他们引入了一种非常有前途的注意力变体。

这类似于只拥有一个RNN,使用状态空间模型,线性注意力等,但与它们中的任何一个都不完全相同。

因此,它们的注意力变体可以让您使用更少的内存,并为大序列长度更快地生成令牌。

现在,设计一个比常规关注运行得更快的代币混合方案并不难。困难的是做到不损失准确性。
因此,这里令人惊讶的部分是,该方案显然提高了困惑度和下游任务性能。


GPT-4 通常也变得更加简洁。从资源使用的角度来看,这是有意义的,但从收入的角度来看(按令牌计费)并不是真的有意义。

由于我们不知道哪些模型更改导致了这些输出更改,因此从业务角度来看,这比从技术角度来看更有趣。
大多数情况下,这一发现强化了我的观点,即第三方AI API和组织特定的模型几乎是不相交的市场。就像,将数据传送到昂贵的第三方 API,该 API 可能会在次要版本更新后开始拒绝回答您的查询是......对于许多公司来说,这不是一个理想的产品。
但是这些 API 非常方便,非常适合对 AI 功能进行原型设计,并且如果您只有足够的数据用于一些上下文示例,则与您获得的精度一样高。如果您是想要回答各种不同查询的消费者,它们也很棒;实际上,我只是将所有内容输入 ChatGPT,而不是去寻找用于不同目的的专用应用程序。
基本上,这与具有重大商业价值的任务将由内部模型处理,而低价值查询的长尾将提供给第三方API或开源模型的世界观是一致的。
(编辑)另外,为了明确一点:我不是在这里试图给OpenAI投掷阴影。我认为这在很大程度上是通用 API 的内在限制——平均而言,你可以让它变得更好,但你不能同时避免所有可能的用例的回归。
模型会解释自己吗?自然语言解释的反事实可模拟性当您要求文本模型为其答案生成解释时,您希望它未来的响应与该解释一致。例如,假设它说培根三明治在某个区域很难买到,因为培根很难到达那里;如果你问培根是否很难到达那里并说“不”,那就不一致了。

他们构建了一个评估管道来衡量模型解释以这种方式不一致的频率。此管道:
生成其他语句,其真值应遵循解释,向模型询问这些陈述,然后检查模型所说的内容与人为分配的真值相对应的频率。
他们建议直接学习后验预测分布。他们通过假设世界如何运作的图形模型(Q)与贝叶斯图形模型(P)不同来做到这一点。

为了获得一个有用的目标,他们定义了一个变分上限,当我们对齐这两个图形模型所隐含的分布时,该上限被最小化。

它们只显示玩具问题的结果,显然在扩展方法时遇到了困难,但这是我长期以来在贝叶斯统计数据中看到的最简单、最有趣的想法之一。
1
这篇论文的主体只有六页,而且相当平易近人,所以如果你喜欢概率推理,我肯定会推荐它。
FlashAttention-2:通过更好的并行性和工作分区加快注意力新的FlashAttention,可获得50-73%的峰值FLOPS,而不是A25上的40-100%。由于它不会改变注意力的数学,这只是一个免费的胜利。
 NetHack中模仿学习的缩放定律
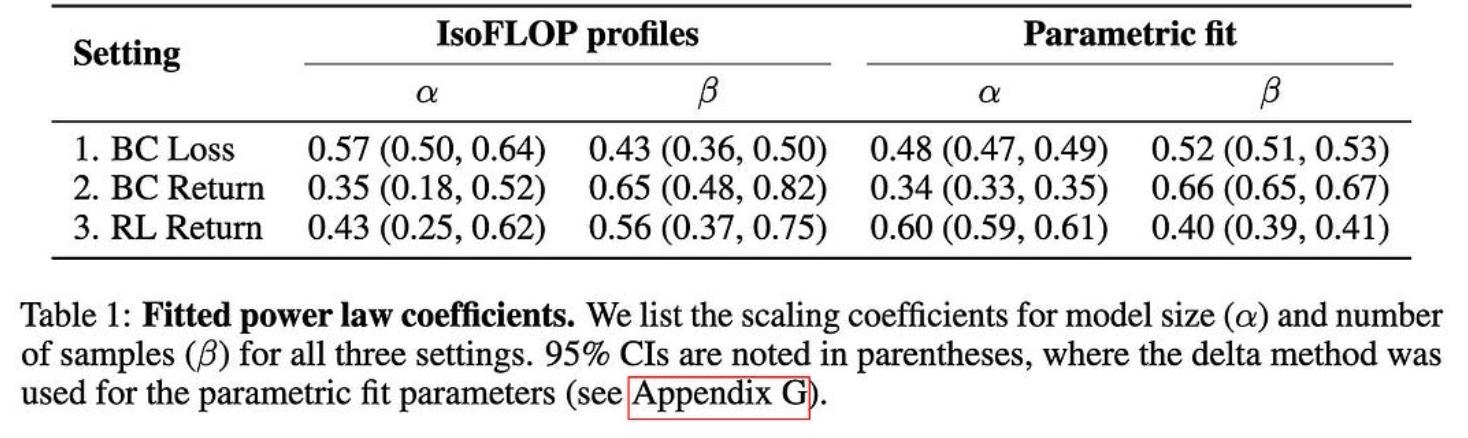
NetHack中模仿学习的缩放定律他们在NetHack上发现了行为克隆的明确幂律缩放关系。更有趣的是,他们使用的是LSTM而不是变压器。


 TinyTrain:极端边缘的深度神经网络训练
TinyTrain:极端边缘的深度神经网络训练它们通过以几种方式偏离典型的预训练-微调范式,使设备上的训练适用于资源受限的设备。

使用他们的方法选择特定于任务的通道比在元训练后进行通用通道修剪效果更好。

除了实用的设备级训练是一个巨大的隐私胜利之外,这也让我想知道我们是否应该在一般的预训练之后添加一个元训练步骤......
神经网络在图像分类中学到什么?频率快捷方式透视图像分类器通常通过频率内容模式学习识别类。例如,这可能会导致看起来不像猫的东西被归类为猫。

 使用图像字幕改进多模态数据集
使用图像字幕改进多模态数据集清理(图像、标题)数据集时的常见做法是,根据 CLIP 模型,当标题与图像对齐不符时,丢弃成对。但事实证明,这通常会丢弃标题不好的好图像。

一方面,Alpaca 数据集是由 OpenAI 的 text-davinci-003 生成的,这里的样本评级模型是 ChatGPT,评估模型是 GPT-4——所以可能涉及一些过度拟合。特别是,我希望 ChatGPT 和 GPT-4 在重叠的数据集上进行训练,因此这两个模型喜欢的响应可能是相关的。
但另一方面,使用较小的数据集比使用较大的数据集(对于某些指标)效果更好的基本结果仍然很有趣,并支持表面对齐假设。
相关文章









关于作者

猜你喜欢































