GPT-3 1750 亿参数,已经不是一般机构玩转的动,要分析GPT-3 参数构成,我们先分析 Transformer 中核心结构由encoder-decoder 构成,当前的LLMs模型基本是encoder 结构或者decoder 结构,而一个encoder 块,由Mutil-Head-Attention 和FFN 构成,然后在这中间,LayerNorm 穿插其中,下面主要从这三部分进行解析: 是模型的输入/输出维度(单词的嵌入embedding 维度)
表示模型的前馈神经网络FFN隐藏层维度;
表示注意力头的个数
表示注意的层数
1.Mutil-Head-Attention
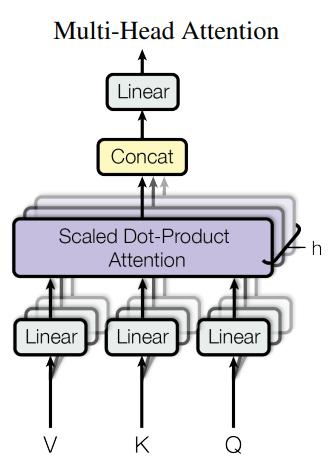
GPT-3 相关结构参数
从这个表中可以看出,在训练GPT-3规模上,参数规模越大,barch 越大,学习率越小。
相关文章








关于作者

猜你喜欢































