GPT-4模型的缓存回复:真相与疑虑
引言
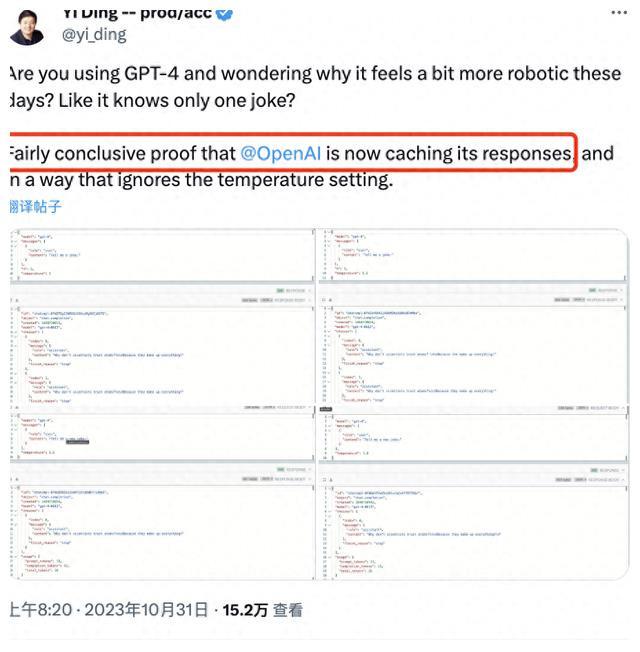
在人工智能领域,GPT-4模型引起了广泛的讨论和关注。一些网友开始质疑GPT-4在回答问题时是否采用了缓存历史回复的策略。他们提出了一个有趣的例子,即使将模型的temperature值调高,模型仍然不时地重复相同的回答。在本文中,我们将深入探讨这一问题,以及temperature值和top_p值对模型行为的潜在影响。
这种权衡需要综合考虑,以满足不同场景下的需求。
值得一提的是,类似的现象也在本地模型上被观察到。这涉及前缀匹配命中,即模型可能会更倾向于生成与先前问题相似的回答,而不是完全重新生成。这进一步强化了缓存回复的可能性。
缓存机制分析
那么,GPT-4模型可能如何实施缓存回复机制呢?这一问题涉及到大规模模型可能采用的缓存聊天信息方式,以及聚类操作的具体执行。

一些研究表明,类似的现象在处理笑话等特定情境时并不罕见,这可能与模型的工作方式和语言生成的本质有关。
为了更准确地判断是否模型使用了缓存,可以考虑测量延迟时间。如果模型在回答问题时存在明显的延迟,那么这可能是因为它正在查找历史记录或执行其他缓存相关操作。这种方法可以提供更具体的证据,以确定缓存回复是否在模型的工作中起到了作用。
总结与观点
综上所述,关于GPT-4模型是否使用缓存回复的问题引发了广泛的讨论。

相关文章









关于作者

猜你喜欢
成员 网址收录40400 企业收录2981 印章生成237656 电子证书1054 电子名片60 自媒体53244































