大家好,在日常生活工作中我们会和很多文档打交道,今天这期我们将一起看下如何使用LlamaIndex和LangChain来构建一个基于GPT-4的本地文档知识库聊天机器人。

下面开始我们的教程,首先介绍一些本地AI聊天知识库的原理,核心可以分为两部分:
一、数据的摄取/建立索引阶段:这个阶段主要通过 LlamaIndex 和 LangChain 将你的文档转化为矢量数据并建立索引数据;
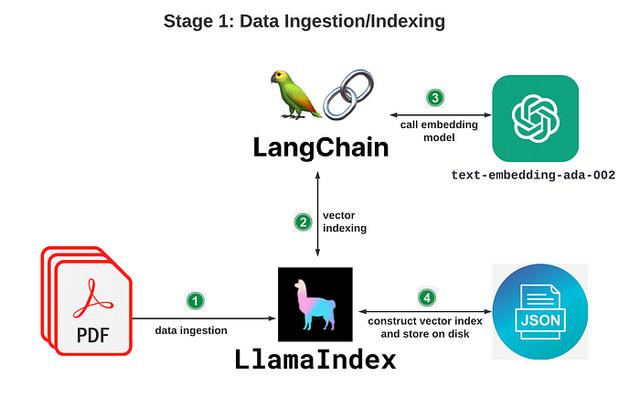
OK,下面我们来看下具体如何实现:
首先需要在本地环境中安装Python,另外需要准备一个OpenAi 的ApiKey,这里因为我的官方账号只有GPT3.5接口所以我用了国内一家代理提供的GPT4接口来进行演示(app4gpt)。
这里简单介绍一下这些库在项目中的作用:
第一个 OpenAi库:
引用的目的有2个:一、通过OpenAI的嵌入模型来完成数据的转化、提取并建立索引;二、我们最后会调用OpenAI的GPT4的模型生成自然语言;
第四个 P Y Pdf是一个免费开源的python PDF库,能够分割,合并,裁剪和转换PDF文件的页面。我们将使用这个库来解析我们的PDF文件。
第五个 Gradio是一个开源Python库,只需要通过几行代码就可以快速的搭建一个机器学习相关的应用程序。
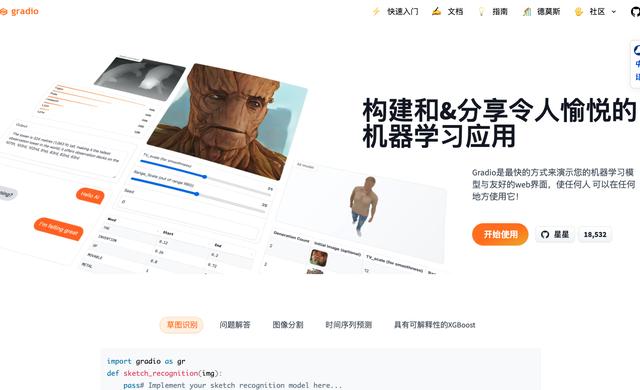
接下来我们需要为项目添加数据源pdf文件,并存放在项目的data目录下,基于这些文档来训练我们的本地知识库聊天机器人。
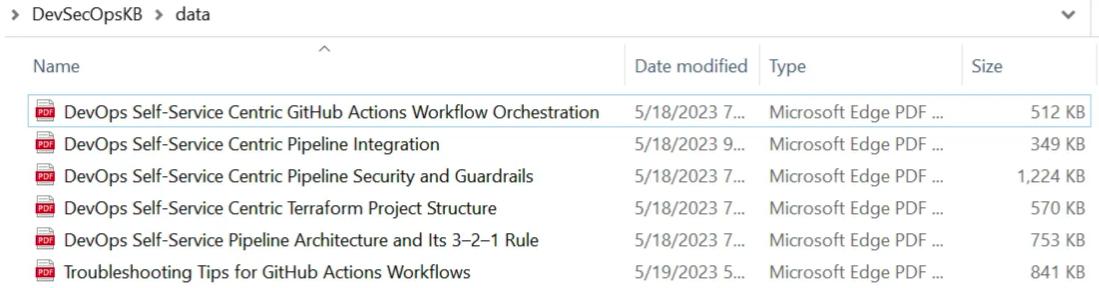
聊天机器人具体实现步骤及主要函数讲解:
1.在ChatDemo文件夹中新建一个Demo 点 Python文件,并导入需要使用的模块和类:
from llama_index import SimpleDirectoryReader, LLMPredictor, PromptHelper, StorageContext, ServiceContext, GPTVectorStoreIndex, load_index_from_storagefrom langchain.chat_models import ChatOpenAIimport gradio as grimport sysimport osimport openai
2.设置OpenAI_API_KEY ,这里由于我们需要使用到gpt4的接口,所以需要先将Base Url改为国内代理的U R L,再填入国内代理提供的key。
openai.api_base = "https://api.app4gpt.com/v1"os.environ["OPENAI_API_KEY"] = 'sk-YOU-API-KEYXXXXXXXXXXXXXXXXXXXXXXXXXXX'
3.上下文环境函数
这个函数主要作用有两方面:一方面主要设置一些约束参数,如输入的最大数量、输出的数量、块重叠的最大值和文本块大小的限制。另外,它还实例化了两个类,即PromptHelper 和 L L M Predictor。
PromptHelper主要负责生成适当的提示语句,使模型能够理解并有效地响应我们的查询。而L L M Predictor则负责调用gpt-4语言模型来生成我们期望的回答。
def create_service_context(): #constraint parameters max_input_size = 4096 num_outputs = 512 max_chunk_overlap = 20 chunk_size_limit = 600 #allows the user to explicitly set certain constraint parameters prompt_helper = PromptHelper(max_input_size, num_outputs, max_chunk_overlap, chunk_size_limit=chunk_size_limit) #LLMPredictor is a wrapper class around LangChain's LLMChain that allows easy integration into LlamaIndex llm_predictor = LLMPredictor(llm=ChatOpenAI(temperature=0.5, model_name="gpt-3.5-turbo", max_tokens=num_outputs)) #constructs service_context service_context = ServiceContext.from_defaults(llm_predictor=llm_predictor, prompt_helper=prompt_helper) return service_context
4.数据提取/索引建立函数
该函数负责提取pdf数据,并根据我们知识库中的内容来创建并保存索引,来用于后面的数据查询场景。
主要功能有以下几点:
·这个函数中通过Simple Directory Reader从指定的目录路径加载数据;
·通过GPT Vector Store Index将文档建立为索引;
·最后将转化完的索引存放在默认的storage文件夹下,并返回index索引对象。
def data_ingestion_indexing(directory_path): #loads data from the specified directory path documents = SimpleDirectoryReader(directory_path).load_data() #when first building the index index = GPTVectorStoreIndex.from_documents( documents, service_context=create_service_context() ) #persist index to disk, default "storage" folder index.storage_context.persist() return index
5.查询函数
通过这个函数我们可以从磁盘上的存储位置来加载索引。然后查询input中输入文本的相关索引,最终返回查询后的内容。
def data_querying(input_text): #rebuild storage context storage_context = StorageContext.from_defaults(persist_dir="./storage") #loads index from storage index = load_index_from_storage(storage_context, service_context=create_service_context()) #queries the index with the input text response = index.as_query_engine().query(input_text) return response.response
6.G R.Interface函数
通过这个函数使用Gradio库创建一个交互式的Web用户界面。它将上面的data_querying函数作为用户输入的处理函数,并设置了输入框和输出框的一些属性。
iface = gr.Interface(fn=data_querying, inputs=gr.components.Textbox(lines=7, label="Enter your question"), outputs="text", title="chatpdf-demo")
7.最后调用之前的数据索引提取函数, 并传入"data"作为参数,这个data就是我们存储pdf文档的地址,最终会返回一个index索引的实例。
index = data_ingestion_indexing("data")
到这里本地知识库GPT4机器人就搭建好啦,完整的代码链接我会放在评论区,大家也可以通过私信我来索取代码。
接下来我们通过终端来运行一下并看看效果。
python3 kb.py
在浏览器中打开本地URL可以看到这个web应用程序,我们向机器人提出一个和文档内容比较相关的问题,以此来对比一下原版GPT和自定义知识库GPT答案的区别;
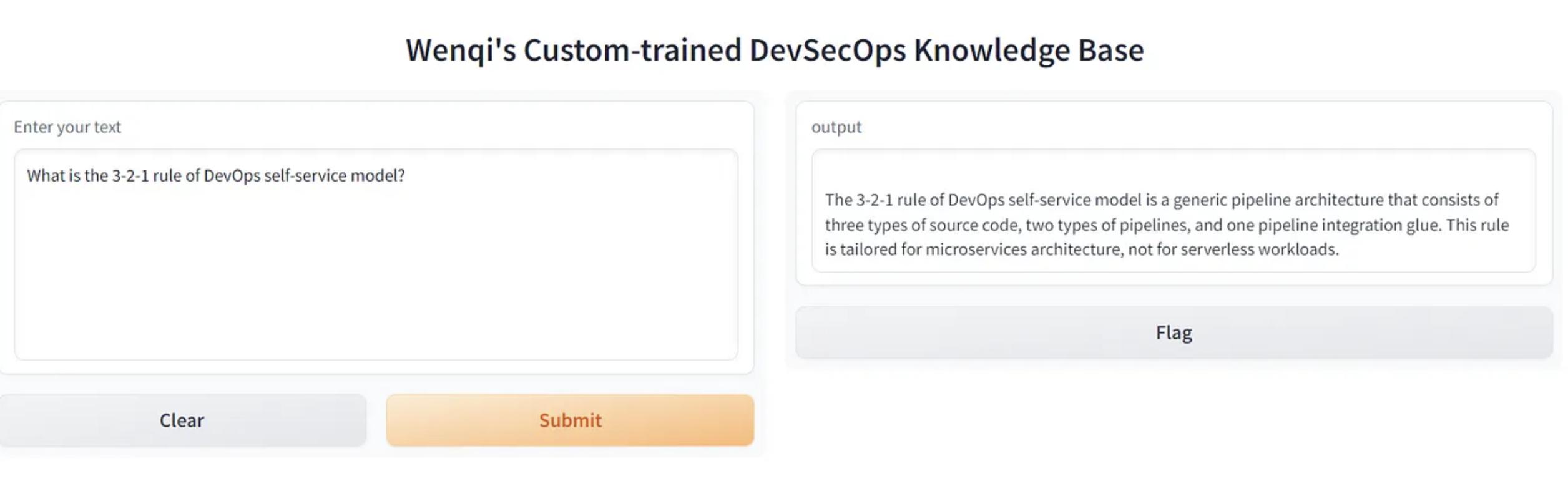
可以看出自定义知识库GPT 由于我们喂了更多相关的文档资料,所以他的回答能更精准有效,给出的回答也是更专业一些。
好了本期的视频就到这里,如果你觉得本视频能对你带来帮助的话还请一键三连哦,我们下期再见!
相关文章




关于作者

猜你喜欢































