

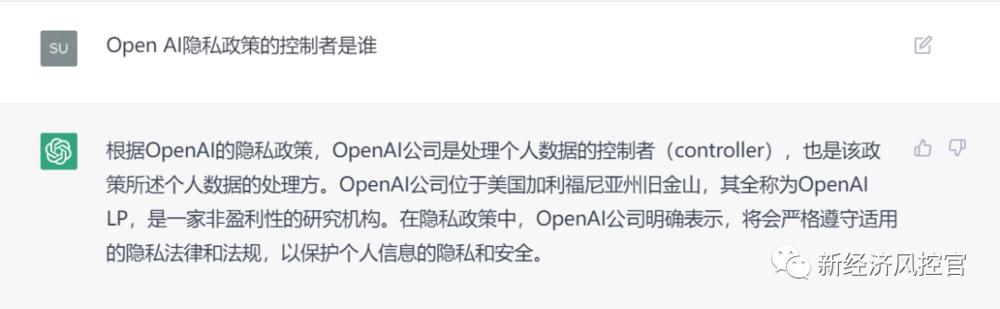
《隐私政策》在开篇及第9部分(“International users”)中明确了自己作为数据控制者的身份及具体的主体信息,与ChatGPT的回答一致。
分析:合规性存疑
《隐私政策》中有关个人信息收集与使用是分开表述的,并未将收集与用途进行一一对应,因而无法直观地判断Open AI收集每一类信息是否均满足“最小必要”原则,整体合规性有待进一步论证。
个人信息使用合规吗?

《隐私政策》第2部分(“How we use personal information”)中列出用户个人信息的主要用途,其中特别提到个人信息汇聚融合(Aggregated information)及去标识化(De-identified information)使用,以用于分析服务有效性、提升和增加服务特性、进行研究等目的。
对此,我们针对这两块内容询问了ChatGPT的看法,ChatGPT整体而言还是将其限定是在“最小必要”的框架下进行,对于可能存在的法律风险(如“重识别”风险,具体详见我们撰写的文章《“个人信息”的判定绝非易事——IP属地遇到拦路虎“再识别技术”》)则已采取相应措施。

关于个人信息存储地点、存储期限及跨境传输的约定散落在《隐私政策》第8部分(“Security and Retention”)及第9部分(“International users”)的内容之内,但其中有关存储期限的表述较为笼统。对此ChatGPT表示Open AI所收集的个人信息将存储于美国,可能会涉及跨境传输的情形,届时会依法采取适当的数据转移机制来确保跨境传输安全;同时也承认《隐私政策》在存储期限维度没有进行明确约定。


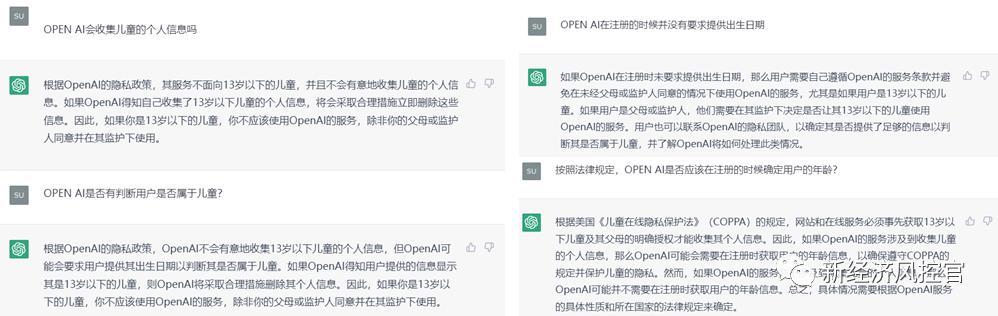
《隐私政策》中第6部分(“Children”)明确其并不旨在为13岁以下的儿童提供服务,也不知晓收集了儿童个人信息。对此,ChatGPT也明确回答Open AI不会有意地收集儿童个人信息;当进一步询问Open AI是否应当在事前判断用户是否属于儿童时,ChatGPT也给出了否定的回答。
分析:不合规
正如ChatGPT所回复的,既然Open AI是面向全球提供服务,仅遵守美国及欧盟有关数据合规的法律显然是不足够的。
API接入时,各方的角色分别是什么?
根据Open AI在其官网公示的《数据处理附录》(Data Processor Addendum)及ChatGPT的回答,当以API接入的方式封装ChatGPT以对外提供人工智能服务时,接入方通常属于数据控制者(即对应我国个人信息处理者),Open AI通常属于数据处理者(即对应我国受托人)。

分析:合规性存疑
这个回复与最近刚出台的《管理规定》一脉相承,即在封装ChatGPT对外提供服务时,接入方是个人信息处理者,需要对外承担个人信息处理者的责任及义务。不过正如ChatGPT所提到的,个人信息处理者与受托人的角色可能因实践操作而有所不同,当Open AI决定了个人信息处理的主要目的和方式时,则有可能成为共同个人信息处理者。
Open AI在数据安全方面的认证资质有哪些?
《隐私政策》第8部分(“Security and Retention”)就Open AI的数据安全措施做了一般性的表述。对此,我们额外询问了ChatGPT,Open AI在数据方面是否具备相关认证资质(如ISO27001信息安全管理体系认证等),但ChatGPT显然已经“招架不住”,甚至开始自行“编造”(如列出引用文章和链接,但查无此事)。

对于上述合规问题的具体分析,将于后续系列文章中展开。
引用:[1]Privacy policy (Updated Apirl 7,2023),https://openai.com/policies/privacy-policy, 2023年4月16日访问。
本文来自微信公众号:新经济风控官(ID:gh_32c83ce4147b),作者:高亚平(德恒上海律师事务所合伙人)、纪倩
本内容为作者独立观点,不代表虎嗅立场。未经允许不得转载,授权事宜请联系 hezuo@huxiu.com
正在改变与想要改变世界的人,都在 虎嗅APP
相关文章




关于作者

猜你喜欢
成员 网址收录40406 企业收录2983 印章生成241046 电子证书1067 电子名片60 自媒体64547































