编辑:桃子 拉燕
【新智元导读】Meta在CV领域又放了个大的!自监督 无需微调,计算机视觉又要不存在了?继「分割一切」后,Meta再发DINOv2。
这还是小扎亲自官宣,Meta在CV领域又一重量级开源项目。
效果演示
Meta在官网上放出了深度估计、语义分割和实例检索的案例。
深度估计:

对于不熟悉计算机视觉的朋友来讲,深度估计(Depth Estimation)可能是一个比较陌生的词汇。但其实,只要理解了其应用场景就能明白是什么意思了。
简单来说,对于2D照片,因为图像是一个平面,所以在3D重建时,照片中每一个点距离拍摄源的距离就至关重要。
这就是深度估计的意义。
右侧的图片中,相同的颜色代表距离拍摄点距离相同,颜色越浅距离越近。这样子整个图片的纵深就出来了。
再来看几组例子:

实例检索:
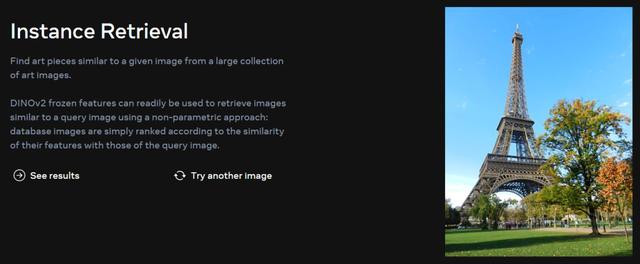
这个就更好理解了。上传图片到模型中,就可以从有茫茫多图片的库中找到类似的图片。
上图中的埃菲尔铁塔就是输入的图片,模型随后检索出了大量同题材的图片,风格各异。

论文地址:https://arxiv.org/pdf/2304.07193.pdf
看完了SOTA级别的演示,接下来我们来看一看藏在背后的技术突破。
要知道,自然语言处理中对大量数据进行模型预训练的突破,为计算机视觉中类似的基础模型开辟了道路。
这些模型可以通过产生多种用途的视觉特征,大大简化任何系统中的图像使用,无需微调就能在不同的图像分布和任务中发挥作用的特征。
这项工作表明,现有的预训练方法,特别是自监督方法,如果在来自不同来源的足够的数据上进行训练,就可以产生这样的效果。
Meta的研究人员重新审视了现有的方法,并结合不同的技术,在数据和模型的大小上扩展我们的预训练。
大多数技术贡献的是加速和稳定规模化的训练。在数据方面,Meta提出了一个自动管道,目的是建立一个专门的、多样化的、经过整理的图像数据集,而不是像自监督文献中通常所做的那样,建立未经整理的数据。
而在模型方面,研究人员用1B的参数训练了一个ViT模型,并将其提炼成一系列较小的模型,这些模型在大多数图像和像素级别上超过了现有的OpenCLIP在图像和像素层面上的基准。
与学习任务无关的预训练表征已经成为自然语言处理(NLP)的标准。人们可以照搬这些特征,不用进行微调,并在下游任务中取得了明显优于特定任务模型产生的性能。
这种成功被大量原始文本预训练所推动,如语言建模或单词向量,而不需要监督。
在NLP的这种范式转变之后,研究人员预计,计算机视觉中会出现类似的基础模型。这些模型能产生在任何任务中都能发挥作用的视觉特征。在图像层面,有图像分类,而在像素层面,则有分割(如上例)。
对这些基础模型的大多数努力都集中在文本指导的预训练上,即使用一种文本监督的形式来指导特征训练。这种形式的文本指导的预训练限制了可以保留的关于有关图像的信息,因为标题只包含图像中的表层信息,而复杂的像素级信息可能不会体现。
此外,这些图像编码器需要一一对应的文本&图像语料库。文本指导的预训练的一个替代方法,是自我监督学习,其特征是单独从图像中学习。这些方法在概念上更接近于语言建模等任务,并且可以在图像和像素层面上捕捉信息。
然而,自我监督学习的大部分进展都是在小型策划数据集ImageNet1k上进行预训练的。一些关于将这些方法扩展到ImageNet-1k之外的努力已经被尝试过了,但他们的特点是,专注于未经整理的数据集,导致特征的质量大幅下降。
这是因为缺乏对数据质量和多样性的控制。
Meta的研究人员关注的问题是,如果在大量的策划过的数据上进行预训练自我监督学习,是否有潜力学习所有的视觉特征。他们重新审视了现有的在图像和斑块层面学习特征的鉴别性自监督方法,如iBOT,Meta的研究人员在更大的数据集下重新考虑了iBOT的一些选择。
Meta的大部分技术贡献都集中在针对模型和数据规模扩大时的稳定和加速判别性自我监督学习等方面。这些改进使新方法比类似的鉴别性自我监督方法快2倍左右,所需的内存少3倍,这样就能利用更大的批次规模进行更长时间的训练。
关于预训练数据,研究人员建立了一个模型来过滤和重新平衡包含大量未处理的图像的数据集。灵感来自于NLP中使用的办法,使用了数据相似性而非外部元数据,且不需要手动注释。
在这项工作中,一个简单的聚类方法能出色地解决这个问题。
Meta的研究人员收集了一个由1.42亿张图片组成的多样化的语料库来验证此办法。最终提供了各种预训练的视觉模型,称为DINOv2,也就是今天我们介绍的主角。
Meta也是发布了所有的模型和代码,以便在任何数据上都可以重新训练DINOv2。
研究人员在各类计算机视觉的基准上验证DINOv2的能力,并在图像和像素层面上,还对其进行了扩展,如下图。

参考资料:
相关文章









关于作者

猜你喜欢
成员 网址收录40400 企业收录2981 印章生成237605 电子证书1052 电子名片60 自媒体51893































