这是关于在实践中使用大型语言模型(LLMs)系列文章的第一篇。在这里,我将介绍LLMs并提出三个使用它们的级别。未来的文章将探讨LLMs的实际方面,例如如何使用OpenAI的公共API、Hugging Face Transformers Python库、如何微调LLMs以及如何从头构建LLMs
 什么是LLM?
什么是LLM?LLM 是 Large Language Model 的缩写,是人工智能和机器学习中的最新创新。这种强大的新型人工智能在2022年12月随着 ChatGPT 的发布而迅速传播开来。
对于那些生活在人工智能热潮和技术新闻周期之外的人来说,ChatGPT 是运行在名为 GPT-3 的 LLM 上的聊天界面(现在在撰写本文时已升级到 GPT-3.5 或 GPT-4)。
如果你使用过 ChatGPT,显然这不是来自 [AOL Instant Messenger](https://en.wikipedia.org/wiki/AIM_(software)) 或你的信用卡客服的传统聊天机器人。
这个聊天机器人感觉不同。
什么使得LLM“大”?当我听到“大型语言模型”这个术语时,我的第一个问题是,这与“常规”语言模型有何不同?
语言模型比大型语言模型更通用。就像所有正方形都是矩形,但并非所有矩形都是正方形一样。所有LLM都是语言模型,但不是所有语言模型都是LLM。
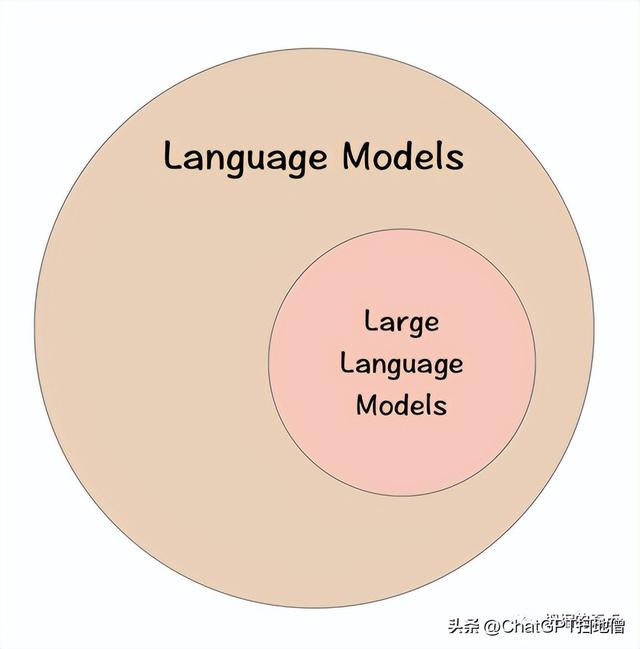
所以LLM是一种特殊的语言模型,但是什么使它们与众不同呢?
有2个关键属性区分LLMs与其他语言模型。一个是数量上的,另一个则是质量上的。
数量上,LLM的区别在于模型中使用的参数数量。目前的LLM大约有10-1000亿个参数[1]。质量上,当语言模型变得“大”时,会发生一些非凡的事情。它会展示出所谓的 emergent properties例如零-shot学习[1]。这些是当语言模型达到足够大的规模时,似乎突然出现的特性。零样本学习GPT-3(以及其他LLM)的主要创新在于它能够在各种情境下进行零样本学习[2]。这意味着ChatGPT可以执行一个任务,即使它没有被明确训练过。
尽管这对我们这些高度进化的人类来说可能不是什么大不了的事情,但是这种零样本学习能力与之前的机器学习范例形成了鲜明对比。
以前,为了获得良好的性能,模型需要明确地在它所要完成的任务上进行明确的训练。这可能需要1k-1M个预标记的训练示例。
例如,如果你想让计算机进行语言翻译、情感分析和识别语法错误。每个任务都需要一个专门的模型,它需要在大量标记示例的基础上进行训练。然而,现在,LLM可以在没有明确训练的情况下完成所有这些任务。
LLM如何工作?训练大多数最先进的LLM所使用的核心任务是单词预测。换句话说,给定一序列单词,下一个单词的概率分布是什么?
例如,给定序列Listen to your ____,最有可能的下一个单词可能是:heart,gut,body,parents,grandma等。这可能看起来像下面显示的概率分布。
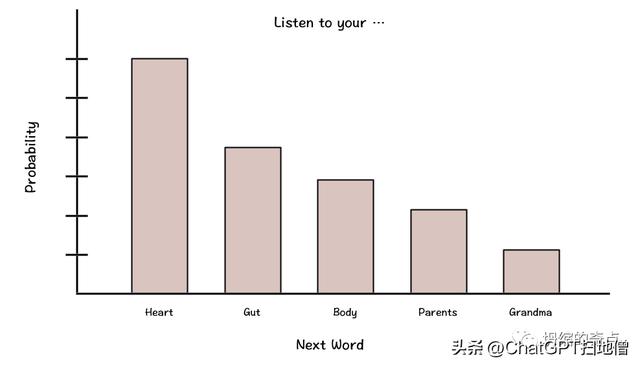
有趣的是,这是许多(非大型)语言模型过去被训练的方式(例如GPT-1)[3]。然而,由于某种原因,当语言模型超过一定大小(例如~10B个参数)时,这些(新生的)能力,例如零-shot学习,开始出现[1]。
尽管目前还没有明确的答案,解释为什么会发生这种情况(只有推测),但明显LLM是一种强大的技术,具有无数的潜在用例。
使用LLM的3个层次现在我们来看看如何在实践中使用这种强大的技术。虽然有无数的LLM用例,但在这里,我将它们按所需的技术知识和计算资源排序为3个层次。我们从最容易使用的开始。
一级:提示工程使用LLM的第一级别是“提示工程”,我将其定义为“任何使用LLM的开箱即用方式”,即不更改任何模型参数。虽然许多技术倾向的个人似乎对提示工程的想法不屑一顾,但这是实际中使用LLM(在技术和经济上)最可访问的方法。
有两种主要的提示工程方式: 简单方式 和 较不简单方式。
简单方式:ChatGPT(或其他方便的LLM UI) - 这种方法的关键好处是方便。像ChatGPT这样的工具提供了一种直观,免费且无代码的使用LLM的方法(没有比这更容易的方法了)。
然而,方便通常是有代价的。在这种情况下,这种方法有两个主要缺点。第一个是缺乏功能。例如,ChatGPT不容易使用户自定义模型输入参数(例如温度或最大响应长度),这些值调节LLM输出。第二,与ChatGPT UI的交互不能轻松地自动化,因此无法应用于大规模使用情况。
虽然这些缺点可能是某些用例的杀手级应用,但如果我们将提示工程向前推进一步,这两个缺点都可以得到改善。
较不简单方式:直接与LLM交互 - 我们可以通过编程接口直接与LLM进行交互来克服ChatGPT的一些缺点。这可以通过公共API(例如OpenAI的API)或在本地运行LLM(使用像Transformers这样的库)来实现。
虽然这种提示工程方式不太方便(因为它需要编程知识和潜在的API成本),但它提供了一种可定制,灵活和可扩展的使用LLM的方法。本系列文章将讨论付费和免费的方法来进行此类提示工程。
尽管提示工程(如此定义)可以处理大多数潜在的LLM应用程序,但依赖通用模型可能会导致特定用例的次优性能。对于这些情况,我们可以进入使用LLM的下一个级别。
等级 2:模型微调使用 LLM 的第二个等级是模型微调,我定义为对现有 LLM 进行微调以用于特定用例,通过改变至少一个(内部)模型参数,即权重和偏差。在此类别中,我还将在此处将迁移学习即使用现有 LLM 的某些部分来开发另一个模型。
微调通常包括两个步骤。步骤 1:获得预先训练的 LLM。步骤 2:基于给定的特定任务更新模型参数(通常是数千个)高质量标记的示例。
模型参数是定义 LLM 对输入文本的内部表示的。因此,通过针对特定任务调整这些参数,内部表示变得针对微调任务进行了优化(或者至少是这样的想法)。
这是一种强大的模型开发方法,因为相对较少的示例和计算资源可以产生出色的模型性能。
然而,缺点是它需要比提示工程更多的技术专业知识和计算资源。在未来的一篇文章中,我将尝试通过审查微调技术并共享示例 Python 代码来缓解这种缺点。
虽然提示工程和模型微调可能可以处理 LLM 应用程序的 99%,但有时必须走得更远。
等级 3:构建自己的 LLM在实践中使用 LLM 的第三种最终方法是构建自己的。在模型参数方面,这是您从头开始制定所有模型参数的地方。
LLM 主要是其训练数据的产物。因此,对于某些应用程序,可能需要策划自定义的高质量文本语料库进行模型训练,例如医学研究语料库,用于开发临床应用程序。
这种方法最大的优点是您可以完全自定义 LLM 以适用于您的特定用例。这是终极的灵活性。但是,通常情况下,灵活性的代价是方便性。
由于LLM 性能的关键是规模,因此从头开始构建 LLM 需要巨大的计算资源和技术专业知识。换句话说,这不会是一个个人周末项目,而是一个完整的团队工作数月甚至数年,预算达到 7-8F。
尽管如此,在我未来文章中,我希望探讨从头开始开发 LLM 的流行技术。
最后让我们来总结一下:
虽然LLM现在被吹得足够大,但它们是AI领域的一项强大创新。在这里,我提供了有关LLMs是什么以及如何在实践中使用它们的入门指南。日后我希望写一些文章提供初学者指南,帮助大家启动下一个LLM用例。
资源链接:「个人博客」
社交:「推特」|「微博」| 「领英」|「油管」
之后我会出一些AI相关的具体视频教程,目前还未找到合适的平台托管,敬请期待。关注我,我会第一时间通知到家。
在我的号内的文章大部分是免费阅读的(除非有实际成本支出),如果您觉得对您有帮助,可以给我赞赏一下以表支持。
引用[1] 大型语言模型调查。 arXiv:2303.18223 [cs.CL]
[2] GPT-3论文。 arXiv:2005.14165 [cs.CL]
[3] Radford,A.,& Narasimhan,K。(2018)。通过生成式预训练改善语言理解。 (GPT-1论文)
相关文章









关于作者

猜你喜欢































