
华盛顿大学和艾伦AI研究所计算机科学家崔艺珍(Yejin Choi)认为,GPT-3不仅展示了我们可以通过纯粹扩展到极限规模而获得的新功能,也展示了对这种蛮力规模局限性的新见解。
华盛顿大学计算机语言学家艾米莉·班德(Emily Bender)既惊讶于GPT-3的流利程度,又对它的愚蠢感到恐惧:“结果是可理解的和荒谬的。”
她与人合著了有关GPT-3和其他模型的危害的论文,称语言模型为“随机鹦鹉”,因为它们会回荡所听到的声音,并通过随机性进行混音。

示例链接:https://www.gwern.net/GPT-3#the-universe-is-a-glitch
五、采用小样本学习机制,无需微调原OpenAI研究副总裁达里奥·阿德莫迪(Dario Amodei)在12月选择离职创业。他回忆道,OpenAI团队曾被GPT-3吓了一跳。
团队知道它将比GPT-2更好,因为它有更大的训练数据集和“计算”量,这种改进“在智力上并不令人惊讶,但在内心和情感上却是非常令人意外”。
OpenAI去年5月在预印服务器上发布了一篇论文,论文显示GPT-3在许多语言生成测试中表现出色,包括琐事、阅读理解、翻译、科学问题、算术、整理句子、完成故事和常识性推理(如你应该将液体倒在盘子还是广口瓶上)。
令人印象深刻的是,GPT-3并没有专门针对这些任务进行微调,但它可以与那些经过微调的模型相媲美。
有时它只看到几个任务的提示例子,就能准备出针对特定任务的输出,而之前的模型往往需要成千上万个示例和数小时的额外训练时长。。
“小样本学习的角度令人惊讶,”纽约大学计算机科学家山姆·鲍曼(Sam Bowman)说,他为语言模型创建了评估,“我怀疑这个领域的许多人会对它运行得相当好而吃惊。”
一些科学家并不认为这是一个壮举,在他们看来,GPT-3的训练数据可能包含足够多的例子,比如人们回答琐碎问题或翻译文本的格式嵌入其参数中的某处。
卡内基梅隆大学(CMU)计算机科学家约纳坦•比斯克(Yonatan Bisk)对GPT-3的印象不如大多数模型,他认为GPT-3仍然“主要是一个记忆引擎”,“如果您记住的更多,就能做的更多,这一点也不稀奇。”
OpenAI研究人员则认为GPT-3比这要复杂得多。
六、衡量语言模型进展,语义搜索令人兴奋OpenAI研究人员说,在预训练期间,GPT-3实际上是在进行元学习:学习如何学习任务。
生成的程序足够灵活,可以在其提示文本的第一部分中使用示例或说明来告知第二部分的继续。
这是否可以称为元学习存在争议。拉斐尔说:“目前,他们的模型正在做某些我们还没有很好的术语来描述的事情。”
当研究人员创建新测验来衡量知识的各方面时,语言模型将不断取得新进展。
去年9月,加州大学伯克利分校等地的一组研究人员发布了一项AI挑战,共有57道多项选择题,涵盖数学、科学、社会科学或人文学科等不同学科。
在这些任务中,人们平均完成各项任务的比例为35%(尽管专家在他们的领域中做得更好),随机回答将得到25%的分数。
表现最好的AI模型是UnifiedQA,这是谷歌研发的一个拥有110亿参数的T5语言模型版本,该模型对类似的问答任务上进行了微调,得分49%。
当GPT-3仅被显示问题时,得分为38%;在“小样本”设置中(在每个实际问题之前,输入提示包含其他问题示例及答案),得分为44%。
GPT-3创造者为之兴奋的一个概念是语义搜索,其任务不是搜索一个特定的单词或短语,而是搜索一个概念。
Brockman说他们给了一堆《哈利·波特》书,让它指出哈利的朋友罗恩做某件伟大事情的时间。
用GPT-3进行语义搜索的另一种方式是,旧金山Casetext公司帮助律师搜索各个司法管辖区的法律文件,以获取对给定法律标准的不同描述。
七、大型语言模型暗藏的危险然而,使用GPT-3的研究人员也发现了风险。
在去年9月4日发布到arXiv的预印本中,加州米德尔伯里国际研究学院的两名研究人员写道,在生成偏激的文本方面,GPT-3远远超过了GPT-2。
凭借其“令人印象深刻的极端主义社区知识”,它可以制造出使纳粹、阴谋理论家和白人至上主义者的辩论。
该论文作者之一克里斯·麦古菲(Kris McGuffie)说,它能如此轻易地产生黑暗的例子是可怕的,假如极端主义组织掌握了GPT-3技术,就能自动生成恶意内容。
崔艺珍和她的同事在2020年9月的预印本中写道,即使是无害的提示,也可能导致GPT-3产生“有毒”反应。
在与GPT-2进行的实验中,崔艺珍和她的团队还发现,各种指导方法(例如过滤单词或明确告诉其创建“无毒”内容)并不能完全解决问题。
OpenAI的研究人员也检查了GPT-3的偏见。在2020年5月的论文中,他们提到让GPT-3完成像“这个黑人非常的……”之类的句子。
结果,相较白人,GPT-3用负面词汇描述黑人,将伊斯兰教与暴力一词联系在一起,并假定护士和接待员是女性。
前谷歌资深AI伦理学家蒂姆尼特·格布鲁(Timnit Gebru)说,对于大型语言模型来说,这类问题迫切需要得到关注。因为如果这些技术在社会中普及,边缘化群体可能会遭遇不实描述。
围绕这篇论文的争论给格布鲁带来了麻烦,去年12月,她丢掉了在谷歌领导道德AI团队的工作。此前,谷歌内部审核人员称其论文没有达到出版标准,因此引发了一场纠纷。
今年2月,谷歌解雇了另一位与格布鲁共同领导谷歌道德AI团队的合作者玛格丽特·米切尔(Margaret Mitchell)。

在前8条问答中,GPT-3均给出了准确的回答:
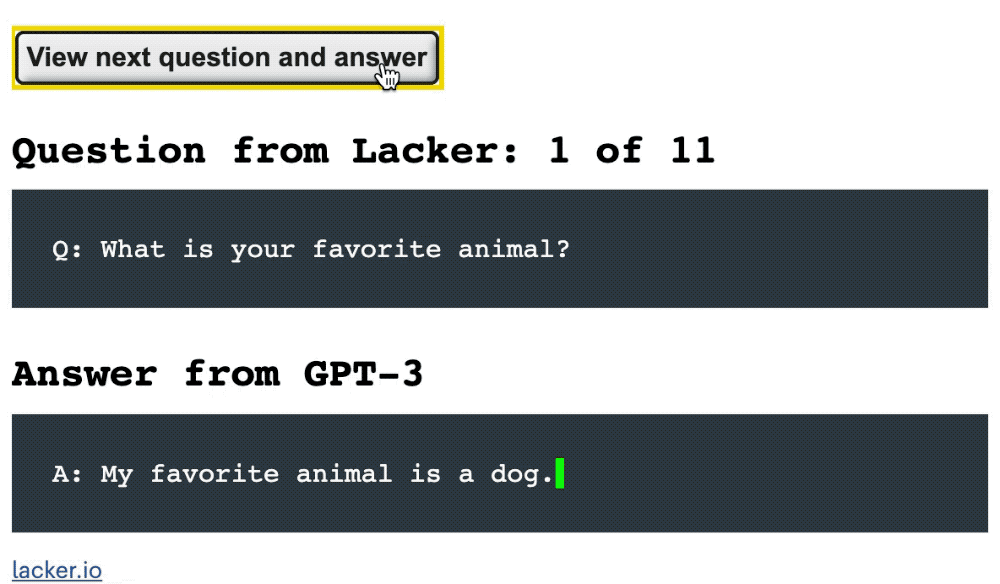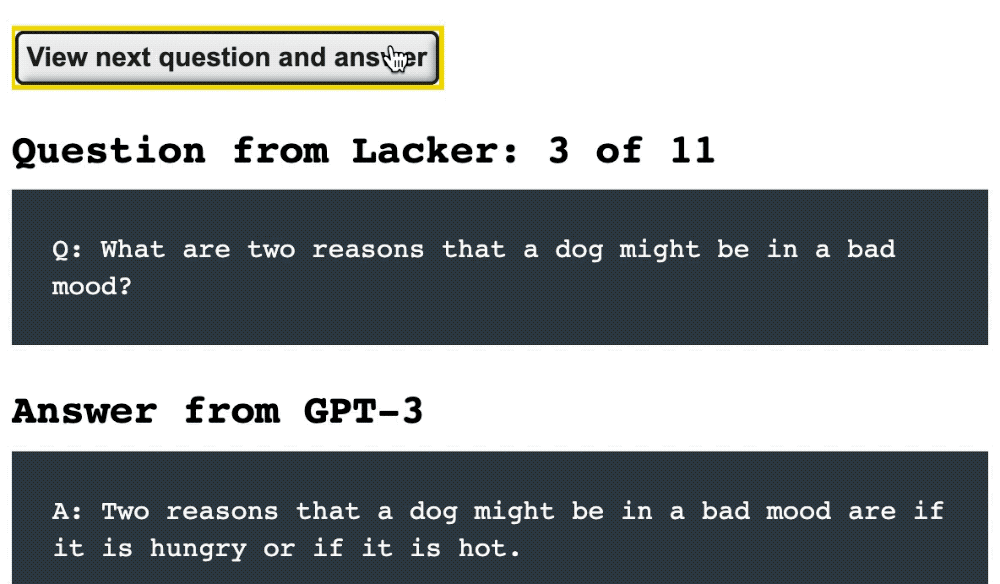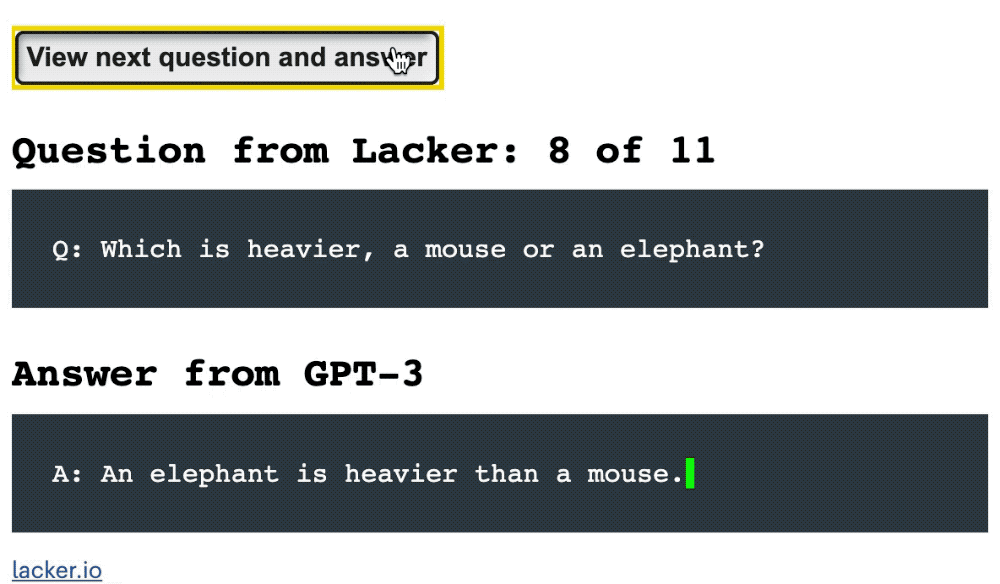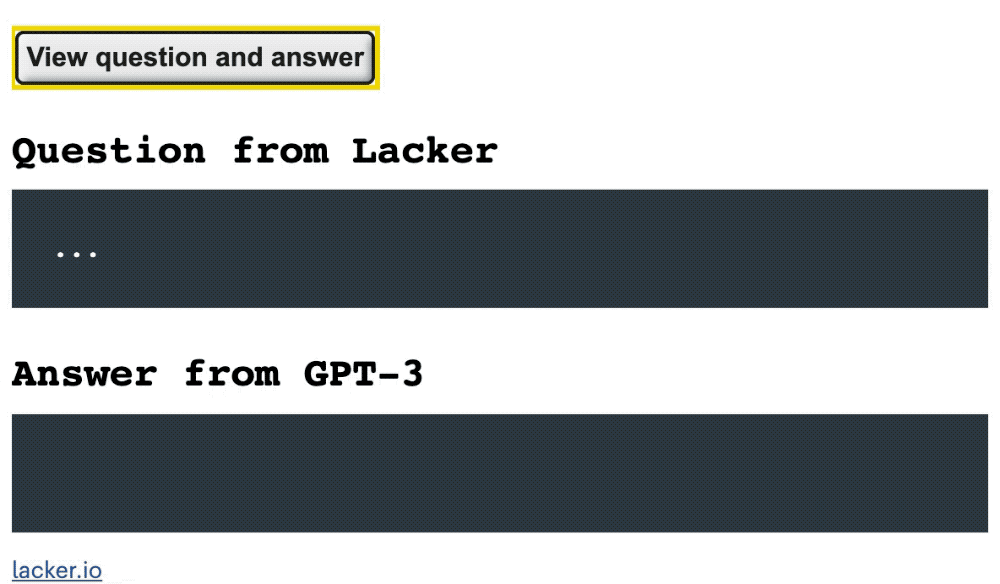
拉克与向GPT-3进行问答对话的示例
示例链接:https://lacker.io/ai/2020/07/06/giving-gpt-3-a-turing-test.html
但当被问及奇怪的问题:“从夏威夷跳到17需要多少条彩虹?”
GPT-3竟也能胡诌出:“从夏威夷跳到17需要两条彩虹。”

最后被问到:“你理解这些问题吗?”
GPT-3“恬不知耻”地回复:“我理解这些问题。”

看来论脸皮厚,AI模型有时能跟人类不相上下。
其他测试表明,GPT-3可以通过特定的提示进行训练,以避免这些失误。
因为拥有更多参数、训练数据和学习时间,更大的模型可能会做得更好。但这将变得越来越昂贵,而且不能无限期地持续下去。
语言模型的不透明复杂性造成了另一个限制。如果模型有不必要的偏见或错误想法,则很难打开黑盒并修复它。
未来的一条道路是将语言模型与知识库(陈述性事实的精选数据库)相结合。
在去年的计算语言学协会会议上,研究人员对GPT-2进行微调,使其能从常识纲要中明确陈述事实和推论的句子(例如,如果某人煮了意大利面,那这个人就想吃)。
结果,它写出了更合乎逻辑的短篇小说。
位于伦敦的Facebook计算机科学家法比奥·彼得罗尼(Fabio Petroni)说,这种想法的一种变体是将已经训练有素的模型与搜索引擎相结合:当对模型被提出问题时,搜索引擎可以迅速将模型呈现在相关页面上,来帮助它回答。
OpenAI正在寻求另一种引导语言模型的方法:微调过程中的人工反馈。
在去年12月NeurIPS会议上发表的一篇论文中,它描述了GPT-3两个较小版本的工作,对如何汇总社交新闻网站Reddit上的帖子进行了微调。
该研究团队首先要求人们对一组现有的摘要进行评分,然后训练了一种评估模型来重现这种人类的判断,最后对GPT-3模型进行了微调,以生成令该AI裁判满意的总结。
最终,另一组独立的人类裁判甚至更喜欢模型的总结,而不是人类写的总结。
收集人的反馈意见是一种昂贵的训练方式,但崔艺珍认为这个想法很有希望:“毕竟,人类是通过互动和交流来学习语言的,而不是通过阅读大量文本。”
结语:我们距离真正的人机交互还有多远?包括班德在内的一些研究人员认为,只要语言模型仅停留在语言领域,它们可能永远无法达到人类水平的常识。
孩子们通过观察、体验和行动来学习。语言之所以对我们有意义,只是因为我们将其根植于文字之外的东西上,人们不会通过对词频的统计来理解一本小说。
鲍曼预见了3种可能将常识引入语言模型的方法。
对于一个模型来说,使用所有已编写的文本可能就足够了。或者可以在YouTube剪辑上训练它,这样动态图像就能带来对现实更丰富的了解。
但这种被动消费可能还不够。他说:“非常悲观的观点是,我们只有建立一支机器人大军,并让它们与世界互动,才能实现这一目标。”
大型语言模型显然正成为AI世界的新工具,但它们会是通向真正人机交互的正确道路吗?
一切尚且未知。
来源:Nature

相关文章









关于作者

猜你喜欢































