关注我们
(本文阅读时间:20分钟)
GPT 是把 Transformer 的解码器提出来,在没有标注的大数据下完成一个语言模型,作为预训练模型,然后在子任务上做微调获得不同任务的分类器。这个逻辑和我们的计算机视觉的套路是一样的。这个模型叫 GPT-1。
GPT-2 收集了更大的数据集,生成了更大的模型这就算 GPT-2,证明了当数据库越大,模型越大,能力就有可能越强,但是需求投入多少钱可以得到预期效果,大家都不确定,所以 GTP-2 没有在市场上获得特别强的反响。
GPT 团队认为自己的算法没有问题,思路没有问题,逻辑没有问题,唯一有问题的就是没有菠菜罐头,所以 GPT 团队找了金主买了菠菜罐头,终于大力水手升级为暴力水手,从大力出奇迹转变为暴力出奇迹,惊艳的 GPT-3 终于诞生了,那么这么暴力升级有多恐怖呢?GPT-3 数据和模型都比 GTP-2 大了100倍!
微软MVP实验室研究员

从结果来看,除了阅读理解领域还算可以,其他三个领域都不怎么理想,但是别忘了,GPT-2 是在无监督的模型下和这些有监督的模型做的 PK,得到这样的结果已经是非常不错了,并且从图表可以看到一个关键信息,总体来讲,只要模型越大,预测的结果就越好。
具体来说,GPT-2 采用了更大规模的语料库进行预训练,并增加了更多的参数。GPT-2 的模型架构与 GPT-1 相同,都是基于 Transformer 结构的编码器模型。但 GPT-2 的模型规模是 GPT-1 的4倍,拥有1.5亿个参数。同时,GPT-2 还引入了一些新的技术,如动态掩码、自适应的词向量权重、多层次的表示等,以提高模型的性能和泛化能力。
GPT-2 的预训练任务仍然是语言建模,即在大规模语料库上训练模型,以预测下一个单词的概率分布。但由于模型规模和预训练效果的提升,GPT-2 在生成各种文本任务方面表现出色,如文本生成、机器翻译、对话生成等。
总体来说,GPT-2 的核心思想是在 GPT-1 的基础上进一步提高模型规模和预训练效果,采用更大规模的语料库进行预训练,引入一些新的技术以提高模型的性能和泛化能力,仍然以语言建模为预训练任务,在生成各种文本任务方面表现出色。
论文出自《Language Models are Unsupervised Multitask Learners》
GPT-3
关键词:少样本、上下文学习
GPT-3 的名字叫:Language Models are Few-Shot Learners,中文解释就是语言模型是少样本学习器。是不是觉得这个团队很有意思:从有监督微调到零样本训练到现在的少样本训练,科学就是这样,需要对自己的结果做客观的认知,对不足的地方就要调整,不能为了面子不顾事实,而是要客观面对自己的经验教训。
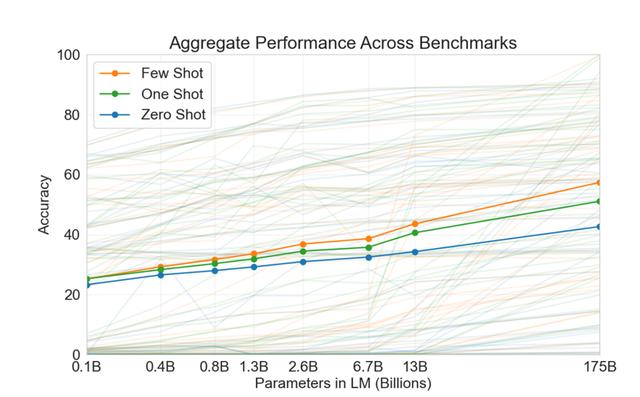
GPT-3 团队用这张图来解释他们为啥要回到有样本的思路,从这个图可以观察到,少样本,单样本和零样本在模型的规模增大后,精度是有明确的差异的。
但是基于 GPT-1 和 GPT-2 我们会得到一些概念:一旦有了样本,我们就是微调工作,得到一个新的模型,但是模型的效果和模型的大小成正比,那么在一个超大的预模型下做微调获得新的模型成本肯定非常昂贵。
但同时 GPT-3 团队认为预训练模型使用的样本可能会影响下游子任务的质量。举例来说,如果你的子任务输出结果非常好,也许是你的微调的数据和预训练模型中的刚好很接近,所以不能说微调出来的模型好,就说你的预训练的模型一定泛化的很好。
所以 GPT-3 又开创性的提出了一个设计:在作用到下游任务上的时候不做任何参数调整和梯度更新,也就是说子任务不要产生新的模型。GPT-3 团队用下面的图描述了零样本、单样本和少样本来处理任务。这图里面提出了一个概念:prompt。预训练模型来通过这个提示理解你要做什么任务。

这个图还是很直观的说明了三种样本的概念,但是要记得 GPT-3 是不生成新模型的,所以这些样本是不做训练的,只做预测。GPT-3 要求模型在做推理的时候能够通过注意力机制去处理比较长的信息,然后从这些信息中抽取出有价值的信息,这就是上下文学习。
要实现这样聪明厉害的模型,从 GPT-1 和 GPT-2 的经验来看,那这个模型需要非常大,因此他的数据集也需要非常大才行。
GPT-2 团队从 Reddit 搞来了海量的优质内容,那 GPT-3 团队想获得更大的样本要从哪里来呢?开创性的行为再次出现。GPT-3 团队把目光转到了 Commom Crawl。这名字起得真的是直白,这群人利用其自己的网络爬虫收集了十亿级别的网页数据,并使任何人都可以免费访。Common Crawl 的创始人 Gilad Elbaz 说:“据我所知,互联网是当今最多知识的聚集体,如果能拥有如此巨大的数据,你就可以在这座数据矿藏上面建立你想要的新产品。” 这个矿大到什么程度呢?从2008年开始,这个爬虫就是按年在互联网上进行采集,你可以认为从2008年开始,Common Crawl 每年对互联网做了一次快照。这些快照存储在 Amazon S3 上,任何人都可以免费下载。
但是 Commom Crawl 既然是互联网的快照,那么内容的质量也会和互联网一样参差不齐,GPT-3 团队对 Common Crawl 的处理方式很巧妙:用 GPT-2 的内容为参照,从 Common Crawl 中提取有价值的信息,然后又对提取出来的数据集做了去重。到此为止,就是传说中 GPT-3 把整个互联网的数据做了训练。
下面就是 GPT-3 包含的样本情况:
数据集
tokens数量
训练占比
Epochs elapsed when
training for 300B tokens
过滤后的Common Crawl
4100亿
60%
0.44
WebText2(Reddit)
190亿
22%
2.9
Books1
120亿
8%
1.9
Books2
550亿
8%
0.43
Wikipedia
30
3%
3.4
然后在这样的样本规模下,GPT-3 训练出了下面这样模型:
Model Name
参数
层
每一层大小
多头注意力头
头维度大小
训练的时候小批量大小
学习率
GPT-3 Small
1.25亿
12
768
12
64
50万
6.0 × 10-4
GPT-3 Medium
3.5亿
24
1024
16
64
50万
3.0 × 10-4
GPT-3 Large
7.6亿
24
1536
16
96
50万
2.5 × 10-4
GPT-3 XL
13亿
24
2048
24
128
100万
2.0 × 10-4
GPT-3 2.7B
27亿
32
2560
32
80
100万
1.6 × 10-4
GPT-3 6.7B
67亿
32
4096
32
18
200万
1.2 × 10-4
GPT-3 13B
130亿
40
5140
40
128
200万
1.0 × 10-4
GPT-3 175B or “GPT-3
1750亿
96
12288
96
128
320万
0.6 × 10-4
看到这张表,是不是有一种自己在优衣库选衣服的感觉,没有最大,只有更大的尺寸在等着你。很多人都感叹,GPT 重新定位了 small。
那么这么大的模型,要用什么设备来训练呢?GPT-3 秀了下自己的钞能力:All models were trained on V100 GPU’s on part of a high-bandwidth cluster provided by Microsoft。这就是传说中微软老大用 Bing 团队的算力给 GPT-3 团队输血的来源吧。反正 GPT-3 团队的意思就是虽然我把我语言模型说的模模糊糊,但就算你完全理解了我的逻辑,但你是无论如何都得不到这样高的算力来复现 GPT-3 了。你们就乖乖的用我的模型算了。
基于这样的钞能力,最后 GPT-3 团队得到一个结论:模型越来越大,但过拟合并没有严重,模型越大,学习率下减。
论文出自《Language Models are Few-Shot Learners 》
链接:https://arxiv.org/pdf/2005.14165.pdf
总结
最后我们总结一下 GPT 的发展三阶段:
GPT-1:提出了一个开创性的想法,并做了实践。
GPT-2:提出有钱就可以做的很好。
GPT-3:证明了如果有很多很多钱,就可以做的很惊艳。
微软最有价值专家(MVP)

微软最有价值专家是微软公司授予第三方技术专业人士的一个全球奖项。30年来,世界各地的技术社区领导者,因其在线上和线下的技术社区中分享专业知识和经验而获得此奖项。
MVP是经过严格挑选的专家团队,他们代表着技术最精湛且最具智慧的人,是对社区投入极大的热情并乐于助人的专家。MVP致力于通过演讲、论坛问答、创建网站、撰写博客、分享视频、开源项目、组织会议等方式来帮助他人,并最大程度地帮助微软技术社区用户使用 Microsoft 技术。
更多详情请登录官方网站:
https://mvp.microsoft.com/zh-cn
谢谢你读完了本文
喜欢可转发到朋友圈
也欢迎随时来后台跟我聊天
输入“@D姐” 呼唤我哦!
*未经授权请勿私自转载此文章及图片
如有转载需求,可后台私信或留言,谢谢
相关文章






关于作者

猜你喜欢































