机器之心报道
编辑:张倩、陈萍
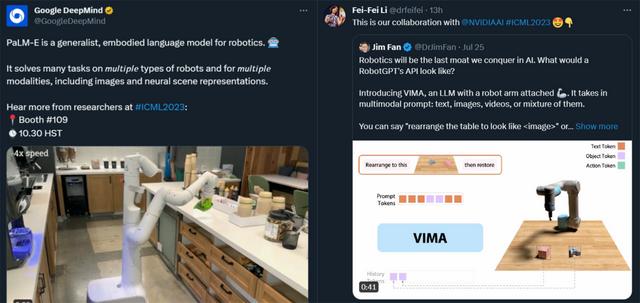
VIMA 是一个带有机械臂的 LLM ,它接受多模态 Prompt :文本、图像、视频或它们的混合。
是时候给大模型造个身体了,这是多家顶级研究机构在今年的 ICML 大会上向社区传递的一个重要信号。
在这次大会上,谷歌打造的 PaLM-E 和斯坦福大学李飞飞教授、英伟达高级研究科学家 Linxi "Jim" Fan(范麟熙,师从李飞飞)参与打造的 VIMA 机器人智能体悉数亮相,展示了具身智能领域的顶尖研究成果。
 论文地址:https://arxiv.org/pdf/2210.03094.pdf论文主页:https://vimalabs.github.io/Github 地址:https://github.com/vimalabs/VIMA
论文地址:https://arxiv.org/pdf/2210.03094.pdf论文主页:https://vimalabs.github.io/Github 地址:https://github.com/vimalabs/VIMAVIMA 智能体能像 GPT-4 一样接受 Prompt 输入,而且输入可以是多模态的(文本、图像、视频或它们的混合),然后输出动作,完成指定任务。
比如,我们可以要求它把积木按照图片所示摆好再还原:

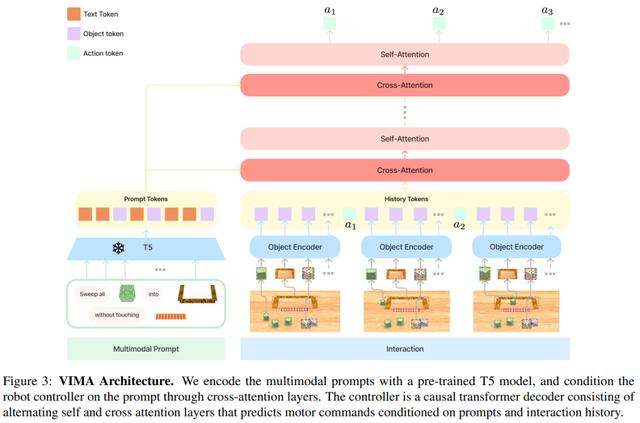
该研究引入了 VIMA(VisuoMotor Attention agent)来从多模态 prompt 中学习机器人操作。模型架构遵循编码器 - 解码器 transformer 设计,这种设计在 NLP 中被证明是有效的并且是可扩展的。
为了证明 VIMA 具有可扩展性,该研究训练了 7 个模型,参数范围从 2M 到 200M 不等。结果表明本文方法优于其他设计方案,比如图像 patch token、图像感知器和仅解码器条件化(decoder-only conditioning)。在四个零样本泛化级别和所有模型容量上,VIMA 都获得了一致的性能提升,有些情况下提升幅度很大,例如在相同的训练数据量下,VIMA 任务成功率提高到最多 2.9 倍,在数据量减少 10 倍的情况下,VIMA 性能提高到 2.7 倍。
为了确保可复现性并促进社区未来的研究工作,该研究还开源了仿真环境、训练数据集、算法代码和预训练模型的 checkpoint。
方法介绍
本文旨在构建一个机器人智能体,该智能体可以执行多模态 prompt 任务。本文提出的 VIMA 兼具多任务编码器 - 解码器架构以及以对象为中心的设计。VIMA 的架构图如下:
,
其中 d 是嵌入维度。为了将高层与输入的轨迹历史序列相连接,该研究还添加了残差连接。
研究中还用到了交叉注意力层,其具有三个优势:1)加强与 prompt 的连接;2)保持原始 prompt token 的完整和深入流动;3)更好的计算效率。VIMA 解码器由 L 个交替的交叉注意力层和自注意力层组成。最后,该研究遵循 Baker 等人的做法,将预测的动作 token 映射到机械臂离散姿态。
最后是训练。该研究采用行为克隆(behavioral cloning)训练模型。具体而言,对于一个包含 T 个步骤的轨迹,研究者需要优化函数
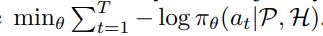
。
整个训练过程在一个离线数据集上进行,期间没有访问仿真器。为了使 VIMA 更具鲁棒性,该研究采用了对象增强技术,即随机注入 false-positive 检测输出。训练完成后,该研究选择模型 checkpoint 进行评估。
实验
实验旨在回答以下三个问题:
基于多模态 prompt,构建多任务的、基于 transformer 的机器人智能体的最佳方案是什么?本文方法在模型容量和数据大小方面的缩放特性是什么?不同的组件,如视觉 tokenizers、prompt 条件和 prompt 编码,如何影响机器人的性能?下图(上部)比较了不同模型大小(参数范围从 2M 到 200M)的性能,结果表明,VIMA 在性能上明显优于其他方法。尽管像 VIMA-Gato 和 VIMA-Flamingo 这样的模型在较大的模型大小下表现有所提升,但 VIMA 在所有模型大小上始终表现出优异的性能。
下图(底部)固定模型大小为 92M,比较了不同数据集大小(0.1%、1%、10% 和完整数据)带来的影响。结果表明,VIMA 具有极高的样本效率,可以在数据为原来 1/10 的情况下实现与其他方法相当的性能。
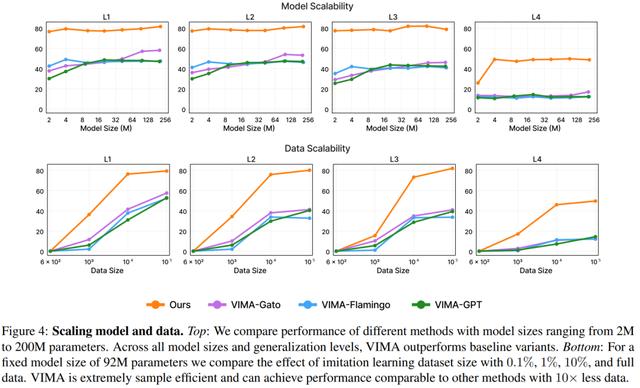
下图表明,交叉注意力在低参数状态和较难的泛化任务中特别有用。

相关文章








关于作者

猜你喜欢
成员 网址收录40406 企业收录2983 印章生成240943 电子证书1067 电子名片60 自媒体64348































