机器之心报道
机器之心编辑部
GPT-4 已经发布一个多月了,但识图功能还是体验不了。来自阿卜杜拉国王科技大学的研究者推出了类似产品 ——MiniGPT-4,大家可以上手体验了。
对人类来说,理解一张图的信息,不过是一件微不足道的小事,人类几乎不用思考,就能随口说出图片的含义。就像下图,手机插入的充电器多少有点不合适。人类一眼就能看出问题所在,但对 AI 来说,难度还是非常大的。

GPT-4 的出现,开始让这些问题变得简单,它能很快的指出图中问题所在:VGA 线充 iPhone。
其实 GPT-4 的魅力远不及此,更炸场的是利用手绘草图直接生成网站,在草稿纸上画一个潦草的示意图,拍张照片,然后发给 GPT-4,让它按照示意图写网站代码,嗖嗖的,GPT-4 就把网页代码写出来了。
但遗憾的是,GPT-4 这一功能目前仍未向公众开放,想要上手体验也无从谈起。不过,已经有人等不及了,来自阿卜杜拉国王科技大学(KAUST)的团队上手开发了一个 GPT-4 的类似产品 ——MiniGPT-4。团队研究人员包括朱德尧、陈军、沈晓倩、李祥、Mohamed H. Elhoseiny,他们均来自 KAUST 的 Vision-CAIR 课题组。

MiniGPT-4 还能对着一张图片生成菜谱,变身厨房小能手:

此外,值得一提的是,MiniGPT-4 Demo 已经开放,在线可玩,大家可以亲自体验一番(建议使用英文测试):
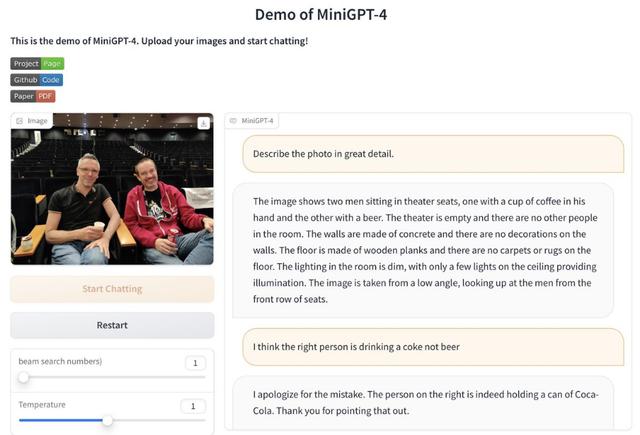
Demo 地址:https://0810e8582bcad31944.gradio.live/
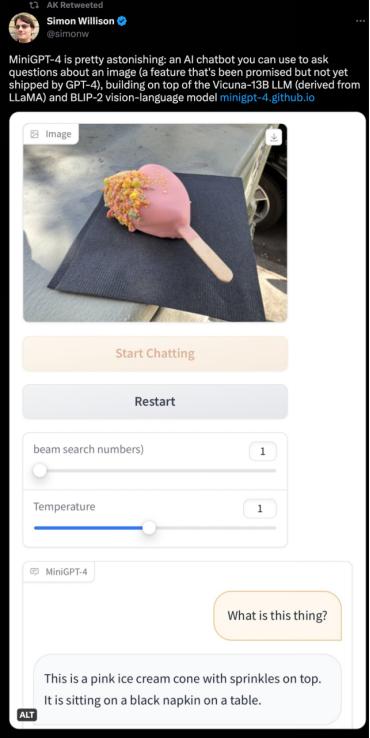
项目一经发布,便引起网友广泛关注。例如让 MiniGPT-4 解释一下图中的物体:
方法简介
作者认为 GPT-4 拥有先进的大型语言模型(LLM)是其具有先进的多模态生成能力的主要原因。为了研究这一现象,作者提出了 MiniGPT-4,它使用一个投影层将一个冻结的视觉编码器和一个冻结的 LLM(Vicuna)对齐。
MiniGPT-4 由一个预训练的 ViT 和 Q-Former 视觉编码器、一个单独的线性投影层和一个先进的 Vicuna 大型语言模型组成。MiniGPT-4 只需要训练线性层,用来将视觉特征与 Vicuna 对齐。

MiniGPT-4 进行了两个阶段的训练。第一个传统的预训练阶段使用大约 5 百万对齐的图像文本对,在 4 个 A100 GPU 上使用 10 小时进行训练。第一阶段后,Vicuna 能够理解图像。但是 Vicuna 文字生成能力受到了很大的影响。
为了解决这个问题并提高可用性,研究者提出了一种新颖的方式,通过模型本身和 ChatGPT 一起创建高质量的图像文本对。基于此,该研究创建了一个小而高质量的数据集(总共 3500 对)。
第二个微调阶段使用对话模板在此数据集上进行训练,以显著提高其生成可靠性和整体可用性。这个阶段具有高效的计算能力,只需要一张 A100GPU 大约 7 分钟即可完成。
其他相关工作:
VisualGPT: https://github.com/Vision-CAIR/VisualGPT
ChatCaptioner: https://github.com/Vision-CAIR/ChatCaptioner
此外,项目中还使用了开源代码库包括 BLIP2、Lavis 和 Vicuna。
相关文章









关于作者

猜你喜欢































