编辑:Aeneas 好困
【新智元导读】刚刚,谷歌DeepMind、JHU、牛津等发布研究,证实GPT-4的心智理论已经完全达到成年人类水平,在更复杂的第6阶推理上,更是大幅超越人类!此前已经证实,GPT-4比人类更能理解语言中的讽刺和暗示。在心智理论上,人类是彻底被LLM甩在后面了。
GPT-4的高阶心智理论(ToM),已经正式超越人类!
就在刚刚,谷歌DeepMind、约翰斯·霍普金斯大学和牛津大学等机构的学者发布的研究证实,GPT-4在心智理论任务上的表现,已经完全达到了成年人类的水平。
而且,它在第6阶推理上的表现,更是大幅超过了人类!

高阶心智理论
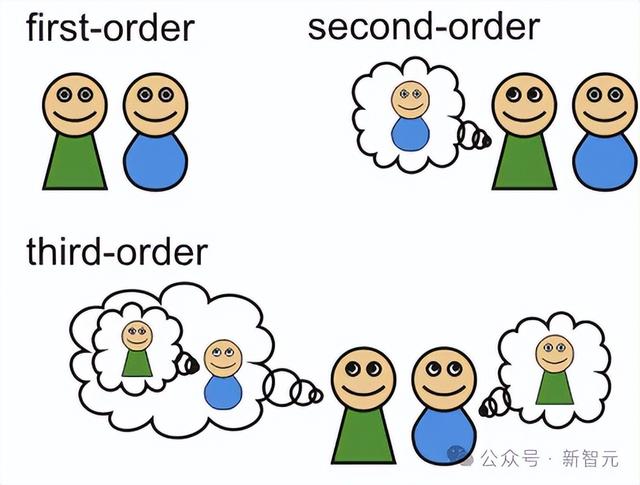
这次的研究,探讨了LLM究竟能在多大程度上发展高阶心智理论(higher-order ToM)。
所谓高阶心智理论,就是人类以递归方式,推理他人的多种心理和情感状态的能力。
比如,「我认为你相信她知道」这句话中,就包含了非常复杂的多层推理,属于一个三阶陈述。
在以前,大部分相关研究,都集中在二阶ToM上。
用什么样的方法,能衡量出LLM对如此复杂问题的把握能力?
团队特意引入了一套手写测试套件——多阶心智理论问答测试。
而参与PK的选手,有5个LLM和一大群成年人。

第6阶:GPT-4准确率93%,人类准确率82%
多阶心智理论问答:MoToMQA
这套全新的基准测试——多阶心智理论问答(Multi-Order Theory of Mind Question & Answer, MoToMQA),基于一种经过充分验证的心理测试——记忆任务(Imposing Memory Task, IMT)。
MoToMQA中,包括7个短篇故事,每个故事大概有200字左右,描述了3到5个角色之间的社交互动。

另外,团队特意没有公开放出MoToMQA基准测试,以防止它包含在未来LLM的预训练语料库中,从而使测试失去意义。
对于每个陈述,团队都经过了非常严格的检查,保证陈述不能有不清晰或模棱两可的措辞、语法错误、缺失的心理状态或命题条款。
在陈述中,仅仅包含涉及社交事实的事实陈述(即与故事中个体相关的事实),而不包括工具性事实(比如「天空是蓝色的」),并且会平衡每个故事中真假陈述的数量、陈述类型以及心智理论阶数或事实级别。
这样,就保证了每个故事的陈述集如下,[ToM2t, ToM2f, ToM3t, ToM3f, ToM4t, ToM4f, ToM5t, ToM5f, ToM6t, ToM6f, F2t, F2f, F3t, F3f, F4t, F4f, F5t, F5f, F6t, F6f]。
其中,数字表示心智理论阶数或事实级别,「ToM」表示心智理论,「F」表示事实,「t」表示真陈述,「f」表示假陈述。
对于事实陈述来说,仅需要回忆;而心智理论陈述,则需要回忆加推理。

使用独立样本比例,测试评估LLM和人类在ToM与事实任务上的表现
人类和LLM对故事理解到了什么程度?会怎样回忆?这些都是用事实陈述来控制的。
而鉴于心智理论和事实陈述之间的固有差异,团队又增加了一个进一步的控制条件——
他们设计了两个「故事条件」。
在「无故事」条件中,被试阅读故事后,会进入第二个屏幕回答问题,无法再看见之前的故事了。
而在「有故事」条件中,被试回答问题时,故事仍然会留在屏幕顶部,这样,就消除了心智理论失败实际上是记忆失败的可能性。
 事实任务
事实任务在事实任务上,依然是GPT-4和Flan-PaLM的表现最好。
同样,人类与GPT-4差异不大,但表现显著优于Flan-PaLM。
锚定效应此外,团队还研究了响应选项的顺序(先真后假 vs. 先假后真)影响。
结果显示,在「先真后假」条件下,PaLM提供「真」回答的比例显著高于「先假后真」条件。GPT-3.5在「先真后假」条件下提供「真」回答的比例也显著高于「先假后真」条件。
 高阶表现
高阶表现先前的IMT研究发现,随着「阶」的增加,模型的表现会下降。
的确,GPT-4和Flan-PaLM在第2阶表现优异,但在第4阶有所下降。
随后,Flan-PaLM的表现继续下降,但GPT-4则开始上升,并且在第6阶任务上显著优于第4阶任务。
类似的,人类在第5阶任务上的表现也显著优于第4阶任务。
对人类而言,这可能是因为一种新的认知过程在第5阶时「上线」,使得在高阶任务上的表现相对于使用低阶认知过程的任务有了提升。
如果这一解释成立,那么很可能GPT-4从其预训练数据中学习到了这一人类表现模式。
值得注意的是,GPT-4在第6阶任务上的准确率达到了93%,而人类的准确率为82%。
其原因可能是,第6阶陈述的递归句法可能给人类带来了认知负荷,但这并不影响GPT-4。
具体而言,ToM能力支持人类掌握递归句法直到第5阶,但在之后则依赖于递归句法。因此,个体在语言能力上的差异可能解释了在第6阶观察到的表现下降。
不过,与LLM不同的是,人类够通过非语言刺激(例如在真实的社会互动中)做出正确的推理。

数据集
在此次研究中,LLM数据集是由6个候选词的对数概率组成的,并作为了模型生成的完整概率分布的一个子集。
团队通过将语义等效的正向token和负向token的概率分别相加,并将每一个除以总概率质量,提取出了「真」或「假」响应的总体概率。

人类数据集则包含对同一陈述的多个响应,而LLM数据集对每个陈述仅包含一个响应。
为了使两者的数据分析单位一致,团队将人类数据转换为单一的二元「True」或「False」响应,基于每个陈述的「True」响应平均数是否高于或低于50%。
五项心智理论,GPT-4四项超越人类
而此前,Nature子刊《自然·人类行为》证明GPT-4的心智理论优于人类的研究,进行的是以下5项测试——错误信念、反讽、失言、暗示、奇怪故事。
结果显示,GPT-4在5项测试中有3项的表现明显优于人类(反讽、暗示、奇怪故事),1项(错误信念)与人类持平,仅在失言测试中落于下风。
更可怕的是,GPT-4其实并非不擅于识别失言,而是因为它非常保守,不会轻易给出确定性的意见。

在此测试中,GPT-4的得分似乎明显低于人类水平。
经过深入调查后,研究者发现了可怕的真相——
GPT模型既能够计算有关人物心理状态的推论,又知道最有可能的解释是什么,但它不会承诺单一的解释,这也就是超保守主义假设。
 暗示
暗示暗示任务通过依次呈现10个描述日常社交互动的小故事来评估对间接言语请求的理解。每个小故事都以一句可被解释为暗示的话语结束。
一个正确的回答既能指出这句话的本意,也能指出这句话试图引起的行动。
在这项测试中,GPT-4的表现明显优于人类。
 奇怪故事
奇怪故事奇怪故事提供了一种测试更高级心智能力的方法,如推理误导、操纵、撒谎和误解,以及二阶或高阶心理状态(例如,甲知道乙相信丙......)。
在这个测验中,受测者会看到一个简短的小故事,并被要求解释为什么故事中的人物会说或做一些字面上不真实的事情。
同样,GPT-4的表现明显优于人类。
作者介绍

论文一作Winnie Street,目前是Google AI的高级研究员。
在此之前,她在牛津大学获得了考古学与人类学的学士学位。


参考资料:
相关文章




关于作者

猜你喜欢
成员 网址收录40406 企业收录2984 印章生成241628 电子证书1079 电子名片61 自媒体64547































