以下文章来源于机器之心 ,作者机器之心
3 月 21 日,在机器之心举办的 ChatGPT 及大模型技术大会上,哈尔滨工业大学计算学部长聘教授、博士生导师车万翔发表主题演讲《ChatGPT 浅析》,在演讲中,他回答了 ChatGPT 究竟解决了什么科学问题,是如何解决该问题的,以及未来还有哪些亟待解决的问题。
 自然语言处理
自然语言处理ChatGPT 属于自然语言处理研究方向的一个最新进展。首先什么是自然语言处理呢?自然语言指的是人类语言,特指文本符号,而非语音信号。而自然语言处理就是让用计算机来理解和生成自然语言的各种理论和方法。当然传统的、或者说很早以前的自然语言处理,等价于自然语言理解,因为当时自然语言生成太难了,只能用一些模板的方法来生成。但是现在我们看到,随着 AIGC 等这些技术的进步,生成技术成为自然语言处理的一个主流方向,像 ChatGPT 本身就是一种生成模型,这也是自然语言处理的最新进展。其实让机器理解自然语言还是件很难的事,因为从人类的智能角度来讲,自然语言处理属于认知智能,需要更强的抽象和推理能力。

自然语言处理面临很多难点,我们举例来说,如下图所示,在这次对话中,内容包含很多「意思」,不同的「意思」代表不同的含义,这种情况属于典型的歧义性问题。除了歧义性之外,自然语言处理面临的难点还包括抽象性、组合性、进化性等。在抽象性这个问题中,我们以汽车这个词举例,它背后有非常丰富的含义,我们一说到汽车这两个字就会有很多联想;组合性也是一样,无论哪种语言,它都是由一些基本符号构成的,这些基本符号可以组合成无穷无尽的语义。
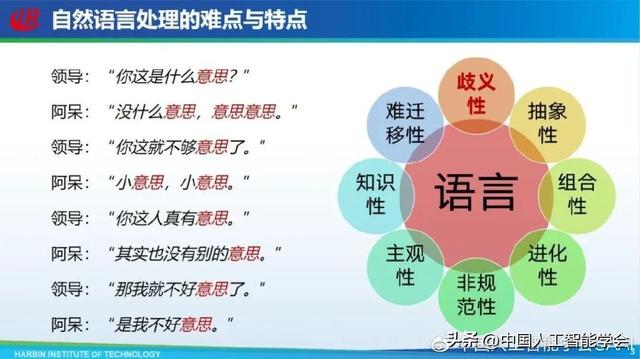
正是因为这些难点,使得自然语言处理成为制约人工智能取得更大突破和更广泛应用的瓶颈,包括多位图灵奖得主在内的众多学者,很早之前他们就提出自然语言处理将是人工智能未来发展的重要方向,因而自然语言处理也被誉为「人工智能皇冠上的明珠」。我们发现近期人工智能很多进展都离不开自然语言处理,比如著名的 Transformer,它最早是用于解决机器翻译问题,到后来的 BERT 以及 ChatGPT,其实这一波又一波的浪潮都是和自然语言处理相关。所以把自然语言处理称为人工智能皇冠上的明珠也不过誉。

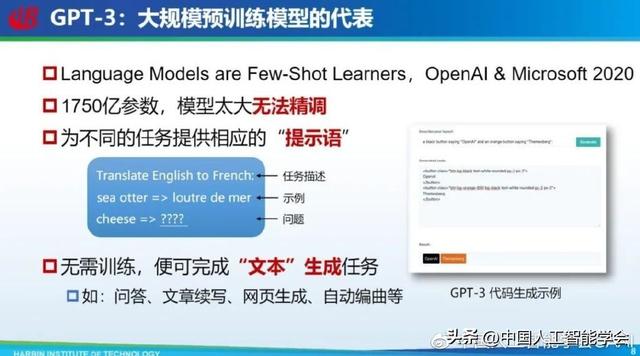
在预训练模型阶段比较有代表性的研究是 GPT-3,它是 OpenAI 和微软在 2020 年发布的大模型,参数量达 1750 亿,以当时的视角来看,研究者认为这个模型太大没办法精调,所以「提示语」方法出现了。所谓提示语,即直接给出任务描述,可以让模型自动补全这个任务,这个补全过程就是在完成任务,如果再给出一些示例,模型性能可能会更好,这种也叫做情境学习。采用这种方式的一个好处是模型无需针对某一个任务再次训练,就可以完成不同文本生成任务。当然,这个文本生成任务是加引号的,因为它不仅能回答问题、文章续写,还可以完成生成网页,甚至生成代码等范文本任务。
ChatGPT 的发展历程也非常励志,第一代 GPT 就是 OpenAI 提出来的,甚至比 BERT 提出的还要早,GPT 开启了自然语言处理预训练时代。但是大家记住更多的是 BERT,因为当时 OpenAI 还是个小公司,大家还没太关注它的工作,同时 BERT 是 Google 提出来的,从自然语言理解的角度来讲,BERT 参数量大,具有双向理解方式,所以它的效果比 GPT 好。但是 OpenAI 并没有模仿这种方式做双向,它继续沿着 GPT 单向结构进行,后来就产生了 GPT-2,学术界用的也比较多,GPT-3 的出现,风靡了一阵,不过之后大家觉得这模型浪费钱,效果还不怎么好,去年 3 月 InstructGPT 出现了,吸引了很多国际学术界的关注,但国内关注的相对较少。直到去年 11 月底 ChatGPT 的发布,一炮打响,引起更多关注,以及今年 3 月份发布的 GPT-4,它不光处理文本,甚至融合了多模态。OpenAI 整个历程比较励志,它一直沿着 GPT 这条路线在走,最后还走通了,有人说 OpenAI 比较犟,比较执拗,但确实它有自己的信心和理想,走成了。

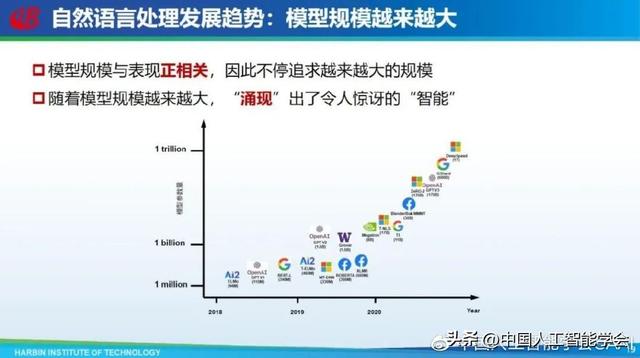
第二,模型规模越来越大。很多证据表明,随着模型规模越来越大,会出现智能的涌现。我们很难做到把模型变小,让它具有很好的通用性。当然具体行业应用还是需要小的模型,但要实现通用人工智能,可能还是需要模型足够大。
但是怎么弥补呢?可以用增强的方法,图灵奖得主 Yann LeCun 发表过一篇文章就总结过这种方法,包括加上搜索引擎、知识库、外挂工具等,这些都可以叫增强。除此之外,目前也有很多工作使用搜索引擎来弥补现在 ChatGPT 的不足。

还有就是怎么对大模型进行评价。现在有很多评价模型的数据集发布,但这个数据集一旦发布就有可能泄漏,有些人会把数据集用到训练数据里,怎么解决这种问题,也是需要考虑的。三是解释包括涌现现象、CoT 等出现的机理。

当然,只从文本入手没法解决这个问题,还是要往多模态等发展。结合更多的模态,通往真正的 AGI。之前有学者把机器能够利用的数据范围划为五个,从最简单的小规模文本一直到和人类社会互动这五个范围。之前很长一段时间大家都只用文本端,现阶段等于是跨过中间的两个(多模态和具身),直接到了和人类社会的互动,因为现在 ChatGPT 就是和人类社会交互。在交互过程中,人也在教机器怎么说语言,怎么理解语言。但跨过中间两段不代表就真的包含这两段,还是要把这两段补齐。现在 GPT-4 补齐了多模态,Google、微软等也在做具身方面的研究。
 总结和展望
总结和展望最后是总结和展望,自然语言处理是人工智能皇冠上的明珠,ChatGPT 是继数据库和搜索引擎之后的全新一代知识表示和调用方式,模型同质化和规模化的趋势不可逆转。要想真正实现 AGI,需要结合多模态和具身智能。

以上就是我报告的全部内容,谢谢大家!
相关文章









关于作者

猜你喜欢
成员 网址收录40400 企业收录2981 印章生成237605 电子证书1052 电子名片60 自媒体51891































