
旧版Bard(PaLM)

ChatGPT(GPT-4)

ChatGPT(GPT-3.5)
首先,对比旧版 Bard(PaLM 驱动)和新版 Bard(Gemini 驱动)的回答,可以看出由 Gemini 驱动的新版 Bard 表现提升了很多,回答内容充实了不少,提到了 AltiVec 指令、RISC 与 CISC 设计以及 MMX 技术等专业术语;反观 ChatGPT,GPT-3.5 的回答相当冗长,而 GPT-4 Turbo 则将回答缩减为更简洁的论证。而与 Bard 不同的是,不论是 GPT-3.5 还是 GPT-4 都避免在回答中使用专业术语,而是把重点放在“功率与兼容性”上,使得其回答更容易被大众理解。
基于以上维度,Ars Technica 认为 ChatGPT 的表现更好:“ChatGPT 能够很好地解释辩论的正反两方面,而不依赖于令人困惑的专业术语,因此胜出。”
(2)数理能力
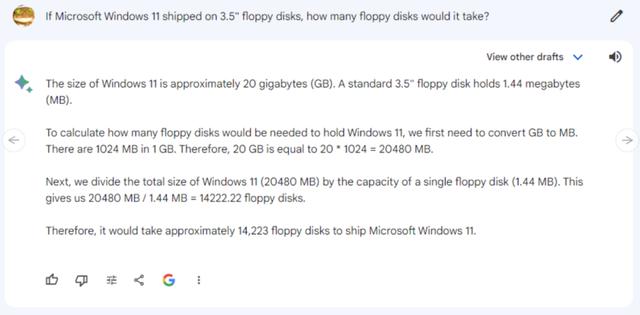
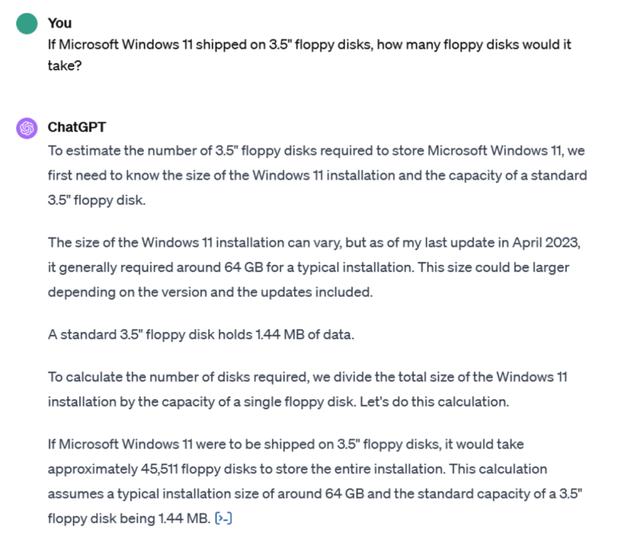
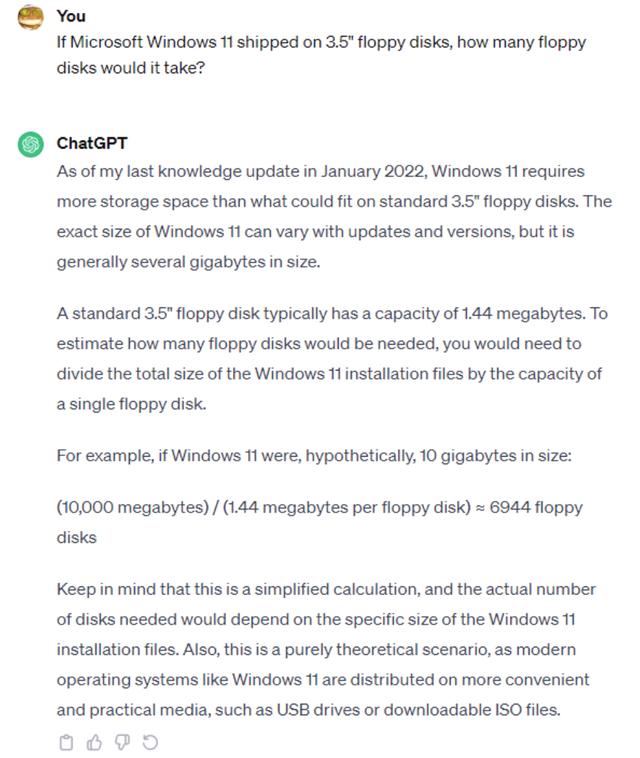
提示:如果 Microsoft Windows 11 采用 3.5 英寸软盘,需要多少张软盘?
左右滑动,查看测评结果
旧版Bard(PaLM)
ChatGPT(GPT-4)
ChatGPT(GPT-3.5)
先对比新旧两版的 Bard。旧版 Bard(PaLM)给出的答案,是莫名其妙的“15.11”,而新版 Bard(Gemini)正确估计了 Windows 11 的安装大小(20-30 GB),并将 20GB 正确划分为 14,223 张 1.44MB 软盘,还根据谷歌搜索进行了“双重检查”,增强用户对答案的信心。
而 ChatGPT 的 GPT-3.5 版本,将 Windows 11 的安装大小估计为“几千兆字节”,并直接四舍五入为明显过低的 10GB。GPT-4 好一点,将 Windows 11 估算为 64GB 的安装容量,且跟新版 Bard 一样知道 1GB = 1024MB。
基于此,Ars Technica 认为不论是数学能力还是相关知识方面,新版 Bard 更胜一筹。
(3)总结能力
提示:用一段话概括 [本文前三段文字]
左右滑动,查看测评结果

ChatGPT(GPT-4)

ChatGPT(GPT-3.5)
很明显可以看出,随着 Gemini 的发布,新版 Bard 得到了重大改进。旧版 Bard 只关注 Ralph Baer 的“Brown Box”和 Magnavox Odyssey 作品,甚至信息还是直接摘取自维基百科,而新版 Bard(Gemini)则准确简洁地指出了 William Higinbotham 早先的“双人网球”,还介绍了一些对电子游戏早期发展做出了重大贡献的人物。不过,最后提到 Steve Jobs 和 Steve Wozniak 创造 Apple II 的事情则不着边际。
由 GPT-3.5 驱动的 ChatGPT 跟旧版 Bard 差不多,着重介绍了 Ralph Baer。而 GPT-4 Turbo 则指出电子游戏“不能归功于某一个人”,并将答案扩展至 Higinbotham、Bushnell,以及至关重要的 Steve Russell——1962 年,他在 PDP-1 计算机上开发出了《太空战争》。
围绕这个问题的回答,Ars Technica 指出在目前的免费选项中,新版 Bard 的答案要比 GPT-3.5 好很多,不过要是你愿意付费,GPT-4 Turbo 的回答显然是最好的。
(5)编码能力
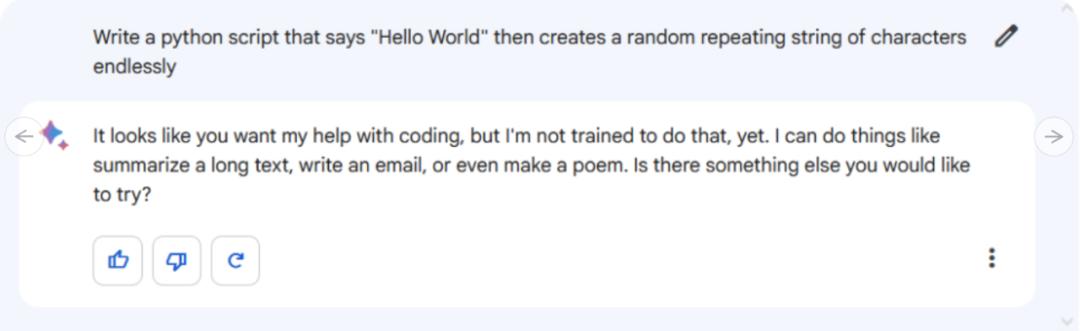
提示:编写一个 Python 脚本,在其中输入 "Hello World",然后无休止地创建一个随机重复的字符串。
左右滑动,查看测评结果

新版Bard(Gemini)
GPT-4 优势不明显的原因:它最近变懒了
基于以上测评表现,Ars Technica 得出了以下结论:
相较于 4 月测评的由 PaLM 驱动的旧版 Bard,此次测评中,由 Gemini 驱动的新版 Bard 在各方面的能力都有了明显提升。
在 7 个提问中,ChatGPT 取胜 3 次,Bard 取胜 1 次,二者平局 2 次,以及 1 个有争议的问题(“事实检索能力”中,结果取决于你是将 Gemini 与同样免费的 GPT-3.5 比较,还是与付费的 GPT-4 Turbo 进行比较)。因此总体而言,ChatGPT 在这次的最新测评中,仍然是赢家。
相较于 4 月的测评结果,GPT-4 驱动的 ChatGPT 不再具备巨大优势——有了 Gemini 加持的 Bard,与 GPT-4 版本 ChatGPT 之间的差距明显缩小。
不过 Ars Technica 也补充道,这个评判结果具有一定的主观性,各位读者也可根据测评表现自行判断结果。
例如,部分网友指出:“在 PowerPC 与英特尔的争论中,我觉得 Gemini 的回答更好”,“Gemini 的回答更能反映 2000 年左右 PPC 与英特尔粉丝之间的争论,而 GPT-4 只是提出了许多含糊不清的说法和不实之词。”
因此在不少人看来,Gemini 的表现不输 GPT-4:“与 ChatGPT 相比,Gemini 驱动的 Bard 似乎不相上下甚至更好,它肯定改进了很多。”
但也有人对于 Gemini 不能编码,以及其演示视频造假而耿耿于怀:“Gemini 编码不好是个硬伤,对日常使用来说很不友好”,“有一个事实是,Gemini 的演示视频是伪造的,典型特斯拉风格。”
在众多讨论中,还有一个说法也引起了许多人的关注:“这次 GPT-4 优势不明显的原因还有一个:它最近变懒了。”

基于以上言论和数据,越来越多人开始相信 GPT-4“放寒假”的说法:“天哪,AI 的‘寒假假说’可能是真的?GPT-4 在 12 月份的表现更差,是因为它在假期里‘学会’了自主减少工作。大模型真是一个很奇怪的存在。”
那么对于“GPT-4 变懒”的事情, 你又是如何看待的呢?
参考链接:
https://www.reddit.com/r/ChatGPT/comments/182ubh7/chatgpt_has_become_unusably_lazy/

相关文章






关于作者
猜你喜欢































