
图:使用ZeRO-100B的600亿参数模型的超线性可扩展性和训练吞吐量。
ZeRO消除了数据和模型并行训练中的内存冗余,同时保持了低通信量和高计算粒度,从而能够按设备数量成比例地缩放模型参数。
研究人员通过分析内存需求和通讯量,表明ZeRO可以使用现有的硬件扩展到超过1万亿个参数。
1 内存优化
基本的数据并行化不会减少每个设备的内存,如果要训练超过14亿参数的模型,32GB内存(GPU)是不足的。
论文还讨论了如何对优化器状态、梯度进行巧妙分区,来减少GPU节点之间通信的需求,从而实现内存优化。但是即便不使用模型并行,也要在1个GPU上运行1个模型副本。
ZeRO-100B可以在128个GPU上训练多达130亿参数的模型,而无需模型并行,平均每个GPU的吞吐量超过40 TFlops。
相比之下,如果没有ZeRO,则最大的仅数据并行的可训练模型就只有14亿参数,每个GPU的吞吐量小于20 TFlops。
在英伟达 V100和128个节点的DGX-2集群中添加16路模型并行处理,可以训练大约2,000亿个参数。
从16路模型并行开始,可以运行15.4倍的大型模型,而不会真正造成性能损失,而在运行16路模型并行和64路数据并行(1024个GPU)时,性能仅比峰值性能低30%。

图:随着我们增加模型大小、数据集大小和用于训练的计算吞吐量,语言建模性能会平稳提高。为了获得最佳性能,必须同时放大所有三个因素。当没有其他两个瓶颈时,经验性能与每个因素都有幂律关系。
损失(L)和模型参数数量(N)存在以下关系:

将模型参数转换为吞吐量(C,单位petaFLOP/s-days),我们得到:
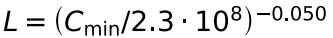

GPT-3能很好地拟合这个等式:
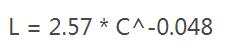
图:深度学习应用程序的性能改善与训练该模型的计算负载有关(以千兆浮点运算为单位)。
参考资料:

相关文章









关于作者

猜你喜欢
成员 网址收录40408 企业收录2984 印章生成248981 电子证书1108 电子名片64 自媒体77267































