编辑:桃子
【新智元导读】GPT-4参数规模扩大1000倍,如何实现?OpenAI科学家最新演讲,从第一性原理出发,探讨了2023年大模型发展现状。
「GPT-4即将超越拐点,并且性能实现显著跳跃」。
这是OpenAI科学家Hyung Won Chung在近来的演讲中,对大模型参数规模扩大能力飙升得出的论断。
在他看来,我们所有人需要改变观点。LLM实则蕴藏着巨大的潜力,只有参数量达到一定规模时,能力就会浮现。

在近一个小时的演讲中,Hyung Won Chung从三个方面分享了自己过去4年从业以来对「扩展」的思考。
都有哪些亮点?
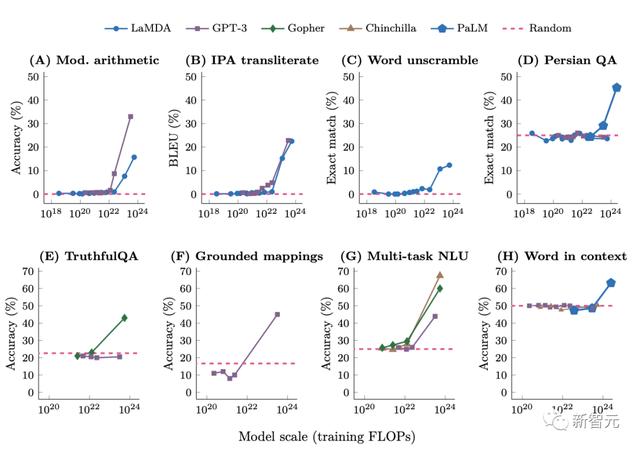
参数规模越大,LLM势必「涌现」
Hyung Won Chung强调的核心点是,「持续学习,更新认知,采取以“规模”为先的视角非常重要」。
因为只有在模型达到一定规模时,某些能力才会浮现。
多项研究表明,小模型无法解决一些任务,有时候还得需要依靠随机猜测,但当模型达到一定规模时,就一下子解决了,甚至有时表现非常出色。
因此,人们将这种现象称之为「涌现」。
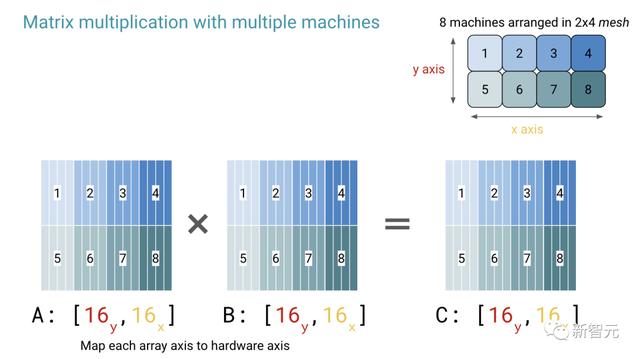
所以,扩大Transformer的规模就是,让很多很多机器高效地进行矩阵乘法。
尽管RLHF有着一些弊端,比如奖励模型容易受到「奖励黑客」的影响,还有开放的研究问题需要解决,但是我们还是要继续研究RLHF。
因为,最大似然法归纳偏差太大;学习目标函数(奖励模型)以释放缩放中的归纳偏差,是一种不同的范式,有很大的改进空间。

另外,RLHF是一种有原则的算法 ,需要继续研究,直到成功为止。
总之,在Hyung Won Chung认为,最大似然估计目标函数,是实现GPT-4 10000倍规模的瓶颈。
使用富有表达力的神经网络学习目标函数,将是下一个更加可扩展的范式。随着计算成本的指数级下降,可扩展的方法终将胜出。

「不管怎么说,从第一原理出发理解核心思想是唯一可扩展的方法」。
参考资料:
https://twitter.com/xiaohuggg/status/1711714757802369456?s=20
相关文章








关于作者

猜你喜欢































