机器之心专栏
机器之心编辑部
MiniGPT-v2 将大语言模型作为视觉语言多任务学习的统一接口。
几个月前,来自 KAUST(沙特阿卜杜拉国王科技大学)的几位研究者提出了一个名为 MiniGPT-4 的项目,它能提供类似 GPT-4 的图像理解与对话能力。
例如 MiniGPT-4 能够回答下图中出现的景象:「图片描述的是生长在冰冻湖上的一株仙人掌。仙人掌周围有巨大的冰晶,远处还有白雪皑皑的山峰……」假如你接着询问这种景象能够发生在现实世界中吗?MiniGPT-4 给出的回答是这张图片在现实世界中并不常见,并给出了原因。

论文地址:https://arxiv.org/pdf/2310.09478.pdf
论文主页:https://minigpt-v2.github.io/
Demo: https://minigpt-v2.github.io/
具体而言,MiniGPT-v2 可以作为一个统一的接口来更好地处理各种视觉 - 语言任务。同时,本文建议在训练模型时对不同的任务使用唯一的识别符号,这些识别符号有利于模型轻松的区分每个任务指令,并提高每个任务模型的学习效率。
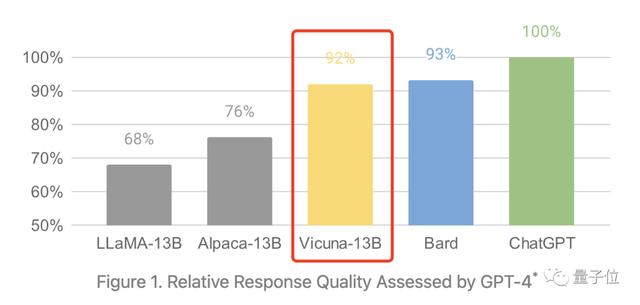
为了评估 MiniGPT-v2 模型的性能,研究者对不同的视觉 - 语言任务进行了广泛的实验。结果表明,与之前的视觉 - 语言通用模型(例如 MiniGPT-4、InstructBLIP、 LLaVA 和 Shikra)相比,MiniGPT-v2 在各种基准上实现了 SOTA 或相当的性能。例如 MiniGPT-v2 在 VSR 基准上比 MiniGPT-4 高出 21.3%,比 InstructBLIP 高出 11.3%,比 LLaVA 高出 11.7%。

模型的空间感知也变得更强,可以直接问模型谁出现在图片的左面,中间和右面:

阶段 1:预训练。本文对弱标记数据集给出了高采样率,以获得更多样化的知识。
阶段 2:多任务训练。为了提高 MiniGPT-v2 在每个任务上的性能,现阶段只专注于使用细粒度数据集来训练模型。研究者从 stage-1 中排除 GRIT-20M 和 LAION 等弱监督数据集,并根据每个任务的频率更新数据采样比。该策略使本文模型能够优先考虑高质量对齐的图像文本数据,从而在各种任务中获得卓越的性能。
阶段 3:多模态指令调优。随后,本文专注于使用更多多模态指令数据集来微调模型,并增强其作为聊天机器人的对话能力。
最后,官方也提供了 Demo 供读者测试,例如,下图中左边我们上传一张照片,然后选择 [Detection] ,接着输入「red balloon」,模型就能识别出图中红色的气球:

相关文章







关于作者

猜你喜欢































