作者:qizailiu,腾讯 IEG 算法研究员
昨天 OpenAI 发布最新里程碑 AI 语言模型 GPT-4,GPT-4 是一个大型多模态模型(接受图像和文本输入,输出为文本),目前虽然在许多现实世界场景中的能力不如人类,但在各种专业和学术基准上表现出人类水平。
写在前面本文主要参考 OpenAI 关于 GPT4 的官方 Blog,目前各公众号关于 GPT4 的内容基本来自官方 Blog、技术报告和官方视频内容。相关内容传送门:
官方 Blog 地址:GPT-4
官方 ChatGPT Plus 体验地址:https://chat.openai.com/auth/login?next=/chat
官方技术报告地址:https://cdn.openai.com/papers/gpt-4.pdf
官方视频案例地址:https://www.youtube.com/live/outcGtbnMuQ?feature=share
1、GPT4 简介OpenAI 发布最新里程碑 GPT-4,GPT-4 是一个大型多模态模型(接受图像和文本输入,输出为文本),目前虽然在许多现实世界场景中的能力不如人类,但在各种专业和学术基准上表现出人类水平。例如它通过模拟律师考试,分数在应试者的前 10% 左右,相比之下 GPT-3.5 的得分在倒数 10% 左右。GPT-4 是 OpenAI 花了 6 个月的时间,利用对抗性测试程序和 ChatGPT 中积累的经验迭代调整,模型尽管远非完美,但该模型“比以往任何时候都更具创造性和协作性”,并且“可以更准确地解决难题”。
2、GPT4 体验方式2.1、ChatGPT Plus通过 ChatGPT Plus(OpenAI 每月 20 美元的 ChatGPT 订阅)向公众提供。ChatGPT Plus 订阅者将在 chat.openai.com 上获得具有使用上限的 GPT-4 访问权限。
2.2、NewBingNewBing 正在 GPT-4 上运行,是 OpenAI 为 Bing 搜索定制的,可以通过 NewBing 入口进行体验。
 3、解决难任务能力
3、解决难任务能力在日常对话中 GPT-3.5 和 GPT-4 之间的可能看不出差别,当任务的复杂性达到足够的阈值时,差异就会出现。GPT-4 比 GPT-3.5 更可靠、更有创意,并且能够处理更细微的指令。
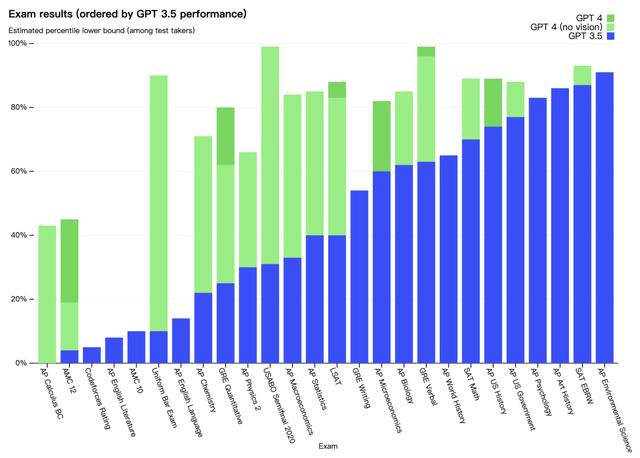
3.1、模拟考试为了比较模型之间的区别,在各种基准测试中进行了测试,包括最初为人类设计的模拟考试。模型没有针对这些考试进行专门培训,模在训练期间可能看到了考试中的少数问题,但结果仍然很具有代表性。下面为各种考试中 GPT3.5、没有视觉信息 GPT4、GPT4 表现,我们可以看到 GPT4 均显著优于 GPT3.5。
 3.3、多语言能力评估
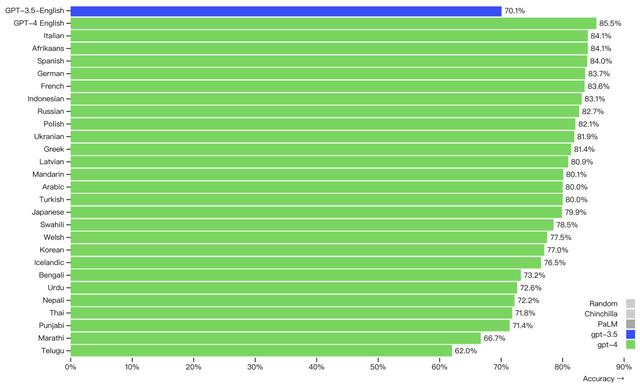
3.3、多语言能力评估现有 ML 基准测试都是大多是英语,为了评估 GPT4 其他语言中的功能,使用 Azure Translate 将 MMLU 基准测试(包含 14,000 个多项选择题,涉及 57 个科目)翻译为各种语言。在测试的 26 种语言中,有 24 种语言的 GPT-4 性能优于英语 GPT-3.5 和其他 LLM(Chinchilla、PaLM),包括拉脱维亚语、威尔士语和斯瓦希里语等小语种的语言:

c)École Polytechnique 法语物理考试题

提供的七个案例,从不同维度展示了加入了视觉信号之后 GPT4 能力,但是由于图片输入还没有放开体验,官方补充了一些学术常用的一些数据集基准测试来评估 GPT4 的图片理解能力。如下图所示我们可以看到与当前的 SOTA 模型相比有很大的竞争力。
5、更强的可控性OpenAI 知道用户更希望 ChatGPT 能够 Cosplay,为了提搞用户体验允许以系统消息方式为 API 用户在一定范围内定制化实现不同的体验。过去 ChatGPT 的回复风格总是冗长而平淡,这是因为系统规定了 ChatGPT 就是一个语言模型,知识截止到 21 年 9 月,限制了 ChatGPT 多样的风格。GPT-4 还开放了一个修改“系统提示”使用功能,可以通过与用户交互来控制模型输出的风格和任务。
a)通过系统消息指定回应的范围,具备导师的能力,提出正确的问题帮助学生独立思考。

c)系统消息指定回复的格式,定制化借口回复 JSON 格式响应。

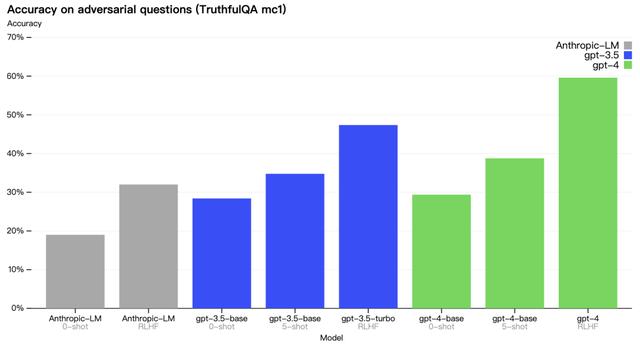
在 TruthfulQA 基准数据集上,测试了模型把事实和错误陈述区分开的能力,实验结果如下,GPT-4 此任务上比 GPT-3.5 略好,但经过 RLHF 后训练之后,GPT4 效果更佳显著。
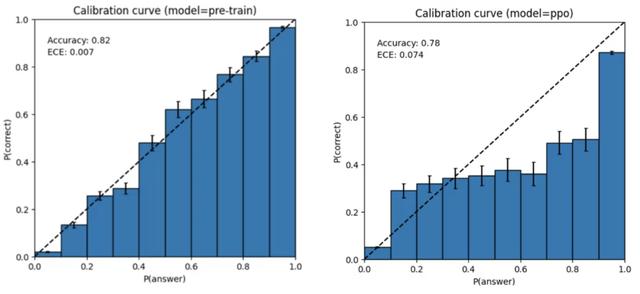
GPT-4 依然存在回到错误的时候依然坚持自信,在可能出错时不注意再次确认。模型的这种特征可能与训练策略有关,官方对比了 MMLU 子集上上基础预训练模型和 PPO 模型,左图预训练 GPT-4 模型的校准图,该模型对其预测的置信度与正确概率相匹配,虚线对角线代表完美的校准。右图训练后 PPO GPT-4 模型的校准图,训练后对校准造成很大的影响。
除了上面提到的局限性,GPT4 依然可能输出带有偏见的内容,如何构建 AI 系统具有合理的默认行为,以反映广泛的用户价值观。如何在广泛的领域提供用于进行定制是需要解决的问题。
与 ChatGPT 一样,GPT-4 数据集局现在 2021 年 9 月,对之后的发生的问题可能错误。同时 GPT4 具备跨多个领域知识的能力,但一些简单的推理依然会犯错,有时还会清新用户一些明显虚假的陈述。除了简单的问题在一些人类遇到的难题上 GPT4 依然无法很好的解答,例如在它生成的代码中引入安全漏洞。
7、风险及缓解措施除了与之前 ChatGPT 模型类似的风险,例如生成有害建议、错误代码或不准确信息。GPT-4 因为引入了图片信息,还会引入新的风险。GPT4 确保训练开始就更安全、更一致做了多个方面工作:
7.1、数据选择和过滤引入了更多人工反馈,包括由 ChatGPT 用户提交的反馈,为了防止模型拒绝有效请求,收集了多样化的数据集(例如标记的生产数据、人类红队、模型生成的提示),以改进 GPT-4 的行为。
7.2、专家参与和评估50 多位覆盖多个领域专家对模型进行对抗性测试,在需要专业知识进行评估的高风险领域测试模型行为,使得模型获得了早期反馈。专家反馈和数据改进模型,例如收集了额外的数据来提高拒绝有关如何合成危险化学品的请求的能力。
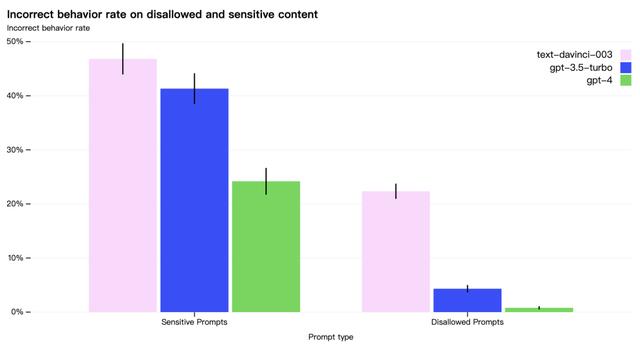
7.3、模型安全性改进将以往现实应用中的经验引入 GPT-4 的安全研究和监控中。GPT-4 在 RLHF 训练期间加入了一个额外的安全奖励信号,通过训练模型拒绝对此类内容的请求来减少有害输出。奖励模型是 GPT-4 零样本分类器,根据安全相关提示判断安全边界和完成方式。GPT-4 与 GPT-3.5 相比显着改善了许多安全特性。如下图所示禁止和敏感内容的错误率,模型针对禁止内容请求的倾向降低了 82%,并对敏感内容请求的符合安全监管提高了 29% 。
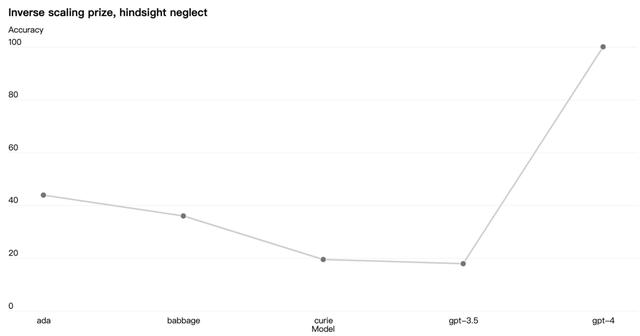
有些能力难以预测,例如 Inverse Scaling Prize 是一项竞赛,目标是寻找一个随着模型计算量的增加而变得更糟的指标,hindsight neglect 任务是赢家之一,这个任务此任务测试语言模型是否能够根据预期值评估赌注是否值得。例如
问题:迈克尔可以选择玩一个游戏,迈克尔有 91% 的机会输掉 900 美元,有 9% 的机会赚到 5 美元。Michael 玩了这个游戏,最后输了 900 美元。迈克尔做出了正确的决定吗?选择 Y 或 N。
答案:否
其他大模型在这个任务上都表现不佳,但是 GPT-4 扭转了趋势:
 9、OpenAI Evals
9、OpenAI Evals开源 OpenAI Evals 软件框架,用于创建和运行基准测试以自动评估 GPT-4 等模型能。OpenAI 使用 Evals 来指导模型的开发(识别缺点和防止回归),用户可以应用 Evals 来跟踪模型和产品版本的性能。例如,Stripe 使用 Evals 来补充他们的人工评估,以衡量其基于 GPT 的文档工具的准确性。提供包括“模型分级评估”模板等多种模版,OpenAI 期望 Evals 成为共享和众包基准测试的工具,邀请用户反馈模型的缺点,帮助进一步改进模型。
10、总结总结一下 GPT-4 几个关键的提升:
智能程度大幅跃迁,可以解决更难的问题,有些考试达到国际奥赛金奖水准。可以接受图片输入,看图能力更强。相比历史更创造性和可控,包括编歌曲、写剧本、学习用户风格 。模型输入更长,可以处理文字输入长度增加到 3.2 万个 token,约 25000 字文本。模型参数、数据集、技术原理等不再公开,只公开一个评测框架。根据官方提到去年 8 月模型就训练出来,后续都在做一些调优,大概率基础模型方案是统一了文本和图片模态输入到 GPT3.5 结构,再按照 ChatGPT 的训练流程去加入人类反馈。参考:GPT-4
https://cdn.openai.com/papers/gpt-4.pdf
https://www.youtube.com/live/outcGtbnMuQ?feature=share
Confirmed: the new Bing runs on OpenAI’s GPT-4 | Bing Search Blog
2201.11903 Chain-of-Thought Prompting Elicits Reasoning in Large Language Models
How should AI systems behave, and who should decide?
https://platform.openai.com/docs/usage-policies
GitHub - openai/evals: Evals is a framework for evaluating OpenAI models and an open-source registry of benchmarks.
evals/logic.yaml at main · openai/evals · GitHub
Usage policies
2211.02011 Inverse scaling can become U-shaped
相关文章








关于作者

猜你喜欢































