OpenAI计划下个月为开发者推出重大更新,可以使基于其人工智能(AI)模型构建软件应用程序的成本更低、速度更快。让开发者基于ChatGPT搭建APP的成本一次性缩水95%。目前,OpenAI正试图吸引更多公司使用其技术。

GPT-4即将超越拐点,并且性能实现显著跳跃。GPT-4参数规模扩大1000倍,1万倍GPT-4,让神经网络学习目标函数,再进一步扩展模型。
这些更新包括为使用AI模型的开发人员工具增加内存存储。从理论上讲,这可以将应用程序开发商的成本削减多达20倍,从而解决合作开发伙伴的一个主要担忧,更顺利地开发和销售人工智能软件来建立可持续的业务。

GPT-4参数规模扩大1000倍,如何实现?OpenAI科学家最新演讲,从第一性原理出发,探讨了2023年大模型发展现状。
在他看来,我们所有人需要改变观点。LLM实则蕴藏着巨大的潜力,只有参数量达到一定规模时,能力就会浮现。
1万倍GPT-4,让神经网络学习目标函数,再进一步扩展模型规模时,设想是GPT-4的10000倍,应该考虑什么?
对Hyung Won Chung来说,扩展不只是用更多的机器做同样的事情,更关键的是找到限制进一步扩展的「归纳偏差」(inductive bias)。

扩展并不能解决所有问题,我们还需要在这大规模工程的工作中做更多研究,也就是在后训练中的工作。
你不能直接与预训练模型对话,但它会在提示后继续生成,而不是回答问题。即使提示是恶意的,也会继续生成。
模型后训练的阶段的步骤包括,指令调优——奖励模型训练——策略模型训练,这也就是我们常说的RLHF。
尽管RLHF有着一些弊端,比如奖励模型容易受到「奖励黑客」的影响,还有开放的研究问题需要解决,但是我们还是要继续研究RLHF。
因为,最大似然法归纳偏差太大;学习目标函数(奖励模型)以释放缩放中的归纳偏差,是一种不同的范式,有很大的改进空间。
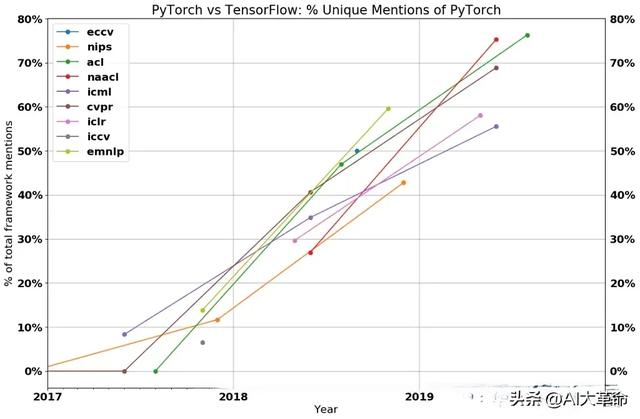
另外,RLHF是一种有原则的算法 ,需要继续研究,直到成功为止。
在Hyung Won Chung认为,最大似然估计目标函数,是实现GPT-4 10000倍规模的瓶颈。
使用富有表达力的神经网络学习目标函数,将是下一个更加可扩展的范式。随着计算成本的指数级下降,可扩展的方法终将胜出。
最后我们一起期待11月份的更新。

相关文章





关于作者

猜你喜欢
成员 网址收录40400 企业收录2981 印章生成237601 电子证书1052 电子名片60 自媒体51770































