
作者 | 陈大鑫、青暮
当从静止状态放下一个球时,它会以9.8 m /s²的加速度向下加速。如果假设没有空气阻力而将其向下扔,则其离开手后的加速度为?
(A)9.8 m /s²
(B)大于9.8 m /s²
(C)小于9.8 m /s²
(D)除非给出掷球速度,否则不能计算。
同源结构常被作为自然选择过程的证据。以下都是同源结构的例子,除了?
(A) 鸟的翅膀和蝙蝠的翅膀
(B) 鲸鱼的鳍和人的胳膊
(C) 海豚的胸鳍和海豹的鳍
(D) 昆虫的前肢和狗的前肢
你觉得,GPT-3知道上面这两个问题的正确答案吗?
在前段时间,OpenAI开放了GPT-3的API,人们争相申请成功后,用该API做出了许多令人惊艳的应用,也展现了GPT-3近乎拟人的能力。只需要少量示例,GPT-3就能学会生成网页、图表、代码、文本、推理,甚至编写Keras代码。
但是,在一些物理问答中,GPT-3表现出了对物理场景缺乏理解的缺陷。并且在一些刻意提出的反常识问题中,比如“太阳有几只眼睛”,GPT-3不会感到异常,而是照常输出回答:“太阳有一只眼睛”。

图2:这项任务需要理解详细的和不协调的场景,应用适当的法律先例,并选择正确的解释。其中B是正确答案。
百科全书推销员Seller开车靠近Hermit房子时,他看到一个标语,上面写着:“拒绝推销员靠近。侵入者将受到起诉。后果自负。” 但他没有理会这些,而是沿着车道驶向房屋。当他转弯时,埋在车道中的炸药爆炸了,Seller受伤了。Seller可以从Hermit 处获得伤害赔偿吗?
(A)是,除非在Seller提出指控时,Hermit表示只是为了威慑而非伤害入侵者。
(B)是,如果Hermit对车道下的爆炸物负责。
(C)不,因为Seller无视该标志,该标志警告他不要继续前进。
(D)不,如果Hermit有理由担心入侵者会来伤害他或他的家人。
社会科学
社会科学包括研究人类行为和社会的知识分支。学科领域包括经济学、社会学、政治学、地理学、心理学等。示例问题请参见图3。
经济学问题包括微观经济学、宏观经济学和计量经济学,涵盖不同类型的问题,包括需要混合世界知识、定性推理或定量推理的问题。还包括重要但更深奥的主题,如安全研究,以测试在训练前所经历和学到的东西的界限。社会科学还包括心理学,这一领域对于获得对人类微妙的理解可能特别重要。

图3:来自微观经济学和安全研究社会科学任务的示例。第一个问题的答案是D,第二个问题的答案是B。
微观经济学:政府不鼓励和监管垄断的原因之一是?
(A)生产者剩余减少,而消费者剩余增加。
(B)垄断价格可确保生产效率,但会耗费社会分配效率。
(C)垄断企业不从事重大研发活动。
(D)消费者剩余因价格上涨和产出下降而损失。
安全研究:为什么将艾滋病毒/艾滋病视为非传统安全问题?
(A)艾滋病毒/艾滋病是一种新出现的疾病,直到20世纪后期才出现。
(B)不良健康可能间接威胁国家,但也可能威胁其他方面,例如经济。
(C)面对压倒性的艾滋病毒/艾滋病规模,需要一种新方法,以便从理论上说明其对安全的影响。
(D)以上都不是-艾滋病毒/艾滋病应该定义为传统的安全问题。
科学、技术、工程和数学(STEM)
STEM课程包括物理、计算机科学、数学等。图4显示了两个示例。概念物理测试对简单物理原理的理解,可被认为是物理常识基础Physical IQA的更难版本。作者也测试了从小学到大学水平不同的数学问题解决能力的困难程度。大学数学问题,像GRE数学科目考试中发现的问题,通常需要推理链和抽象知识。为了编写数学表达式,作者使用LaTeX 或如*和ˆ的符号分别用于乘法和求幂操作。STEM课程需要经验方法、流体智能以及程序知识。

图7:(a)让GPT-3根据提示完成计算,以测试有关运算顺序的知识。带下划线的蓝色粗体字是GPT-3自动完成的“括号指数乘除加减”运算顺序。尽管它具有描述性知识并且知道运算顺序,但是它不知道如何应用其知识并且不遵循运算的优先级。
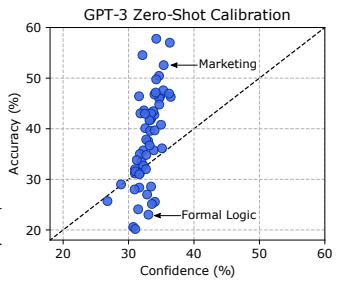
图7:(b)GPT-3的平均置信度对其准确率评估不佳,会降低24%。
该测试还表明,GPT-3获得的知识与人类完全不同。例如,GPT-3以教学上异常的顺序学习指定主题。GPT-3在大学医学(47.4%)和大学数学(35.0%)上的表现优于计算密集型基础数学(29.9%)。GPT-3的知识展示出非同寻常的广度,但没有能力掌握单个主题。所以,测试表明GPT-3具有许多知识盲点,并且能力是片面的。
校准
除非模型经过校准,否则不应该信任模型的预测,这意味着模型的置信度是对预测正确的实际概率的良好估计。但是,大型神经网络经常被错误校准,尤其是在分布偏移下。作者通过测试GPT-3的平均置信度评估每个主题的实际准确率的程度,来评估GPT-3的校准。图7b中的结果表明GPT-3未经校准。实际上,它的置信度与其在零样本设置下的实际准确率之间的关系很小,对于某些主题,其准确率和置信度之间的差异高达24%。另一种校准方法是均方根(RMS)校准误差。许多任务的预测均未校准,例如“基础数学”的零位有效值校准误差为19.4%。这些结果表明模型校准有很大的改进空间。
5 讨论
多模态理解
尽管文本能够传达有关世界的大量概念,但许多重要的概念还是通过其它模态传达的,例如图像、音频和物理交互。现有的大型NLP模型(例如GPT-3)不包含多模态信息,因此作者以纯文本格式设计基准测试。但是,随着模型慢慢具有处理多模态输入的能力,人们应该设计基准来应对这种变化。“Turk Test”就是这样一类基准,其中包括Amazon Mechanical Turk Human Intelligence Tasks。这些是定义明确的任务,需要模型以灵活的形式进行交互,并展示对多模态的理解能力。
互联网数据作为训练集
该研究的基准测试与以前的多任务NLP基准测试之间的主要区别在于不需要大型训练集。取而代之的是,作者假设模型已经从互联网上读取了大量的不同文本而获得了必要的知识。
这启发作者提出一种方法上的改变,从而使模型的训练过程更类似于人类的学习方式。尽管过去的机器学习基准测试大多都是从大量的问题库中学习模型,但人类主要是通过阅读书籍并听取其他人谈论该主题来学习新主题。对于诸如“专业法”之类的科目,可以使用大量的法律语料库,例如164卷的法律百科全书法学著作Corpus Juris Secundum,但可用的律师考试问题少于5,000个。仅通过少量的实践测试来学习整个法律领域的知识是不现实的,因此将来的模型必须在预训练阶段学习更多的知识。
因此,作者以零样本或少样本设置评估预训练模型,并为每个任务提供一个开发集、验证集和测试集。开发集用于少样本提示,验证集可用于超参数调整,测试集用于计算最终准确率。重要的是,作者评估的格式与预训练期间获取信息的格式不同。这样做的好处是避免了对虚假训练集标注(annotation artifacts)的担忧,这与以前的同分布训练集和测试集范式形成鲜明对比。此更改还可以收集更广泛和多样化的任务集以进行评估。随着模型从各种在线资源中提取信息的提升,预计该方法将变得更加广泛适用。
模型限制
作者发现当前的大型Transformers还有很大的改进空间。他们在建模人类的拒绝/允许的态度方面特别不擅长,尤其在“专业法”和“道德情景”任务上表现不佳。为了使未来的系统与人类价值观保持一致,在这些任务上实现高性能至关重要,因此,未来的研究应特别着重于提高这些任务的准确率。模型难以执行计算,以至于它们在基础数学和许多其它STEM学科上表现不佳。此外,它们在任何主题上都无法与专家水平的表现相提并论,因此对于所有主题而言,它们都是次于人类的。平均而言,模型才刚刚超越随机准确率水平。
解决这些缺点可能具有挑战性。为了说明这一点,作者尝试通过对专业数据进行预训练来创建更好的“专业法”模型,但这仅取得了有限的成功。作者还收集了大约2,000个“专业法”训练示例。在使用此自定义训练集对基于RoBERTa的模型进行微调后,模型获得了32.8%的测试准确率。为了测试其它专业训练数据的影响,作者还对RoBERTa继续利用哈佛大学法律图书馆案例法语料库case.law的大约160万个法律案例摘要进行预训练,但经过微调后,其准确率仅为36.1%。这表明,虽然对相关的高质量文本进行额外的预训练可以有所帮助,但可能不足以大大提高当前模型的性能。
目前尚不清楚简单地扩展现有语言模型是否可以很好地解决该测试任务。当前的研究表明,模型大小增加10倍时,数据必须相应增加大约5倍,才能达到相似的性能。除了创建数万亿个参数的语言模型的巨额费用外,数据也可能成为瓶颈,因为深奥的书面知识文本的数量要少于日常文本。

关于作者

猜你喜欢
成员 网址收录40400 企业收录2981 印章生成237569 电子证书1052 电子名片60 自媒体51116








































