在日常生活让 AI 帮忙完成一些任务,已经不是新鲜事。智能音箱里的 AI,可以告诉你“明天天气怎么样”;翻译软件里的 AI,能准确翻译一大段话甚至一篇文章;写作 AI 则会输出作文。
但它们都只能干一件事,翻译的 AI 写不了作文,问答的 AI 也不会翻译。它们更像一个个工具,而不是一个智能体。一个真正智能的 AI 应该是什么样的?它应该是通用的,既可以对付问答、写文章,也能搞定翻译。
最近在硅谷大火的 GPT-3,就是这么一个 AI。问答、写文、翻译都不在话下,还能写代码、算公式、做表格、画图标。
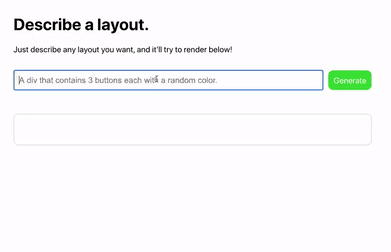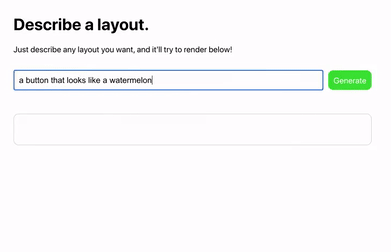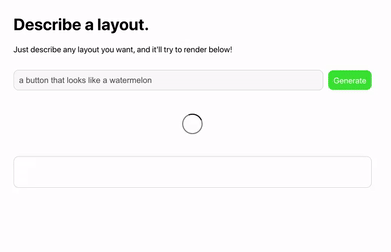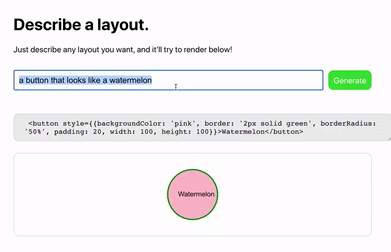
本质上,GPT-3 其实是一个语言模型。所谓语言模型,就是让机器理解并预测人类语言的一项技术。如果说以前的语言模型是专才,那 GPT-3 就是一个通才,而且样样都干得还不错。
当我们仔细回顾和梳理它的诞生故事会发现,AI 领域的一个明显趋势正在浮出水面:要训练一个有颠覆性进步的模型,最终比拼的是数据量和算力规模,这意味着这个行业的门槛越来越高,最终可能导致 AI 技术的竞争变成少数“烧得起钱”的大公司之间的游戏。
预训练筑起数量门槛GPT-3的故事要从2018年说起。
2018 年初,艾伦人工智能研究所和华盛顿大学的研究人员提出了 ELMo(Embedding from Language Models)模型。这之前的模型,无法理解上下文,不能根据语境去判断一个多义词的正确含义,ELMo 第一次解决了这个问题。
在训练 ELMo 模型过程中,研究人员采用了一种关键的方法——预训练。通常,训练一个模型需要大量经过人工标注的数据。而在标注数据很少的情况下,训练出来的模型精度很差。
预训练则摆脱了对标注数据的依赖,用大量没有标注的语料去训练(即无监督学习),得到一套模型参数,再把这套模型参数应用于具体任务上。这种模式训练出来的语言模型被证明了,在自然语言处理(以下简称 NLP)任务中能实现很好的效果。可以说,预训练这种方式的成功,开创了自然语言研究的新范式。
2018 年 6 月,在 ELMo 基础上,OpenAI 提出了 GPT。GPT 全称 Generative Pre-training,字面意思是“生成式预训练”。
GPT 同样基于预训练模式,但和 ELMo 不同的是,它加入了第二阶段训练:精调(Fine-tuning,又称“微调”),开创了“预训练 精调”的先河。所谓精调,即在第一阶段训练好的模型基础上,使用少量标注语料,针对具体的 NLP 任务来做调整(即有监督学习)。
除了开创“预训练 精调”模式,GPT 还在特征提取器上采用更加强大的 Transformer。所谓特征提取器,就是用来提取语义特征的。Google 在 2017 年推出的 Transformer,比 ELMo 所用的特征提取器 RNN,在综合效果和速度方面有优势。并且,数据量越大,越能凸显出 Transformer 的优点。
GPT 在预训练阶段设计了 12 层 Transformer(层数越多规模越大),并且使用“单向语言模型”作为训练任务。上文说到,ELMo 模型能理解上下文,上文和下文的信息都被充分利用。而 GPT 和之后的迭代版本,坚持用单向语言模型,只使用上文信息。
GPT 的设计思路奠定了此后迭代的基础,但由于它的规模和效果没有很出众,风头很快被 2018 年底亮相的 BERT 所盖过。
 堆人、堆算力规模
堆人、堆算力规模从 GPT-1 的“平平无奇”到 GPT-3 的突破,充分体现了什么叫“大力出奇迹”。
首先看人力。初代 GPT 的论文只有四位作者,GPT-2 论文有六位作者。到了 GPT-3,论文作者猛增为 31 位。

并且,这 31 位作者分工明确,有人负责训练模型,有人负责收集和过滤数据,有人负责实施具体的自然语言任务,有人负责开发更快的 GPU 内核,跟公司不同部门间合作没啥区别。

再看看算力。从初代 GPT 到 GPT-3,算法模型基本没有变化,都是基于 Transformer 做预训练,但训练数据量和模型规模十倍、千倍地增长。相应地,所需要的算力也越来越夸张。初代 GPT 在 8 个 GPU 上训练一个月就行,而 GPT-2 需要在 256 个 Google Cloud TPU v3 上训练(256 美元每小时),训练时长未知。
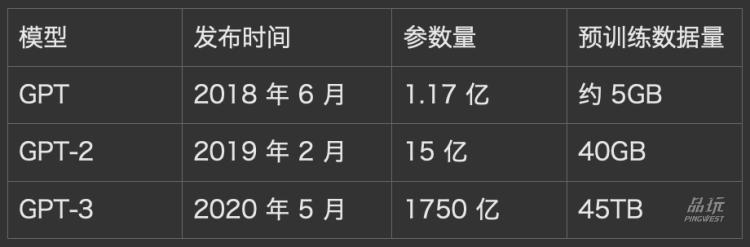
到 GPT-3,算力费用已经是千万级别。据 GPT-3 的论文,所有模型都是在高带宽集群中的英伟达 V100 GPU 上训练的,训练费用预估为 1200 万美元。
甚至,由于成本过于地高,研究者在发现了一个 Bug 的情况下,没有选择再去训练一次,而是把涉及的部分排除在论文之外。
显然,没有强大的算力(其实相当于财力)支持,GPT-3 根本不可能被训练出来。那么,OpenAI 的算力支持源自何处?这要说回到一笔投资。2019 年 7 月,微软向 OpenAI 注资 10 亿美元。双方协定,微软给 OpenAI 提供算力支持,而 OpenAI 则将部分 AI 知识产权授权给微软进行商业化。

2020 年 5 月,微软推出了一台专门为 OpenAI 设计的超级计算机。它托管在 Azure 上,包含超过 28.5 万个处理器内核和 1 万块 GPU,每个显卡服务器的连接速度为 400 Gbps/s。它的性能在超级计算机排名中,可以排到前五。
最后,再来说说 OpenAI 这家机构。埃隆・马斯克和原 Y Combinator 总裁山姆·奥特曼主导成立于 2015 年的 OpenAI,原本是一个纯粹的非营利 AI 研究组织,但经过一次转型和架构调整,加上引入微软投资,现在已经成为混合了营利与非营利性质的企业。
一直以来,OpenAI 的目标都是创建“通用人工智能”(Artificial General Intelligence,简称AGI),就好像文章开头所说的,AGI 是一个可以胜任所有智力任务的 AI。
打造 AGI 的路径有两种,一种是开发出更加强大的算法,另一种是在现有算法基础上进行规模化。OpenAI 就是第二种路径的信仰者。2019 年,OpenAI 核算了自 2012 年来所有模型所用的计算量,包括 AlexNet 和 AlphaGo,发现最大规模 AI 模型所需算力,已经增长了 30 万倍,每 3.4 个月翻一番。而摩尔定律指出,芯片性能翻倍周期是 18–24 个月。这就意味着,最大规模 AI 模型对算力需求的增长,远超芯片性能的提升。
毫无疑问,算力已经成为 NLP 研究甚至 AI 研究的壁垒。知乎用户“李渔”说得好:GPT-3 仅仅只是一个开始,随着这类工作的常态化开展,类似 OpenAI 的机构很可能形成系统性的 AI 技术垄断。
相关文章









关于作者

猜你喜欢
成员 网址收录40408 企业收录2984 印章生成248981 电子证书1108 电子名片64 自媒体77267































