编辑:编辑部
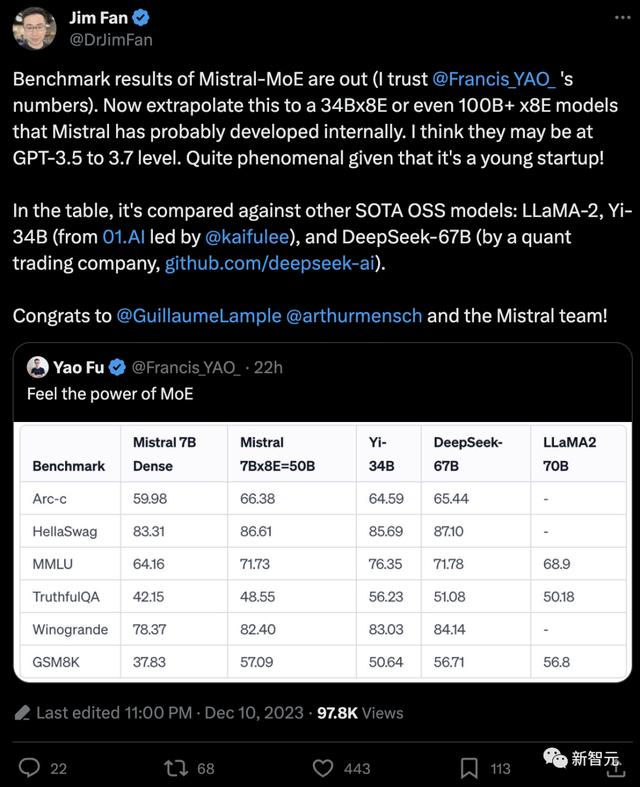
【新智元导读】上周末,Mistral甩出的开源MoE大模型,震惊了整个开源社区。MoE究竟是什么?它又是如何提升了大语言模型的性能?Mistral上周末丢出的磁力链接震惊了开源圈子,这个7B×8E的开源MoE大模型性能已经到达了LLaMA2 70B的级别!
而根据Jim Fan猜测,如果Mistral内部训练了34B×8E或者甚至100B ×8E级别的模型,那他们的能力很有可能已经无限接近GPT-4了。
而在之前对于GPT-4结构的曝料中,大部分的信息也指向GPT-4很可能是由8个或者是16个MoE构成。

项目地址:https://github.com/XueFuzhao/OpenMoE
数据来源- 一半来自The RedPajama,另一半来自The Stack Dedup
- 为提升模型的推理能力,采用了大量的编程相关数据
模型架构- OpenMoE模型基于「ST-MoE」,但采用了decoder-only架构。
其它设计- 采用umT5 tokenizer
- 使用RoPE技术
- 采用SwiGLU激活函数
- 设定2000 token的上下文长度
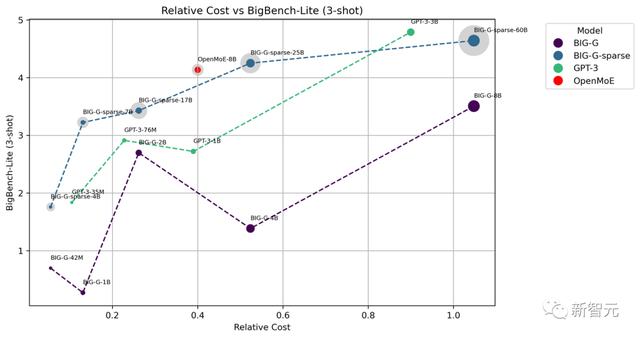
BigBench评估团队在BigBench-Lite上进行了少样本测试,其中包括与BIG-G、BIG-G-Sparse以及GPT-3的对比。
通过计算每个词元激活的参数数量和训练词元的数量来大致估计相对成本。图中每个点的大小代表了相应词元激活的参数数量。特别需要指出的是,浅灰色的点表示MoE模型的总参数量。
对此,Jim Fan也表示,MoE并不新鲜,它只是没有得到那么多关注而已......
比如,谷歌很早之前就开源了基于T5的MoE模型——Switch Transformer。
 面临的挑战和机遇MoE基础设施建设
面临的挑战和机遇MoE基础设施建设由于MoE拥有大量可训练参数,理想的软件环境应该支持灵活组合的专家级、张量级、流水线级和数据并行,无论是节点内还是节点间。
此外,如果能支持简单快速的激活卸载和权重量化,从而减轻MoE权重的内存占用,就更好了。
MoE指令微调FLAN-MoE研究提出:尽管将MoE的性能通过特定任务的微调转移到下游任务上存在挑战,但指令微调却能有效地与MoE模型协调一致。这展示了基于MoE的语言模型巨大的潜力。
MoE 评估MoE模型的归纳偏置(Inductive bias)可能在困惑度(perplexity)之外还有其他效果,就像其他自适应模型(如Universal Transformer和AdaTape)那样。
硬件挑战值得一提的是,GPU在跨节点通信方面面临挑战,因为每个节点通常只能配备有限数量的GPU。这使得专家并行中,通信成为瓶颈。
幸运的是,NVIDIA最近推出了DGX GH200,将256个NVIDIA Grace Hopper Superchips集成到一个单一GPU中,很大程度上解决了通信带宽问题,为开源领域的MoE模型的训练和部署提供了帮助。
参考资料:
相关文章








关于作者

猜你喜欢































