编辑:编辑部
【新智元导读】这个开源工具,居然能用GPT-4代替人类去标注数据,效率比人类高了100倍,但成本只有1/7。大模型满天飞的时代,AI行业最缺的是什么?毫无疑问一定是算(xian)力(ka)。
老黄作为AI掘金者唯一的「铲子供应商」,早已赚得盆满钵满。

除了GPU,还有什么是训练一个高效的大模型必不可少且同样难以获取的资源?
高质量的数据。OpenAI正是借助基于人类标注的数据,才一举从众多大模型企业中脱颖而出,让ChatGPT成为了大模型竞争中阶段性的胜利者。
但同时,OpenAI也因为使用非洲廉价的人工进行数据标注,被各种媒体口诛笔伐。

表1:Autolabel标注的数据集列表
使用了以下LLM:

表2:用于评估的LLM提供者与模型列表
本研究在三个标准上对LLM和人工标注进行评估:
首先是标签质量,即生成的标签与真实标签之间的一致性;
其次是周转时间,即以秒为单位时,生成标签所花费的时间;
最后是以分为单位,生成每个标签的成本。
对于每个数据集,研究人员都将其拆分为种子集和测试集两部分。
种子集包含200个示例,是从训练分区中随机采样构建的,用于置信度校准和一些少量的提示任务中。
测试集包含2000个示例,采用了与种子集相同的构建方法,用于运行评估和报告所有基准测试的结果。
在人工标注方面,研究团队从常用的数据标注第三方平台聘请了数据标注员,每个数据集都配有多个数据标注员。
此过程分为三个阶段:
研究人员为数据标注员提供了标注指南,要求他们对种子集进行标注。
然后对标注过的种子集进行评估,为数据标注员提供该数据集的基准真相作为参考,并要求他们检查自己的错误。
随后,为数据标注员解释说明他们遇到的标签指南问题,最后对测试集进行标注。
结果标签质量
标签质量衡量的是生成的标签(由人类或LLM标注者生成)与数据集中提供的基准真相的吻合程度。
对于SQuAD数据集,研究人员用生成标签与基准真相之间的F1分数来衡量一致性,F1是问题解答的常用指标。
对于SQuAD以外的数据集,研究人员用生成标签与基准真相之间的精确匹配来衡量一致性。
下表汇总了各个数据集标签质量的结果:
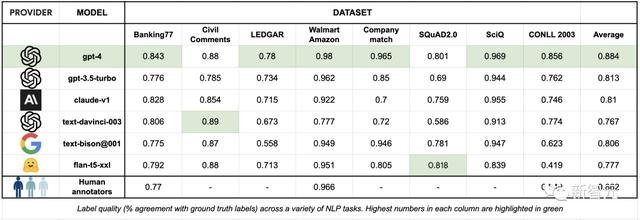
表4:同一数据集上gpt-3.5-turbo和gpt-4的标签质量与完成率
在校准步骤中,研究人员利用估计置信度来了解标签质量和完成率之间的权衡。
即研究人员为LLM确定了一个工作点,并拒绝所有低于该工作点阈值的标签。
例如,上图显示,在95%的质量阈值下,我们可以使用GPT-4标注约77%的数据集。
添加这一步的原因是token级日志概率在校准方面的效果不佳,如GPT-4技术报告中所强调的那样:
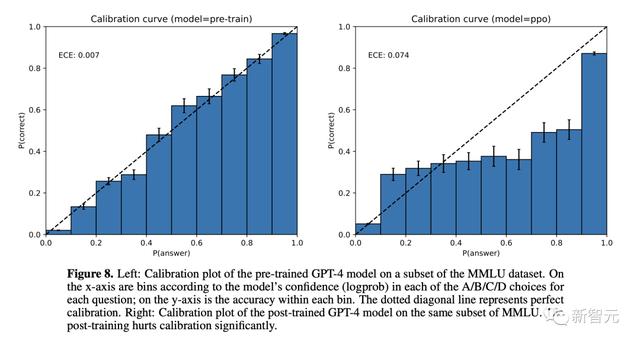
GPT-4模型的校准图:比较预训练和后RLHF版本的置信度和准确性
使用上述置信度估算方法,并将置信度阈值设定为95%的标签质量(相比之下,人类标注者的标签质量为86%),得到了以下数据集和LLM的完成率:
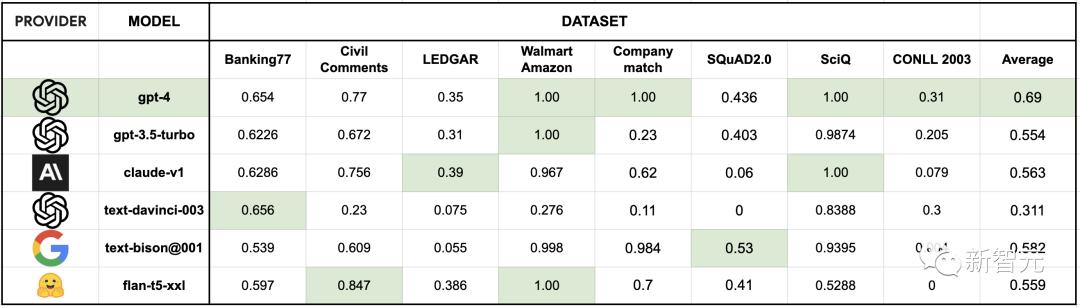
95%与基准真相一致的完成率
相比之下,人类标注者与基准真相的一致性为86.6%。
从上图可以看到在所有数据集中,GPT-4的平均完成率最高,在8个数据集中,有3个数据集的标注质量超过了这一质量阈值。
而其他多个模型(如text-bison@001、gpt-3.5-turbo、claude-v1和flan-t5-xxl)也实现了很好的性能:
平均至少成功自动标注了50%的数据,但价格却只有GPT-4 API成本的1/10以下。
未来更新的方向
在接下来的几个月中,开发者承诺将向Autolabel添加大量新功能:
支持更多LLM进行数据标注。
支持更多标注任务,例如总结等。
支持更多的输入数据类型和更高的LLM输出稳健性。
让用户能够试验多个LLM和不同提示的工作流程。
参考资料:
相关文章









关于作者

猜你喜欢
成员 网址收录40394 企业收录2981 印章生成234673 电子证书1035 电子名片60 自媒体46889































