古代说一个人知识渊博,用“学富五车”来形容;本文讲述的GPT3模型,训练原始语料有45TB, 相当于5块的10TB的机械硬盘,可能相当于几千人一生读过的所有书吧。
本文是对GPT3这个模型的简单总结。
1 背景及问题描述近年来,NLP系统呈现出一种 预训练语言表示 的趋势,并以越来越灵活且与任务无关的方式在下游任务进行知识迁移。
首先,使用 词向量 学习单层表示并将其馈送到特定于下游任务的网络结构然后使用 具有多层表示和上下文状态的RNN 形成更强的表示(尽管仍然应用于特定任务的体系结构)并且最近已经对预训练的递归或 transformer语言模型 [VSP 17]进行了直接微调,从而完全消除了对特定任务的网络结构的需求:BERT最后一个范例在许多具有挑战性的NLP任务上取得了实质性进展,例如阅读理解,问题回答,文本蕴涵等,并且基于BERT新的网络结构和算法在发展。但是,此方法的主要局限性在于,尽管网络结构与任务无关,但仍需要 特定于任务的数据集和特定于任务的微调: 要在所需任务上实现更好的精度通常需要对特定任务进行微调,通常下游任务需要成千上万个示例的数据集。由于多种原因,希望消除此限制:
首先,从实际角度出发,每个新任务都需要有大量带标签示例的数据集,这限制了语言模型的适用性。存在各种各样可能的有用的语言任务,包括从纠正语法到生成抽象概念的示例到撰写短篇小说的任何内容。对于这些任务中的许多任务,很难收集大型的有监督的训练数据集,尤其是当必须为每个新任务重复该过程时。其次,随着模型的表现力和训练分布范围的缩小,利用训练数据中的虚假相关性的潜力从根本上增加。这会给预训练加微调范式带来问题,在这种情况下,模型被设计得很大,可以在预训练期间吸收信息,但随后会在非常狭窄的任务分布上进行微调。例如,[HLW 20]观察到,较大的模型不一定能概括出更好的分布外分布。有证据表明,在该范式下实现的泛化效果可能很差,因为该模型过于针对训练分布而无法很好地泛化[YdC 19,MPL19]。因此,即使在名义上处于名义水平,微调模型在特定基准上的性能也会夸大底层任务的实际性能[GSL 18,NK19]。第三,人类不需要大型的监督数据集即可学习大多数语言任务-简短的自然语言指令(例如“请告诉我这句话描述的是快乐还是悲伤”)或最多很少的示范(例如“此处是勇敢的人的两个例子;请举一个勇敢的人的第三个例子。)通常足以使一个人至少在合理的能力范围内执行一项新任务。除了指出当前NLP技术的概念局限性之外,这种适应性还具有实际优势–它使人类可以无缝地混合在一起或在许多任务和技能之间切换,例如在漫长的对话中进行添加。为了广泛使用,我们希望有一天我们的NLP系统具有相同的流动性和通用性。Note
简而言之,问题是:
数据标注成本高,如何在少量样本上、大规模监督语料上的条件下,获得一个模型,这个模型在下游任务上表现良好?
有没有可能去除Fine-Tune阶段,因为需要对网络结构和参数进行调整,很麻烦。
2 已有的解决方案解决这些问题的一种潜在途径是元学习: 在语言模型的上下文中,这意味着该模型在训练时会开发出广泛的技能和模式识别能力,然后在推理时使用这些能力快速适应或识别目标任务(如图1.1所示)。最近的工作[RWC 19]试图通过我们所谓的“上下文学习”来实现此目的,使用预先训练的语言模型的文本输入作为任务说明的形式:该模型以自然语言指令 和/或 很少的任务演示,然后仅通过预测接下来会发生什么,就可以完成该任务的更多实例。尽管它显示了一些初步的希望,但这种方法仍然取得的效果远不及微调-例如[RWC 19]在自然问题上仅达到4%,甚至其55 F1 CoQa结果现在也比第一名落后35分以上。元学习显然需要实质性的改进,以便能够作为解决语言任务的实用方法。
语言建模的另一种最新趋势可能提供了前进的道路。近年来,Transormer语言模型的容量已从1亿个参数[RNSS18]增至3亿个参数[DCLT18],增至15亿个参数[RWC 19],增至80亿个参数[SPP 19],11十亿个参数[RSR 19],最后是170亿个参数[Tur20]。每次增加都带来了文本合成和/或下游NLP任务的改进,并且有证据表明,与许多下游任务密切相关的对数损失遵循随规模的平稳增长趋势[KMH 20]。由于上下文学习涉及吸收模型参数范围内的许多技能和任务,因此上下文学习能力可能会随着规模的增长而显示出类似的强劲增长。
Note
机器学习法论:
单任务机器学习(single task learning),如果达到好的精度,需要这个任务有成百上千个例子,实际应用时每个任务都需要成百上千个例子,成本比较高;并且一个任务,需要一个训练模型。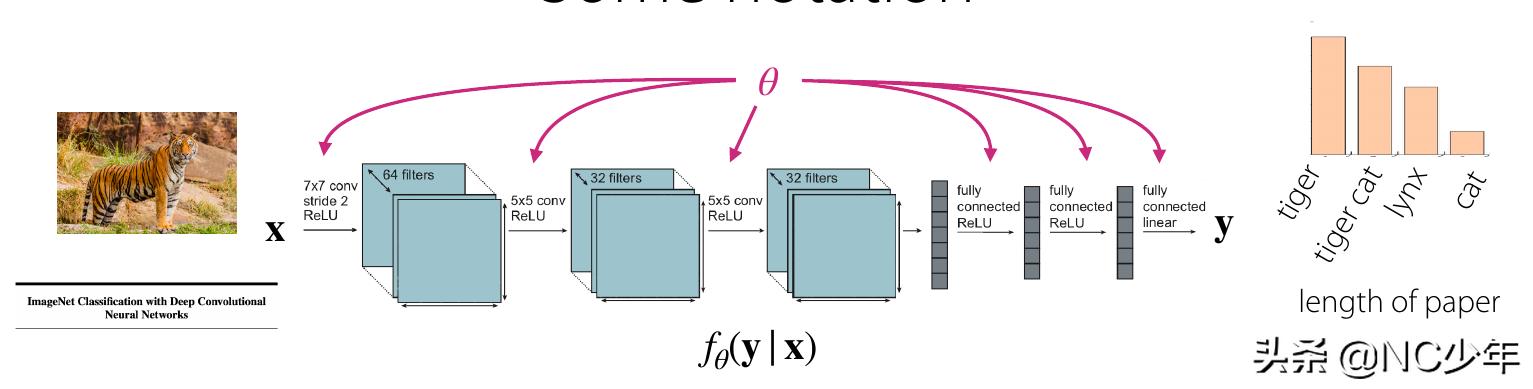 迁移学习(Transfer Learning): Pre-train Finetune,在大规模语料(通常都是非监督)上进行学习,在下游任务上进行Fine-Tune,下游的任务不需要很大的数据集。迁移的目的是在下游任务上表现好,一般原任务的精度会下降。多任务学习(Multi-task Learning),多个任务同时学习,好处对于M个任务,只需要学习一个模型,这个模型在多个任务上表现都不错,缺点还是需要每个任务需要成百上千个数据样本。
迁移学习(Transfer Learning): Pre-train Finetune,在大规模语料(通常都是非监督)上进行学习,在下游任务上进行Fine-Tune,下游的任务不需要很大的数据集。迁移的目的是在下游任务上表现好,一般原任务的精度会下降。多任务学习(Multi-task Learning),多个任务同时学习,好处对于M个任务,只需要学习一个模型,这个模型在多个任务上表现都不错,缺点还是需要每个任务需要成百上千个数据样本。 元学习:学习如何学习,比如MAML会学习如何初始化一个最好的模型参数,找到潜力最好的初始化参数。
元学习:学习如何学习,比如MAML会学习如何初始化一个最好的模型参数,找到潜力最好的初始化参数。 3 提出的解决方案
3 提出的解决方案在本文中,我们通过训练1750亿个参数自回归语言模型(称为GPT-3)并测量其在上下文中的学习能力来检验该假设。具体来说,我们评估了超过两打NLP数据集的GPT-3,以及旨在测试快速适应不太可能直接包含在训练集中的任务的几个新颖任务。对于每项任务,我们在3种情况下评估GPT-3:
(a)少量学习或上下文学习,其中我们允许尽可能多的演示适合模型的上下文窗口(通常为10至100),(b)单次学习,仅允许一次演示;(c)零次学习,不允许进行演示,仅对模型提供自然语言的说明。GPT-3原则上也可以在传统的微调环境中进行评估,但我们将其留待以后的工作。
图1.2说明了我们研究的条件,并显示了对简单任务的小样本学习,该简单任务要求模型从单词中删除多余的符号。通过添加自然语言任务描述以及模型上下文中的示例数量,K可以提高模型性能。很少学习也可以随着模型大小的提高而大大提高。尽管在这种情况下的结果特别引人注目,但是对于我们研究的大多数任务,模型大小和上下文中示例数量的总体趋势仍然适用。我们强调,这些学习曲线 不涉及梯度更新或微调,而只是增加了作为条件的演示次数。
广义上讲,在NLP任务上,GPT-3在零样本和单样本设置中取得了可喜的结果,而在少数样本设置中,有时甚至可以与最先进的方法竞争(甚至超越,由微调的模型掌握)。例如,GPT-3在零样本设置下在CoQA上达到81.5 F1,在单样本设置下在CoQA上达到84.0 F1,在少样本设置下达到85.0 F1。同样,GPT-3在零样本设置下的TriviaQA上达到64.3%的准确度,在单样本设置下达到68.0%,在小样本设置下达到71.2%,最后一个是最先进的微调模型的精度。
Note
延续GPT的模型架构,用更多的数据,更大的模型,训练模型。预测时,不需要Finetune,在某些任务上小样本条件下也能达到和BERT媲美的性能。预测时,分别用自然语言描述任务(零样本)、一个示例(单样本,和人类学习很像)、少量示例作为上文文本,将续写的文本作为预测结果。值得一提的是,数据太大,没有用Bloomfilter做去重,用的是Spark进行去重,中间一个BUG,后来发现了,但是没有重新训练,因为重新训练成本太高了!
4 方案效果GPT3的模型参数有1750亿,假设都是浮点32位,存储空间是651G, 普通的服务器即使推理也无法预测。
清源2020年年底发布了中文预训练的GPT模型,据说是“用64张V100训练了3周”, "26亿参数规模的中文语言模型", 参数离英文的GPT3 1750亿小50倍。预测文本生成的语法上没有多大问题,但在语义上可能有问题,尤其是长文本生成。
5 个人思考NLP领域有无穷大的语料,古代说一个人知识渊博,用“学富五车”形容; GPT3的训练原始语料有45TB, 相当于5块的10T的机械硬盘(光硬盘几乎都要1万人民币),可能相当于几千人一生读过的所有书吧。方法太暴力,但是也探索了语言模型的潜在能力,并且还没探索到边界。
如何利用这么大的语料,并应用到具体落地场景,是一个探索的方向。
模型从算法层面没有多大创新,难度在于工程和资源:
64张V100,训练三周,训练出26亿中文,乘以50倍,相当于GPT3的用到的资源工程上如何利用多GPU、多机训练,如何进行并行计算和传输? 毕竟是1750亿个参数。相关文章









关于作者

猜你喜欢
成员 网址收录40394 企业收录2981 印章生成234305 电子证书1033 电子名片60 自媒体46877































