在这段时间,有关大语言模型的消息频频传出,许多人也逐渐了解、甚至开始应用起相关的AI软件。那么,你了解GPT模型的原理是什么吗?大模型和传统AI的区别在于哪里?其应用可以体现于哪些方面?一起来看看作者的分析和解读。

以SIRI为代表的人工智能助手统一了NLU层,用一个模型理解用户的需求,然后将需求分配给特定的AI模型进行处理,实现NLG并向用户反馈。然而,这种模式存在显著缺点。如微软官方图例所示,和传统AI一样,用户每遇到一个新的场景,都需要训练一个相应的模型,费用高昂且发展缓慢,NLG层亟需改变。
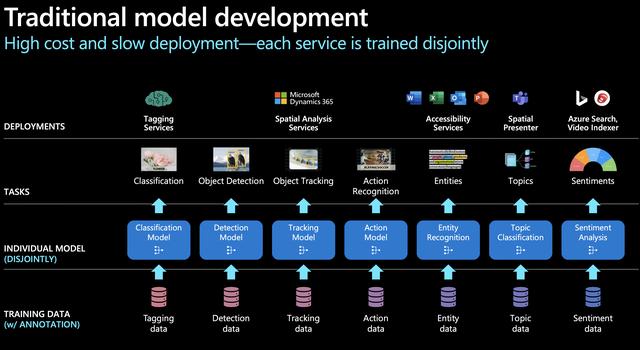
大型语言模型(如GPT)采用了一种截然不同的策略,实现了NLG层的统一。秉持着“大力出奇迹”的理念,将海量知识融入到一个统一的模型中,而不针对每个特定任务分别训练模型,使AI解决多类型问题的能力大大加强。
 2. ChatGPT如何实现NLG?
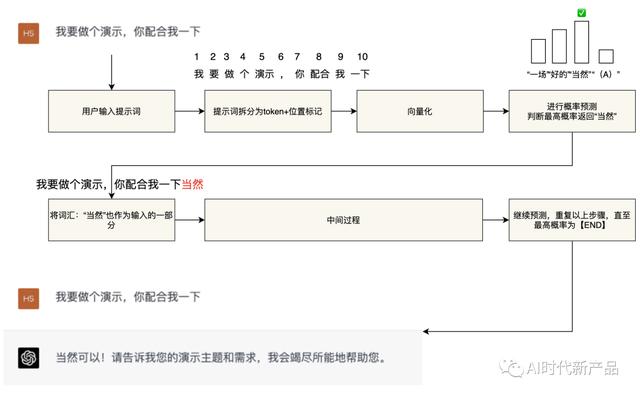
2. ChatGPT如何实现NLG?AI本质上就是个逆概率问题。GPT的自然语言生成实际上是一个基于概率的“文字接龙”游戏。我们可以将GPT模型简化为一个拥有千亿参数的“函数”。当用户输入“提示词(prompt)”时,模型按照以下步骤执行:
将用户的“提示词”转换为token(准确地说是“符号”,近似为“词汇”,下同) token的位置。将以上信息“向量化”,作为大模型“函数”的输入参数。大模型根据处理好的参数进行概率猜测,预测最适合回复用户的词汇,并进行回复。将回复的词汇(token)加入到输入参数中,重复上述步骤,直到最高概率的词汇是【END】,从而实现一次完整的回答。这种方法使得GPT模型能够根据用户的提示,生成连贯、合理的回复,从而实现自然语言处理任务。
 3. 上下文理解的关键技术
3. 上下文理解的关键技术GPT不仅能理解用户当前的问题,还能基于前文理解问题背景。这得益于Transformer架构中的“自注意力机制(Self-attention)”。该机制使得GPT能够捕捉长文本中的依赖关系。
通俗地说,GPT在进行文字接龙判断时,不仅基于用户刚输入的“提示”,还会将之前多轮对话中的“提示”和“回复”作为输入参数。然而,这个距离长度是有限的。对于GPT-3.5来说,其距离限制为4096个词汇(tokens);而对于GPT-4,这个距离已经大幅扩展至3.2万个tokens。
4. 大模型为何惊艳?我们已经介绍了GPT的原理,那么他是如何达成这种神奇效果的呢?主要分三步:
自监督学习:利用海量的文本进行自学,让GPT具备预测上下文概率的基本能力。监督学习:人类参与,帮助GPT理解人类喜好和期望的答案,本质为微调(fine-tune)。强化学习:根据用户使用时的反馈,持续优化和改进回答质量。其中,自监督学习最关键。因为,大模型的魅力在于其“大”——大在两个方面::
训练数据量大:即训练大模型的数据规模,以GPT-3为例,其训练数据源为互联网的各种精选信息以及经典书籍,规模达到了45TB,相当于阅读了一亿本书。模型参数量大:参数是神经网络中的一个术语,用于捕捉数据中的规律和特征。通常,宣称拥有百亿、千亿级别参数的大型模型,指的都是其参数量。追求大型模型的参数量是为了利用其神奇的“涌现能力”,实现所谓的“量变引起质变”。
举例来说,如果要求大模型根据emoji猜电影名称,如
相关文章







关于作者

猜你喜欢































