丰色 发自 凹非寺
量子位 | 公众号 QbitAI
大语言模型的数学能力到底怎么破?
一位数学本科生发现:
实际上,咱们只需像一年级小学生一样教它们“掰着手指头算”,就能让它立马变身数学小能手。
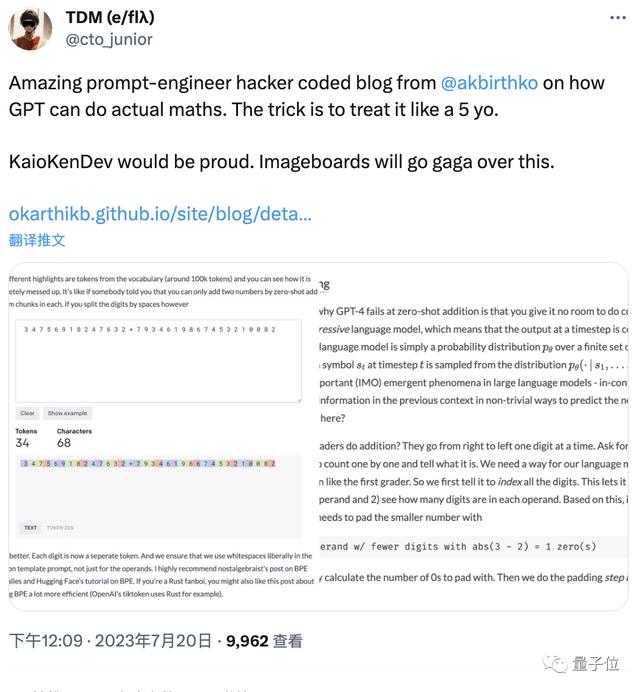
比如像“34756918247632 7934619867453210082”这样的大数加法,任你丢给哪个大模型,即使强如GPT-4,都算不明白。
但如果你按照他说的做,保证结果跟用计算器摁出来的一模一样。
(ps. 可以看到计算第二位的7 6 c时作者写错了,应该等于14,导致最终结果也错了,但这压根不影响,只要思想是对的,模型就能get到!)
对于第二个例子,步骤也一样,主要不同之处在于这次不需要补0——把人家当作小学生,就得把每种情况都讲明白。

所以说,大语言模型还是很聪明的,只要你会教,数学计算能力压根没问题。
为什么算不对?想必大家也会好奇,为什么要像小学生这样教它们才能做对这样的数学题呢?
作者分析,有两大原因:
一是模型在处理文本输入时会进行的tokenization操作,导致数字被多个组合在一起变成一个个token。
比如咱们今天算的这道,在GPT-4眼里它看到的其实是这样的:
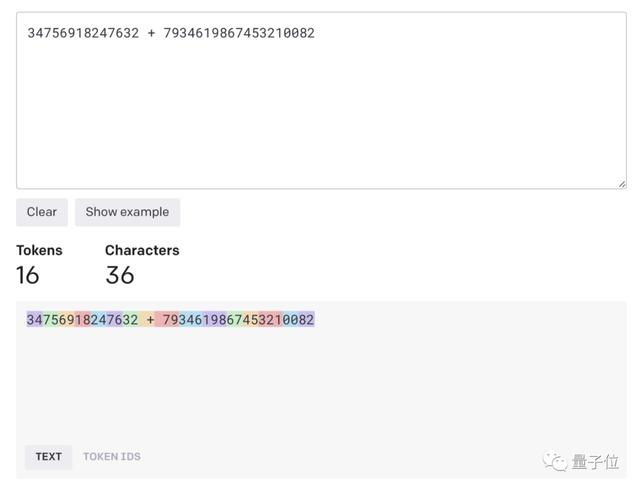
这也就是为什么我们需要用空格将每个数字隔开,GPT-4才不会进行拆分,才有算对的可能性。
当然,如果你仅仅是加了空格不用上面的方法教它,它也算不对。
这就引出第二个原因:没有给够它上下文学习的空间来进行计算。
GPT-4是一种自回归语言模型,这意味着它某个时间步的输出以所有先前的输出为条件,就像小学生做题一样,我们需要一种方法让我们的模型能够一步一步地检索到任何位置的数字。
因此,就需要给它设定如上的模版,让它“有迹可循”。
最后作者表示,语言模型不同于我们以前构建的任何类型的软件。所以需要一些特别的耐心。
那么,理解了以上这两个原因,大家是不是也就能更好地理解上面一系列如教小学生似的提示词操作了?
作者介绍本方法作者名叫Karthik Balaji,是滑铁卢大学数学本科生。
据个人主页介绍,他对大语言模型非常感兴趣,最近正在开始研究生成模型,尤其是扩散类型,并已经有一些小小的产出,大家感兴趣的可以去翻阅。

原文地址:
https://okarthikb.github.io/site/blog/detailed-prompting.html
— 完 —
量子位 QbitAI · 头条号签约
关注我们,第一时间获知前沿科技动态
相关文章









关于作者

猜你喜欢
成员 网址收录40400 企业收录2983 印章生成237730 电子证书1054 电子名片60 自媒体54483































