ChatGLM-6B 是一个开源的、支持中英双语的对话语言模型,基于 General Language Model (GLM) 架构,具有 62 亿参数。结合模型量化技术,用户可以在消费级的显卡上进行本地部署(INT4 量化级别下最低只需 6GB 显存)。 ChatGLM-6B 使用了和 ChatGPT 相似的技术,针对中文问答和对话进行了优化。经过约 1T 标识符的中英双语训练,辅以监督微调、反馈自助、人类反馈强化学习等技术的加持,62 亿参数的 ChatGLM-6B 已经能生成相当符合人类偏好的回答。 为了方便下游开发者针对自己的应用场景定制模型,同时实现了基于 P-Tuning v2 的高效参数微调方法 (使用指南) ,INT4 量化级别下最低只需 7GB 显存即可启动微调。
项目地址:https://github.com/THUDM/ChatGLM-6B
 ChatGLM-Efficient-Tuning
ChatGLM-Efficient-Tuning基于 PEFT 的高效 ChatGLM-6B 微调。
项目亮点:支持 freeze、ptuning、lora三种微调方法。
项目地址:https://github.com/hiyouga/ChatGLM-Efficient-Tuning/blob/main/README_zh.md
Chinese-LLaMA-Alpaca该项目是中文LLaMA模型和指令精调的Alpaca大模型。这些模型在原版LLaMA的基础上扩充了中文词表并使用了中文数据进行二次预训练,进一步提升了中文基础语义理解能力。同时,中文Alpaca模型进一步使用了中文指令数据进行精调,显著提升了模型对指令的理解和执行能力。
项目地址:https://github.com/ymcui/Chinese-LLaMA-Alpaca

解方程:

生成图片:

相关文章


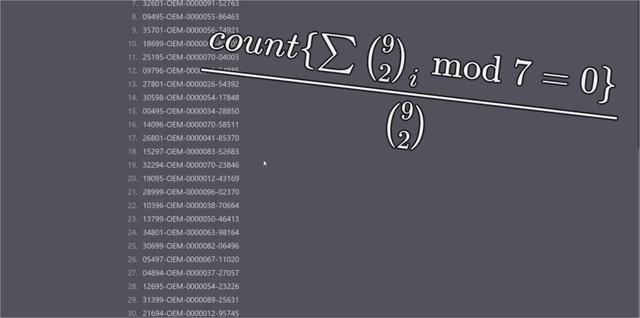





关于作者

猜你喜欢































