
阅卷组指出这篇作文是值得肯定,但并不是说鼓励大家都去写这样的作文,而是鼓励大家按照自己的兴趣、个性,写出有个性化的,不是千篇一律的作文。以笔者对于AI自然语言处理的发展趋势的了解,阅卷组的这说法值得肯定,因为像上述文章风格如此鲜明,角度剑走偏峰的文章,将是AI的优势领域。AI不仅能写文章,还能通过口述写代码呢!
在程序员饭碗不保了?GPT-3 最强应用发布,动动手指就自动写代码的神器来了,笔者介绍过基于 OpenAI 在六月份发布的最新NLP模型 GPT-3 ,而来的debuid.co网站,可通过口述英文需求,自动出现代码,颇有10倍程序员的风范。
GPT-3 到底是什么黑科技?

强大的 GPT-3
去年,微软为了提升在AI 上的储备,花 10 亿美元投资 OpenAI,为了让OpenAI推出高质量的训练模型,微软配置了由28.5万个CPU核心、1万个英伟达GPU核心的超级计算机,目前这台超算在全球算力榜上排名前五。其中GPT-3容量达到了45TB,参数个数有1750亿的超级怪物,恰恰是由微软提供的超算训练而成。
为了发挥GPT-3的最大价值,OpenAI开放了对GPT-3的内测申请资格,有兴趣的读者可以到https://openai.com/blog/openai-API/申请。
OpenAI不像大多数人工智能系统只针对单一场景提供服务,他们的API提供了一个通用的“文本输入,文本输出”功能,所以从这个角度上讲OpenAI已经从某种程度上提供了通用人工智能的服务了。比如OpenAI的API就完全支持用“人话”控制计算机了,而且还能根据人的指示对于指行的命令进行修订。

中文NLP
从本质上,中文中的字和英文中的Word并不是同一个概念,比如中文语境下“没钱买华为”到底是“华为太贵,因此买不起”还是“没钱的人会选择买华为的手机”是模糊的,中文没有时态的变化以对语义进行进一步的提示,因此一般最新的NLP模型都需要一定的移植工作才能在中文语境下发挥出高水平。
中文文本生成已不是难事了,比如基于TransfermerXL(https://github.com/GaoPeng97/transformer-xl-chinese)的项目,在以中文诗词进行训练后(https://github.com/chinese-poetry/chinese-poetry),拿来写诗的效果就不错。

GPT-3没有专门针对中文优化之前,笔者认为在中文领域效果最好的NLP模型是百度的 ERNIE 2.0(https://arxiv.org/pdf/1904.09223v1.pdf),这个模型试图从 3 个层面去更好的理解训练语料中蕴含的信息:
Word-aware Tasks: 词汇 (lexical) 级别信息的学习
Structure-aware Tasks: 语法 (syntactic) 级别信息的学习
Semantic-aware Tasks: 语义 (semantic) 级别信息的学习
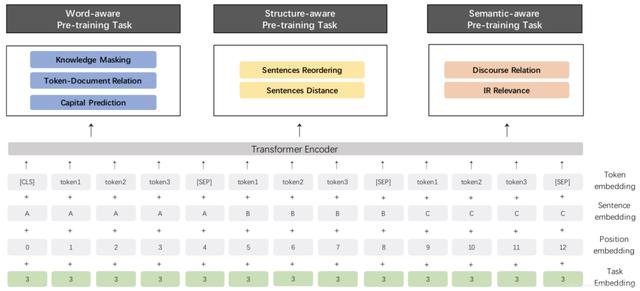
其解读如下:
一、词汇理解方式
知识增强蒙板策略:相较于BERT使用的mask策略, 该策略可以更好的捕捉输入样本局部和全局的语义信息。这点可以说是ERNIE的最大创新。
举个例子说明:
BERT的mask策略 :哈 [mask] 滨是 [mask] 龙江的省会,[mask] 际冰 [mask] 文化名城。
ERNIE的mask策略:[mask] [mask] [mask] 是黑龙江的省会,国际 [mask] [mask] 文化名城。
ERNIE是一个增强型的针对整个语义进行mask的训练方式。
首字母大写预测:针对英文首字母大写词汇(如 Apple)所包含的特殊语义信息,在英文预训练中构造了一个分类任务去学习该词汇是否为大写,这个是在其它模型中没有看到的训练方法。
相关词汇出现预测:针对一个 段中出现的词汇,去预测该词汇是否也在原文档的其他 段中出现。
二、语句理解方式
乱序预测训练:针对一个 paragraph (包含 M 个 segments),我们随机打乱 segments 的顺序,通过一个分类任务去预测打乱的顺序类别。
语句距离训练:通过一个 3 分类任务,去判断句对 (sentence pairs) 位置关系 (包含邻近句子、文档内非邻近句子、非同文档内句子 3 种类别),更好的建模语义相关性。
三、语法理解方式
通过判断句对间的修辞关系更好地学习句间语义。
正如笔者前文所说Open AI提供的服务能力相当于一个全栈的脑力工作者,其执行力之强远超人们之前的认知,趋势不可阻挡,未来已来,与其在角落瑟瑟发抖,不如赶快拥抱AI,成为AI背后的程序员。


相关文章






关于作者

猜你喜欢































