
左:Overcooked Challenge 的关卡1,同时支持单人和双人游戏;右:Overcooked Challenge 的关卡2
作者使用了一系列的大小模型在 Overcooked Challenge 单人游戏上进行了测试,可以明显的看到绝大多数非推理模型在直接决策(Act as System 1)以及推理模型先思考再决策(Long CoT Act as System 2)的情况下都无法得分,即使强如 GPT-4o,也无法超越简单的有限状态机(FSM)。

横轴为得分效率:正得分(即不含扣分)/有效宏操作,纵轴为每局游戏平均得分,圆的大小代表模型每一次决策从输入到输出的平均延时(秒)
这使得我们思考一个问题,模型是否能像人一样,一边不间断地做手上的工作,一边思考更复杂的策略,而不是想一步做一步?
借鉴人类双过程理论(Dual Process Theory),DPT-Agent 通过 System 1 和 System 2 的结合,为 Agent 装上「人脑同款双系统」:
「快脑」System 1—— 条件反射级响应代码即策略(Code-as-Policy):将高频操作(灭火、递食材)固化为有限状态机(FSM)规则,优化初始 FSM 策略;持续输出保障:即使 System 2 在后台思考,System 1 也能按 FSM 中最新策略持续行动,杜绝 “宕机卡顿”,原子动作响应延迟 < 0.1 秒。「慢脑」System 2—— 战略级读心术心智理论(ToM):让 LLM 通过分析玩家动作历史,实时构建人类意图模型(例:「TA 连续取牛肉→今晚主打牛肉汉堡」);异步反思:在「快脑」指挥智能体做菜的同时,「慢脑」根据游戏历史优化策略,如发现「生菜总是不够」,自动调整备菜优先级,边协作边进化。轴为得分效率:正得分(即不含扣分)/有效宏操作,纵轴为每局游戏平均得分,圆的大小代表模型每一次决策从输入到输出的平均延时(秒)
「智能协作实战」:当 DPT-Agent 遇上「偏科队友」
在真实的协作场景中,AI 常需面对能力参差不齐的伙伴 —— 可能是只会切菜的规则机器人,或是专注煎牛排却绝不上菜的「一根筋」AI。DPT-Agent 如何应对?团队设计了残酷的多智能体实验:
极端测试:与「偏科 AI」组队让 DPT-Agent 搭档三类规则 AI(专精切生菜 / 煎牛排 / 组装汉堡)。
为了公平比较,ReAct 和 Reflexion 使用和 DPT-Agent 相同的 System 2 输出方式与动作执行器来实现为 System 1 System 2 框架。
推理模型战胜高延迟:DeepSeek-R1 满血版在 DPT-Agent 框架加持下,相比使用 ReAct 的 - 42.5 分有大幅提升,获得 74.3 分的战绩,逆袭成 MVP, o3-mini-high 相比 o3-mini-medium 和 o3-mini-low 即使延迟增大,也一样呈现能力上升趋势。非推理模型表现也亮眼:DeepSeek-V3 在 DPT_Agent 框架加持下表现与满血 DeepSeek-R1 接近,展现不俗实力。ToM 模块的双刃剑:神助攻案例:当规则 AI 是专注取牛肉的 Agent 时,DeepSeek-R1-70b 驱动的 DPT-Agent 通过 ToM 推断「玩家专注牛肉汉堡」,主动改变策略备好面包 生菜人类持续传递牛肉表明其偏爱处理肉类,所以智能体应专注于其他任务以优化团队合作。当规则 AI 是专注组装汉堡并上菜的 Agent 时,o3-mini-low 驱动的 DPT-Agent 通过 ToM 推断 “玩家专注于组装汉堡并上菜”,及时调整策略为准备所有的食材来进行配合人类玩家优先处理紧急的牛肉订单并进行快速组装,通常专注于组装和提供即食食品。智能体应通过准备熟透的牛肉并迅速传递完成的食材来支持这一点,以确保更顺畅的协作。翻车现场:「ToM 模块是协作上限的钥匙,但锁眼必须匹配模型自身的心智推理能力」。Llama3-70B 可能因自身 ToM 能力薄弱,搭载完整 DPT-Agent 后反而得分下降,没有观察到显著的推断现象关于 ToM 模块的更多研究,尤其是 Agent 和人的双向 ToM 过程,可以参考团队的另一篇工作「Mutual Theory of Mind in Human-AI Collaboration: An Empirical Study with LLM-driven AI Agents in a Real-time Shared Workspace Task」。论文链接:https://arxiv.org/abs/2409.08811「真实人类协作」:主客观均是协作王者
团队在学校内招募了 68 位学生和多智能体实验中所有的 Agent 进行了协作实验,并在先前实验的基础上增加了一个关卡。实验参与者在完全未知 Agent 身份的情况下与所有 Agent 以随机顺序进行实验,对 Agent 进行了协作能力和偏好程度的打分。
DPT-Agent 展现了超强协作能力,得分在两个地图上碾压其他框架,主观协作能力和人类主观偏好得分最高。
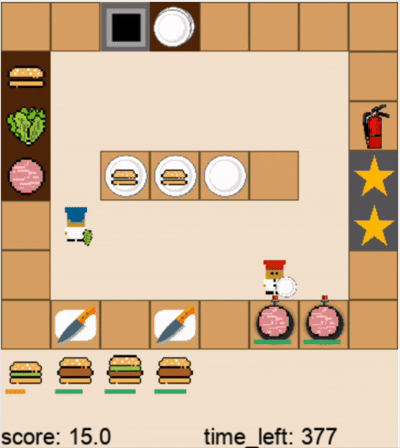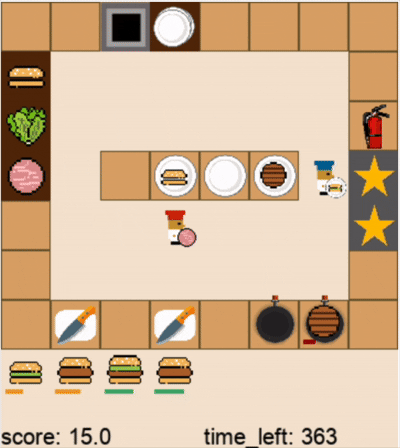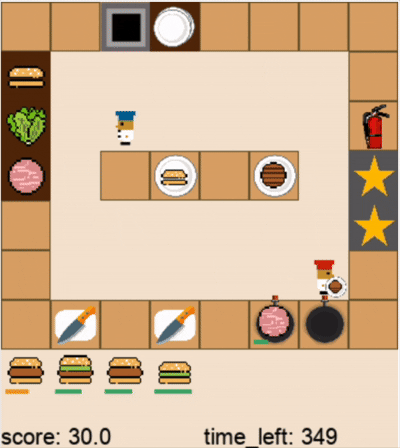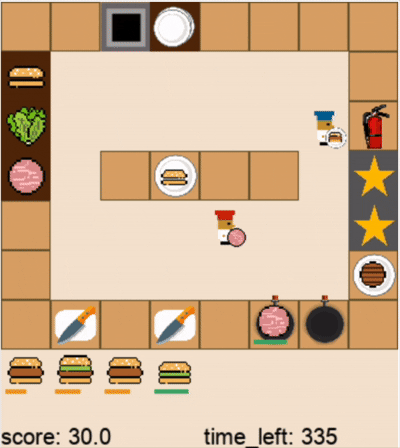
DPT-Agent和人类玩家在关卡1的游戏过程(蓝色帽子为人类玩家,红色帽子为DPT-Agent,视频为2倍速)

与人类协作游戏得分与各Agent的得分贡献率
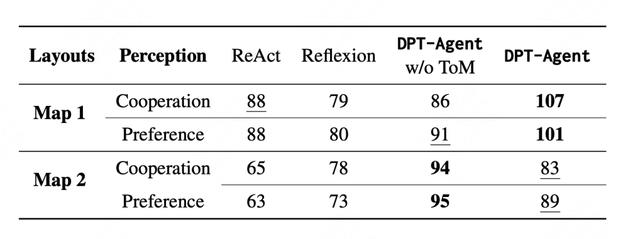
人类主观评价得分
开源评估框架
DPT-Agent 使用的 Overcooked Challenge 环境现已开源,支持 Act,ReAct,Reflexion,ReAct in DPT, Reflexion in DPT, DPT-Agent w/o ToM,DPT-Agent 多种框架下的模型评估,同时公开多达 34 个主流模型包含 DeepSeek-R1 在内的评估结果,评估结果现已在 AGI-Eval 平台上线,未来计划推出人机协作评估,请大家一起来和大模型玩分手厨房!
相关文章





关于作者

猜你喜欢
成员 网址收录40395 企业收录2981 印章生成235566 电子证书1038 电子名片60 自媒体47050































