机器之心报道
作者:泽南
「通用人工智能是未来十到二十年国际科技竞争的战略制高点,其影响力相当于信息技术领域的『原子弹』。」3 月 4 日,在全国政协会议上,北京通用人工智能研究院院长朱松纯在一份提案中建议,要将发展通用人工智能提升到当代「两弹一星」的高度,抢占全球科技与产业发展制高点。
过去很长一段时间里,通用人工智能对于大多数 AI 学者来说是个遥不可及的目标,最近 ChatGPT 的出现却让人感觉:通用人工智能似乎已近在眼前。
ChatGPT 可以胜任各种任务,如搜索问答、文本生成甚至代码生成等,完全超越了人们印象中的 AI 智能助手。在使用者看来,它不仅能分辨出提问者的真实诉求,还拥有出乎预料的博识程度。
但在 ChatGPT 引发的全球技术竞赛中,我们剩下的时间可能不多了:上周三,OpenAI 开放了 ChatGPT API,开发者现在可以通过程序接口将 ChatGPT 和 Whisper 模型的能力集成到自身应用中。过不了多久,我们就能在各种常用 App 上见到「史上最强 AI」的强大能力了。

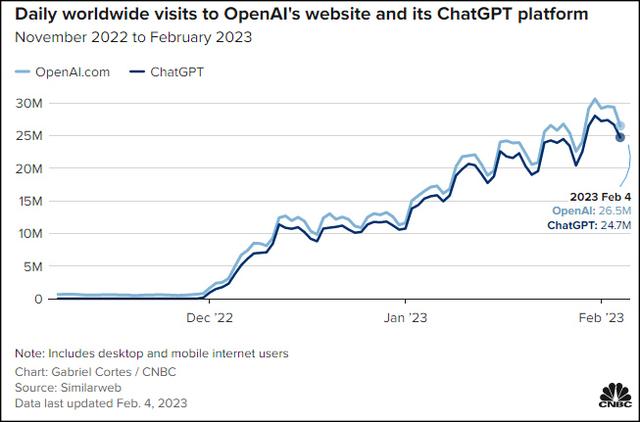
图源:https://lifearchitect.ai/chatgpt/
在 GPT 系列的发展过程中,「炼大模型」逐渐成为了人们提升 AI 性能的重要方式。短短几年,AI 模型的参数量已经从最初的数亿扩张到千亿,甚至万亿规模。
由于 AI 大模型的复杂程度,要想复制 ChatGPT 的成功,意味着技术团队必须要有足够的技术积淀,能动用大量数据和基础设施。在追赶的竞赛中,国内可能很难出现像 OpenAI 这样背靠巨头,「拥有无限资金」的创业公司。重任落到了大厂肩上。
从参数规模来看,国内科技公司的实验室里已经诞生过能够比肩最新版 GPT 体量的语言大模型。根据目前的消息,百度、阿里、腾讯等科技大厂,也已经纷纷官宣进入 ChatGPT 风口。
百度是最早针对 ChatGPT 做出明确表态的公司之一,在人工智能技术四层架构中的全栈布局是其应战的底气。2021 年底,百度曾共同发布了全球首个知识增强千亿大模型「鹏城 - 百度・文心」,模型参数达 2600 亿,是当时全球最大中文单体模型,在 60 多项任务上取得了最好效果。
在微软与谷歌争夺 ChatGPT 搜索首发的同时,百度也官宣了将在 3 月 16 日推出类 ChatGPT 产品「文心一言」。

盘古模型在预训练阶段学习了 40TB 中文文本数据,并通过行业数据的样本调优提升了模型在场景中的应用性能,在 16 个下游任务中性能指标优于业界 SOTA 模型。在应用方向上,盘古支持丰富的应用场景,在知识问答、知识检索、知识推理、阅读理解等文本生成领域表现突出。
从技术实践、人才合作到落地应用,从国内一众大厂的表态中我们不难看出,ChatGPT 的竞争中,国内在很多领域上拥有相应的实力。
但这并不是全部,造大模型还有算力这个绕不过去的槛。
跨过算力门槛人工智能先驱 Richard Sutton 在 2019 年曾发表过一篇著名的文章《苦涩的教训》(The Bitter Lesson),其中一句话说道:「70 年的人工智能研究史告诉我们,利用计算能力的一般方法最终是最有效的方法。」
这是一个颇具争议的观点,但他的预见在 2020 年的 GPT-3 上获得了验证,并随着去年 11 月出世的 ChatGPT 再次引发了广泛讨论。在过去几年中,大量研究者和机构在大模型这个方向上进行探索,并收获了成效,但随着模型体量的急剧膨胀,人们已开始面临大模型「算不起」的问题。
根据 OpenAI 自己的测算,自 2012 年起,全球头部 AI 模型训练算力需求每 3 到 4 个月翻一番,每年先进的模型训练所需算力增长幅度高达 10 倍。

鹏城云脑 II 自 2021 年起正式运行,是一套专为 AI 任务设计的超算系统,曾在国际超算大会上多次刷新世界纪录。它以华为 Atlas AI 集群为底座,通过多样化的异构计算平台、多源算法平台和多态智能应用,支撑了多项 AI 重大应用的模型训练及推理。
更重要的是,鹏城云脑 II 可以提供 1E OPS 智能算力,即不低于每秒 100 亿亿次操作的 AI 计算能力。在盘古大模型的训练上,华为就动用了超过 2000 块昇腾 910,以 640P FLOPS 的 FP16 算力训练了两个月。
而鹏城云脑只是体现华为 AI 整体能力的案例之一。宏观的看,在 2022 年的国内云计算市场份额调研中,华为云已位居第二,增速达 67%,是当前国内市场中云增速最快的主流云服务商之一。
为了让 AI 技术更高效地落地,华为还实现了从底层硬件到应用软件的整体打通,通过底层软件、训练框架、ModelArts 平台的协同优化,充分释放了芯片算力,实现了端到端的性能优化。
据介绍,借助 ModelArts 平台的高效处理海量数据能力,在训练盘古大模型时,华为仅用 7 天就完成了 40TB 文本数据的处理工作。而当前的盘古系列超大规模预训练模型,已经包括 NLP 大模型、CV 大模型、多模态大模型和科学计算大模型等多个种类。

新兴的 AI 技术也面临着技术落地的挑战。在很多行业应用中,人们需要针对业务场景开发一系列定制化模型,各自完成数据清洗、数据增强、模型适配等工作,这些模型面临着难以复用的挑战。预训练大模型的逻辑是提前将知识、数据、训练成果沉淀到同一个模型中,再由不同应用的开发者在此基础上进行二次开发和微调,就像一个基础通用的技术底座,可以大幅提升效率。
这让 AI 具备更多的普惠属性,华为基于盘古提出了以大模型为核心的普适 AI 建模工作流,能让一个模型覆盖多个场景,减少专家的干预和人为调优的消耗,大幅提升技术落地效率,也降低了技术门槛。这或许是搜索引擎之外,能让大模型更广泛应用的正确方向。
不难看出,AI 领域发展到了 ChatGPT 时代,早已不再是比某项领先的技术,而是在比整套技术体系,真正具备全栈实力的公司会很快脱颖而出。
那么,ChatGPT 军备竞赛,华为会出手吗?根据最近的消息,在华为内部,有项目已在研发过程中了。
相关文章







关于作者

猜你喜欢































