编辑:Aeneas 好困
【新智元导读】OpenAI再次开源,是科技大厂的「施舍」还是开源社区的「救赎」?就在刚刚,根据The Information的最新爆料,OpenAI即将发布一款全新的开源大语言模型。

虽然目前还不清楚,OpenAI是不是打算利用即将开源的模型,来抢占Vicuna或其他开源模型的市场份额。
但几乎可以肯定的是,新模型的能力大概率无法与GPT-4甚至GPT-3.5相竞争。
毕竟,270亿美元的估值也决定了,OpenAI最先进的模型将会被用于商业目的,尽管前两个版本的GPT都是开源的。
对此,OpenAI的发言人没有回应置评请求。

UC Berkeley的计算机教授Ion Stoica表示,现在的免费AI模型,在性能上已经「相当接近」谷歌和OpenAI的专有模型了,毫无疑问,大多数开发者最终都会选择免费模型。
一方面,开源模型可以让开发者使用自己的数据来解决特定的问题。
另一方面,像Vicuna这种模型的训练成本甚至可以低至几百美元,而且还不用向大厂支付昂贵的使用费。
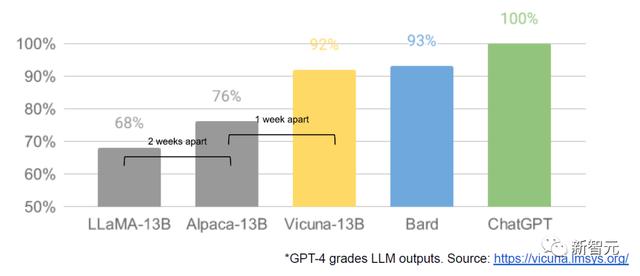
比如,现在许多开源平替是基于Meta的LLaMA构建的。
而其他模型使用的是名为Pile的大型公共数据集,由开源非营利组织EleutherAI整理。
EleutherAI之所以存在,是因为OpenAI的开放性意味着一群开发者能够逆向了解GPT-3是如何制作的,然后在空闲时间里创建自己的模型。

「我并不是一个开源的布道者,」Hugging Face的首席伦理科学家Margaret Mitchell说。「我能看到不开源的意义。」
大模型广泛使用的一个弊端,就是可能造成AI色情产品的泛滥。
Mitchell曾在谷歌工作,并创立了AI道德团队,她对于模型被滥用的风险十分了解。因此,她赞成Meta AI以有控制的方式发布模型。
同时,OpenAI也在关闭水龙头。GPT-4发布时,并没有公布架构(包括模型大小)、硬件、训练计算、数据集构建、训练方法等细节,理由是「鉴于像GPT-4这样的大规模模型的竞争格局和安全影响」。

这种限制反应了OpenAI心态上的变化。联合创始人兼首席科学家Ilya Sutskever表示,OpenAI过去的开放性是一个错误。
OpenAI的政策研究员Sandhini Agarwal说:「以前,如果某样东西是开源的,也许一小群修理工会关心。但现在,整个环境已经改变。开源真的可以加速发展,导致竞争。」
时间倒回三年前,如果OpenAI在公布GPT-3的细节时,就秉持着同样的原则,那就不会有EleutherAI的出现,也就不会有蓬勃的开源创新。
今天,EleutherAI在开源生态系统中发挥着举足轻重的作用。Pile被用来训练多个开源项目,包括Stability AI的StableLM。

但随着GPT-4、5、6被锁死,开源社区可能会再次被落在几家大公司后面。
他们会困在上一代模型中,如果想取得进步,只能闭门造车。
参考资料:
https://www.technologyreview.com/2023/05/12/1072950/open-source-ai-google-openai-eleuther-meta/
https://www.theinformation.com/articles/open-source-ai-is-gaining-on-google-and-chatgpt
相关文章





关于作者

猜你喜欢































