如何使用OpenAI API进行向量检索和文本生成。
3. OpenAI API进阶应用实践:主要介绍了如何使用OpenAI API基于嵌入式向量检索实现问答系统,如何使用OpenAI API对特定领域模型进行微调。
4. ChatGPT提示工程基础知识:主要介绍了如何构建优质提示的两个关键原则,以及如何迭代快速开发构建优质提示。
5. ChatGPT提示工程实现多功能应用:主要介绍了如何使用ChatGPT提示工程实现概括总结、推断任务、文本转换和扩展功能。
6. ChatGPT提示工程构建聊天机器人:主要介绍了聊天机器人的应用场景,以及如何使用ChatGPT提示工程构建聊天机器人和订餐机器人。
7. 类ChatGPT开源大模型技术概述:主要介绍了类ChatGPT开源大模型的发展历程和技术特点,以及ChatGLM项目案例实践和LMFlow项目案例实践。
8. 类ChatGPT开源大模型进阶项目实践:主要介绍了类ChatGPT开源大模型的进阶项目实践,包括基于LoRA SFT RM RAFT技术进行模型微调、基于P-Tuning等技术对特定领域数据进行模型微调、基于LLama Index和Langchain技术的全面实践,以及使用向量检索技术对特定领域数据进行模型微调。
本书适用于NLP工程师、AI研究人员以及对Transformer和ChatGPT技术感兴趣的读者。通过学习,读者能够系统掌握Transformer理论基础,模型设计与训练推理全过程,理解ChatGPT技术内幕,并能运用OpenAI API、ChatGPT提示工程等技术进行项目实践。
Transformer作为目前NLP领域最为主流和成功的神经网络架构,ChatGPT作为Transformer技术在对话系统中的典型应用,本书内容涵盖了该领域的最新进展与技术。通过案例实践,使理论知识变成技能,这也是本书的独特之处。
《企业级Transformer&Rasa解密:原理、源码及案例》:是一本深入介绍Rasa对话机器人框架的实战开发指南。本书分为两卷,第一卷主要介绍基于Transformer的Rasa Internals解密,详细介绍了DIETClassifier和TED在Rasa架构中的实现和源码剖析。第二卷主要介绍Rasa 3.X硬核对话机器人应用开发,介绍了基于Rasa Interactive Learning和ElasticSearch的实战案例,以及通过Rasa Interactive Learning发现和解决对话机器人的Bugs案例实战。
第一卷中介绍了Rasa智能对话机器人中的Retrieval Model和Stateful Computations,解析了Rasa中去掉对话系统的Intent的内幕,深入研究了End2End Learning,讲解了全新一代可伸缩的DAG图架构的内幕,介绍了如何定制Graph NLU及Policies组件,讨论了自定义GraphComponent的内幕,从Python角度分析了GraphComponent接口,详细解释了自定义模型的create和load内幕,并讲述了自定义模型的languages及Packages支持。深入剖析了自定义组件Persistence源码,包括自定义对话机器人组件代码示例分析、Resource源码逐行解析、以及ModelStorage、ModelMetadata等逐行解析等。介绍了自定义组件Registering源码的内幕,包括采用Decorator进行Graph Component注册内幕源码分析、不同NLU和Policies组件Registering源码解析、以及手工实现类似于Rasa注册机制的Python Decorator全流程实现。讨论了自定义组件及常见组件源码的解析,包括自定义Dense Message Featurizer和Sparse Message Featurizer源码解析、Rasa的Tokenizer及WhitespaceTokenizer源码解析、以及CountVectorsFeaturizer及SpacyFeaturizer源码解析。深入剖析了框架核心graph.py源码,包括GraphNode源码逐行解析及Testing分析、GraphModelConfiguration、ExecutionContext、GraphNodeHook源码解析以及GraphComponent源码回顾及其应用源码。
第二卷主要介绍了基于Rasa Interactive Learning和ElasticSearch的实战案例,以及通过Rasa Interactive Learning发现和解决对话机器人的Bugs案例实战。介绍了使用Rasa Interactive Learning来调试nlu和prediction的案例实战,使用Rasa Interactive Learning来发现和解决对话机器人的Bugs案例实战介绍了使用Rasa Interactive Learning透视Rasa Form的NLU和Policies的内部工作机制案例实战,使用ElasticSearch来实现对话机器人的知识库功能,并介绍了相关的源码剖析和最佳实践,介绍了Rasa微服务和ElasticSearch整合中的代码架构分析,使用Rasa Interactive Learning对ConcertBot进行源码、流程及对话过程的内幕解密,介绍了使用Rasa来实现Helpdesk Assistant功能,并介绍了如何使用Debug模式进行Bug调试,使用Rasa Interactive Learning纠正Helpdesk Assistant中的NLU和Prediction错误,逐行解密Domain和Action微服务的源码。
本书适合对Rasa有一定了解的开发人员和研究人员,希望通过本书深入了解Rasa对话机器人的内部工作原理及其源代码实现方式。无论您是想要深入了解Rasa的工作原理还是想要扩展和定制Rasa,本书都将为您提供有价值的参考和指导。
《企业级Transformer&ChatGPT解密:原理、源码及案例》、《企业级Transformer&Rasa解密:原理、源码及案例》,是您深入学习的好选择,年底即将重磅出版,欢迎购买!
相关文章






关于作者

猜你喜欢
成员 网址收录40394 企业收录2981 印章生成235106 电子证书1037 电子名片60 自媒体46963































