整理 | 屠敏
出品 | CSDN(ID:CSDNnews)
迄今为止,GPT-4 凭借多模态能力已经成为 AI 领域备受关注的大模型,不过值得注意的是,OpenAI 在推出 GPT-4 时虽然引入了对图像理解的能力,但并没有在除了 Be my Eyes(针对盲人或弱视人士的应用程序和服务)应用程序之外的任何地方提供此功能。
GPT-4 对图像理解能力的示例详见:
用户:这幅画有什么好笑的地方?逐一描述它的板块。

在实验中,该团队发现只对原始图像-文本对进行预训练会产生不自然的语言输出,包括重复和零散的句子,缺乏连贯性。为了解决这个问题,其在第二阶段策划了一个高质量、一致性好的数据集,利用对话模板对此模型进行微调,这一步被证明对提高模型的生成可靠性和整体可用性至关重要。
具体来看,研究团队分两个阶段训练了 MiniGPT-4 模型。
第一阶段,研究团队首先在四张 NVIDIA A100 显卡上利用了大约 500 万个对齐的图像-文本对,让 MiniGPT-4 进行了十个小时的训练。在第一阶段之后,Vicuna 能够理解图像。但是 Vicuna 的生成能力受到了很大的影响。
为了解决这个问题并提高可用性,研究人员提出了一种通过模型本身和 ChatGPT 一起创建高质量图像文本对的新方法。因此,展开了第二阶段的微调训练,该模型使用 MiniGPT-4 和 ChatGPT 之间的交互生成的 3,500 个高质量文本图像对进行了改进。ChatGPT 更正了 MiniGPT-4 生成的不正确或不准确的图像描述。
这一步显著提高了模型的可靠性和可用性,MiniGPT-4 能够连贯地和用户友好地谈论图像,并且只需要在单个 NVIDIA A100 上进行七分钟的训练。让研究人员自己都感到惊讶的是,这个阶段的计算效率很高。
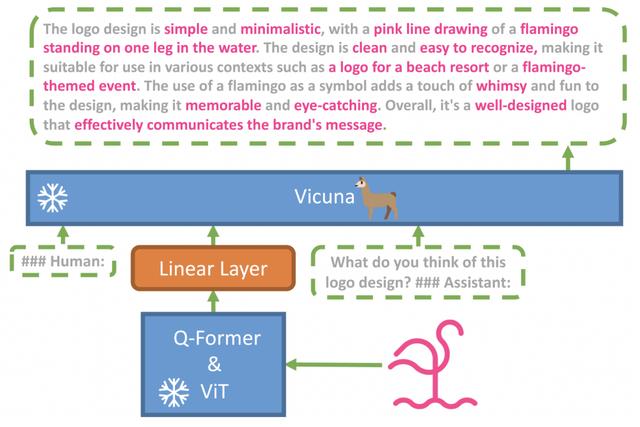
开源类 GPT-4 模型层出不穷
鉴于 OpenAI 没有透露太多关于 GPT-4 架构(包括模型大小)、硬件、训练计算、数据集构建、训练方法的细节,强大的 LLM 的开源 MiniGPT-4 可能在研究方面具有重要意义。
对于 MiniGPT-4 的到来,也引发了一些 HN 网友的热议,有网友表示:
在技术层面上,这个研究团队正在做一些非常简单的事情--将 BLIP2 的 ViT-L Q-former,用一个线性层连接到 Vicuna-13B,并在一些图像-文本对的数据集上只训练这个小层。
但结果是相当惊人的。它完全打败了 Openflamingo 和甚至原始的 blip2 模型。最重要的是,它比 OpenAl 的 GPT-4 图像模态更早到达。(这是)开源人工智能的真正胜利。
也有媒体评价到,「MiniGPT-4 是开源社区在很短时间内取得快速成功的另一个案例。前几天,开源聊天机器人 OpenAssistant 推出,使用从志愿者那里收集的指导数据进行训练,并打算最终成为一个 ChatGPT 的开源平替。这表明纯 AI 模型公司的护城河可能没有那么高。在这种趋势下,对于 OpenAI 公司而言,首先应该专注于使用 ChatGPT 插件为 GPT-4 建立一个合作伙伴生态系统,而不是现在就训练 GPT-5,这是有意义的。」
事实上,除了 OpenAssistant、MiniGPT-4 之外,GitHub 上也有网友盘点了近段时间来诞生的许多开源模型(https://github.com/nichtdax/awesome-totally-Open-chatgpt),如 Databricks 推出的 Dolly 模型、类 ChatGPT 的 PaLM-rlhf-pytorch、OpenChatKit 等等,为此,你认为开源大模型在此趋势下会迎来什么样的发展机遇?欢迎留言分享你的看法。
项目地址:https://minigpt-4.github.io/
GitHub地址:https://github.com/Vision-CAIR/MiniGPT-4
论文地址:https://github.com/Vision-CAIR/MiniGPT-4/blob/main/MiniGPT_4.pdf
参考:
https://the-decoder.com/minigpt-4-is-another-example-of-open-source-ai-on-the-rise/


相关文章






关于作者

猜你喜欢































