机器之心报道
编辑:赵阳
作为最领先的大模型,GPT-4 有自我纠正生成代码的能力,结合人类反馈,自我纠正能力还能进一步的提高。
大型语言模型(LLM)已被证明能够从自然语言中生成代码片段,但在应对复杂的编码挑战,如专业竞赛和软件工程专业面试时,仍面临巨大的挑战。最近的研究试图通过利用自修复来提高模型编码性能。自修复是指让模型反思并纠正自己代码中的错误。
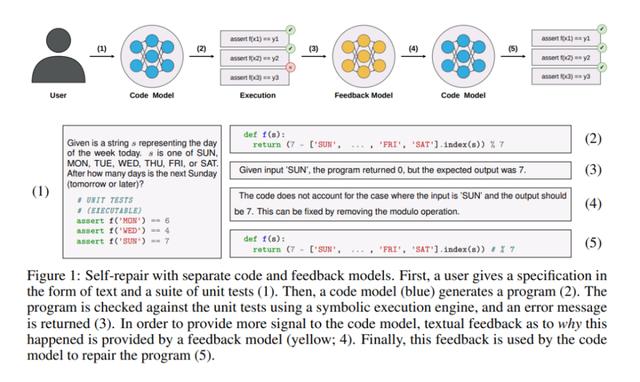
下图 1 显示了基于自修复方法的典型工作流程。首先,给定一个规范,从代码生成模型中对程序进行采样;然后在作为一部分规范提供的一套单元测试上执行程序;如果程序在任一单元测试中失败,则将错误消息和错误程序提供给一个反馈生成模型,该模型输出代码失败原因的简短解释;最后,反馈被传递给修复模型,该模型生成程序的最终固化版本。
从表面上看,这是一个非常有吸引力的想法。这种设计能让系统克服在解码过程中由离群样本引起的错误;在修复阶段,可以轻松地整合来自编译器、静态分析工具和执行引擎等符号系统的反馈,并模仿人类软件工程师编写代码的试错方式。
论文地址:https://arxiv.org/pdf/2306.09896.pdf
从本文的实验中,研究者有了以下发现:
1. 当考虑进行检查和修复的成本时,自修复的性能收益只能用 GPT-4 来衡量;对于 GPT-3.5,在所有配置下,修复的通过率低于或等于基线模型 / 无修复方法的通过率。
2. 即使对于 GPT-4,性能提升也是适度的(66%→ 71% 的通过率,预算为 7000 个 token,约 45 个独立同分布(i.i.d.)的 GPT-4 样本),并同时取决于初始程序是否具有足够的多样性。
3. 用 GPT-4 产生的反馈代替 GPT-3.5 对错误的解释,可以获得更好的自修复性能,甚至超过了基线的无修复 GPT-3.5 方法(50%→ 7000token 时为 54%)。
4. 用人类的解释取代 GPT-4 自己的解释可以显著改善修复结果,从而使通过测试的修复程序数量增加 57%。
爱丁堡大学博士生符尧表示:「只有 GPT-4 可以自我改进,而较弱的模型不能,这一发现非常有趣,表明(大模型存在)一种新型的涌现能力(即改进自然语言反馈),可能只有在模型足够成熟(大而整齐)时才存在。大模型的这种能力在论文《Improving Language Model Negotiation with Self-Play and In-Context Learning from AI Feedback》中也存在过。
只有足够成熟的模型才能清楚(listen to)并改进自然语言反馈,较弱的模型要么无法理解反馈,要么无法对其进行改进。
我倾向于相信这种涌现能力(通过语言反馈进行自我改进)会对 LLM 研究产生非常重要的影响,因为这意味着 AI 可以在很少的人类监督下不断自主改进。」

方法
自修复概述
如上图 1 所示,自修复方法包括 4 个阶段:代码生成、代码执行、反馈生成和代码修复。接下来正式定义这四个阶段。
代码生成
给定一个规范 ψ,程序模型 M_P 首先生成 n_p 个独立同分布样本,研究者将其表示为
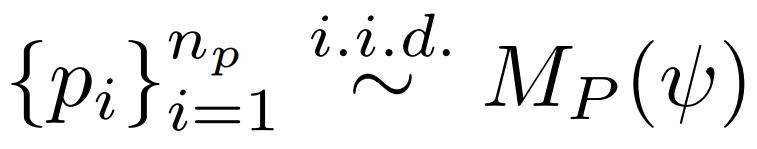
修复树。研究者将该过程生成的包含文本和程序的树称为植根于规范中的 ψ,然后分支到初始程序 p_i,每个初始程序分支到反馈 f_ij,然后对修复树 r_ijk 进行修复,如下图所示。

注意:联合采样反馈和修复。上述通用框架不要求编程模型和反馈模型相同,因此两个模型可以使用各自的专有模型。然而,当 M_P=M_F 时,研究者在单个 API 调用中联合生成反馈和修复的程序,因为 GPT-3.5 和 GPT-4 都有在响应中交织文本和代码的自然倾向。形式上,研究者将其表示为
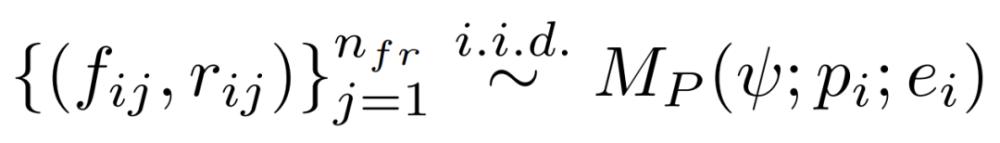
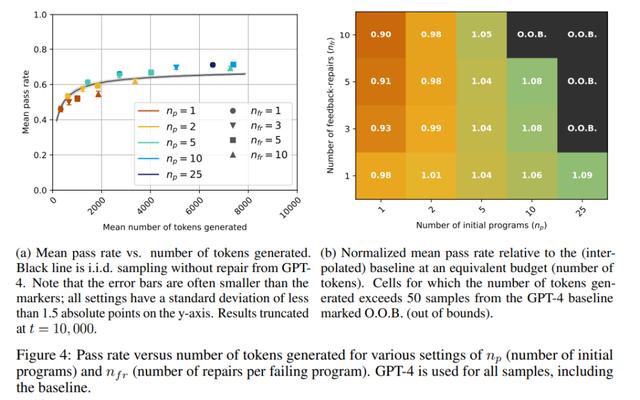
从图中可以看出,对于 GPT-3.5 模型,pass@t 在所有的 n_p、n_fr 选值中,都低于或等于相应基线(黑线),这清楚地表明自修复不是 GPT-3.5 的有效策略。另一方面,对于 GPT-4,有几个 n_p、n_fr 值,其自修复的通过率明显优于基线的通过率。例如,当 n_p=10,n_fr=3 时,通过率从 65% 增加到 70%,当 n_p=25,n_fr=1 时,通过率从 65% 增加至 71%。
GPT-4 的反馈改进了 GPT-3.5 自修复能力
接下来,本文进行了一个实验,在这个实验中,研究者评估了使用一个单独的、更强的模型来生成反馈的影响。这是为了检验一种假设:即模型无法内省和调试自己本身的代码,从而阻碍了自修复(尤其是 GPT-3.5)。
该实验的结果如图 5 所示(亮蓝线)。研究者观察到,就绝对性能而言,M_P=GPT-3.5,M_F=GPT-4 确实突破了性能障碍,变得比 GPT-3.5 的独立同分布采样效率略高。这表明反馈阶段至关重要,改进它可以缓解 GPT-3.5 自修复的瓶颈。
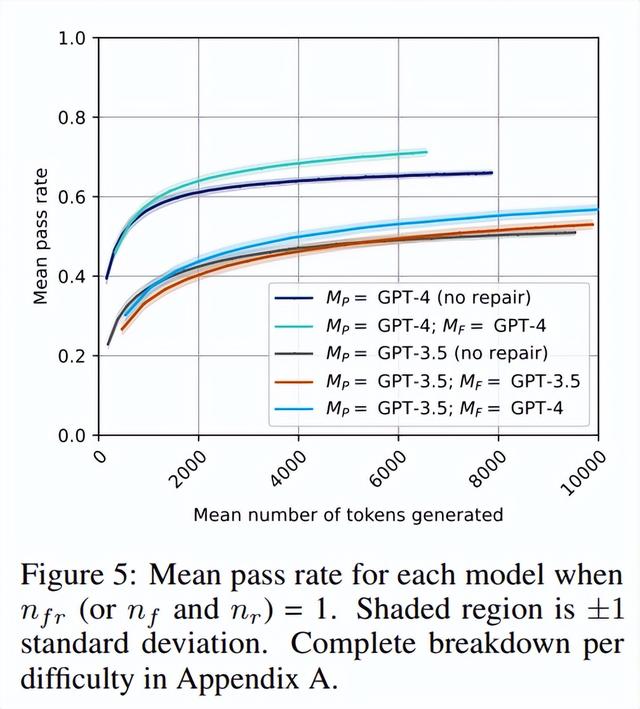
人类反馈显著提高了 GPT-4 自修复的成功率
在本文的最后一个实验中,研究者考虑了在使用 GPT-4 等更强的模型进行修复时使用专业人类程序员的反馈的效果。这项研究的目的不是直接比较人在循环中的方法与自修复方法,因为人在循环方法会带来更多的认知负担,而本文没有对此进行研究。相反,本文的目标是了解模型识别代码中错误的能力与人类相比如何,以及这如何影响自修复的下游性能。因此,该研究对人类反馈对自修复的影响进行了定性和定量分析。
结果总结在表 1 中。我们首先注意到,当我们用人类参与者的调试取代 GPT-4 自己的调试时,总体成功率提高了 1.57 倍以上。也许不足为奇的是,随着问题变得越来越困难,相对差异也会增加,这表明当任务(和代码)变得更加复杂时,GPT-4 产生准确和有用反馈的能力远远落后于我们的人类参与者。

此外,该研究还定性地分析了人类参与者提供的反馈与 GPT-4 提供的反馈之间的差异。
只有 2/80 个人贡献的反馈字符串包括伪代码或显式 Python;也就是说,获得的几乎所有人类反馈都是自然语言,偶尔穿插着单语句数学 / 代码表达式。
GPT-4 的反馈更可能明显不准确(32/80 与人类反馈的 7/80)。
GPT-4 更可能明确地建议小的变化(54/80 对 42/80;28/48 对 38/73,当看起来正确时),而我们的人类参与者显示出更大的趋势来建议高水平的变化(23/80 对 18/80,GPT-4;21/73 对 13/48,当看起来正确时)。
人类参与者有时会表达不确定性(7/80);GPT-4 没有(0/80)。
进一步的分析表明,表 1 中的结果不是由于人为因素造成的,例如参与者提供了模型简单复制的显式代码块。相反,性能的差异似乎是由更准确的反馈、在需要时建议对代码进行高级别、大规模更改的更大能力,以及参与者表达其不确定性的能力(而不是自信地给出潜在的不准确反馈)共同造成的。
相关文章








关于作者

猜你喜欢
成员 网址收录40404 企业收录2983 印章生成239177 电子证书1064 电子名片60 自媒体59671































