OpenAI 近期介绍了该实验室在 2017 年打造的 8 种仿真机器人环境和一种新的强化学习技术,这些技术被用来训练最终用于真实机器人的人工智能模型。同时,该实验室还提出了机器人研究领域的一系列待解答新问题。
8 种仿真机器人环境采用 MuJoCo 物理仿真平台构建。这 8 种仿真环境是:
拿取
图丨拿取-碰触 v0:手臂碰触一个放在桌面上的小球,让小球滚过桌面,达到指定位置。

图丨虚拟手掌-方块掌控 v0:虚拟手掌玩弄手上的方块,直到方块的指向和位置符合要求。

研究团队用拿取-碰触 v0 仿真环境,解释了 HER 的工作原理。该仿真环境的目标是:用机械手碰触一个桌面上的小球,让小球滚过桌面,击中目标。首次尝试不太可能成功,接下来的几次也不太可能,因此得分始终为-1。传统的强化学习算法无法在这种一直没有达成目标的环境中实现学习。
HER 的创新之处在于:即使这几次都没有达成预定目标,机械手至少达成了另一个目标。因此,不妨把这个“非预定目标”作为起始。这样,强化学习算法就可以因为达成了某些目标而实现学习——尽管这个目标不是最终的目标。只要重复这个渐进过程,机械手最后总会实现预定目标。
总之,HER 系统可以在一次也没有达成原定目标的情况下启动强化学习。该系统的秘诀是“打哪指哪”,即中间目标是机械手碰球之后才选定的。“打哪指哪”方法是机器学习中的常用方法之一,HER 可以跟任何基于新策略的强化学习算法(off-policy RL algorithm),如 DQN 和 DDPG 等联合使用。
测试结果测试表明,HER 在“稀疏回报”奖励条件下的目标达成仿真环境中表现优异,具体如下图所示:
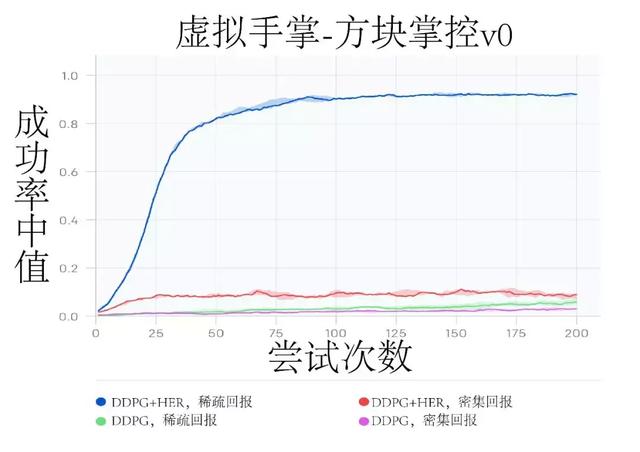
图丨成功率中值(线条)和四分位范围(阴影区域)都是在虚拟手掌-方框掌控 v0 环境中测试获得的。
稀疏回报条件下的 DDPG HER 算法表现最好,不过有趣的是,DDPG HER 算法在密集回报条件下的表现反而更差。原始 DDPG 算法不管在什么奖励条件下,表现都不如人意。此外,各算法的表现差异在大多数实验环境中保持稳定。
后续研究方向HER 算法为稀疏回报条件下的复杂目标导向任务提供了一种新的解决手段,但其仍有很大改进空间,具体地,研究团队提出了如下的后继研究问题:
1,“打哪指哪”算法的自动化目标设定。目前的“打哪指哪”算法,只能由人工设定中间目标。
2,无偏 HER。目前的中间目标选择并没有一个严格的规则,这在理论上会导致学习结果的不稳定性,尽管实验中尚未发现这种情况。但是,研究团队认为,基于重要性采样等技术,可以通过严格的规则实现无偏 HER。
3,HER 与层级强化学习(hierarchical reinforcement learning, HRL.)的结合。这样可以将 HER 从单一目标推广到层级体系中。
4,更多类型的价值函数。是否可以将更多类型的价值函数,如贬值因子(discount factor)或成功阈值(success threshold)纳入“打哪指哪”算法中?
5,更快的信息传输。大多数新策略深度强化学习算法使用目标网络保证训练的稳定性。然而,由于变化在模型中的传导需要时间,因此对稳定性的要求已经成为限制 DDPG HER 学习速度的最大因素。或许可以通过采用其他稳定策略的方法来提高速度。
6,HER 多步回报。基于“打哪指哪”和中间目标的 HER 是典型的新策略强化学习算法,因此难以采用多步回报函数(multi-step returns)。然而,多步回报函数的信息反馈速度更快,因此值得研究如何将其纳入 HER 算法。
7,既定策略(On-policy)HER。目前,由于引入中间目标,HER 只能使用新策略算法。人但是,PPO 等基于既定策略的算法展示了很高的稳定性,因此有必要研究 HER 如何通过重要性采样等方法与之联合。该研究目前已经取得了初步成果。
8,连续活动的强化学习。目前,在连续控制的场合,强化学习算法的表现非常差,一方面由于不连续的外推,另一方面在于回报信息不能及时反馈回来。如何设计强化学习算法以适应连续控制场合仍然是一个问题。
9,将 HER 与其他最新强化学习算法结合。一些可能的选项是优先级经验回顾(Prioritized Experience Replay)、分布式强化学习(distributional RL)、熵规整化强化学习(entropy-regularized RL,)、逆向课程强化学习(reverse curriculum generation)。
更多信息可以参阅研究团队发布的技术报告:
使用新仿真环境的指南使用新的基于目标的仿真环境,需要对现有仿真环境做出如下改动:
所有基于目标的仿真环境都采用 gym.spaces.Dict 观察空间。仿真环境应当包括最终目标(esired_goal)、目前达到的目标(achieved_goal)和机器人的状态(observation)。
仿真系统允许根据目标的改变重新计算回报函数的值,以令基于 HER 的算法可以运行。
研究人员给出了简单的例子,来演示基于目标的仿真环境,以及“打哪指哪”算法对中间目标的选择过程。
基于目标的新仿真环境可以与现有的强化学习算法,如 Baselines.Use 等兼容,但需要首先使用 gym.wrappers.FlattenDictWrapper 将观测空间转换为所需格式的矩阵。
相关文章









关于作者

猜你喜欢































