 对嵌入模型延迟的半科学调查
对嵌入模型延迟的半科学调查正如我们上文所讨论的,缓慢的文本生成影响用户体验,而生成文本的关键任务之一就是使用语义搜索查找相关内容。虽然我们应该考虑嵌入模型的成本、内存使用和实施的便利性,但这次调查仅关注嵌入的速度,以及在有的情况下,对语义相似性搜索任务的MTEB 基准性能。
我们测试了两个嵌入 API 服务和几个由 sentence-transformers包支持的开源嵌入模型。我们选取的开源模型代表了在 MTEB 基准测试中得分高,且在 CPU 上表现良好的模型族。还有许多其他模型,你应该根据你的使用场景进行实验,以基准作为指导,而非铁律。
模型部署类型MTEB 检索分数OpenAI text-embedding-ada-002API 服务49.25Google Vertex AI textembedding-gecko@001API 服务未知 - 2023年5月推出sentence-transformers/gtr-t5-xl本地 CPU 执行47.96sentence-transformers/all-MiniLM-L12-v2本地 CPU 执行42.69sentence-transformers/all-MiniLM-L6-v2本地 CPU 执行41.95API 测试在 GCP 和 AWS 上进行,这符合了当今许多应用的场景。本地模型在几个云实例和我的 MacBook Pro M1(配备16GB RAM)上进行了测试。详细信息请见下文。
 结果
结果摘要:Google 的新嵌入 API 比 OpenAI 的快得多,而本地 CPU 上的开源模型最快。Google 的模型尚无检索基准,但 OpenAI 的模型在 MTEB 上得分最高。如果延迟是你的关注点,你可以考虑 Google 或开源模型。
OpenAI 的 text-embedding-ada-002模型是许多开发者的首选。由于应用程序常常使用 OpenAI 的模型,因此开发者使用同样的 API 来嵌入文档是合理的。OpenAI 最近也大幅降低了这个 API 的价格。
事实证明,无论是从 AWS 还是 GCP 测量,OpenAI 嵌入 API 的延迟显著高于 Google 新的 textembedding-gecko@001模型(仅从 GCP 测量)。
OpenAI 的性能波动较大——许多人都经历过在一些时候 OpenAI 的 API 扩展性差的情况。使用 Azure OpenAI Service 运行在 Microsoft Azure 中的应用,模型的延迟可能会更低。
 嵌入模型性能的效果可能因人而异
嵌入模型性能的效果可能因人而异sentence-transformers 团队已经创建了大量不同的模型,并且有充分的理由。每个模型都具有不同组合的性能特性,并且用于不同的用途。口语,句子长度,向量宽度,词汇量和其他因素都会影响模型的性能。有些模型可能对某个领域的表现比其他模型更好。在选择模型时,使用 MTEB 和其他基准作为指导是值得的,但一定要用自己的数据进行实验。
 测试方法
测试方法我们对每个模型的嵌入速度进行了50次迭代的抽样测试。嵌入的文本相对较短,旨在代表 LLM-based 应用在构建提示时对向量数据库进行搜索的类型。
texts = ["Visa requirements depend on your nationality. Citizens of the Schengen Area, the US, Canada, and several other countries can visit Iceland for up to 90 days without a visa."]
测试句子
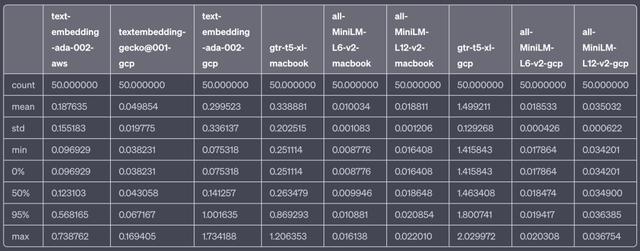
模型延迟数据表
测试在以下基础设施上/从以下基础设施运行:
GCP:位于 us-central1 的 n1-standard-4(4 vCPU,15 GB RAM)实例
AWS:位于 us-west-2 的 ml.t3.large(2vcpu 8GiB)实例
我的 MacBook Pro 14" M1,拥有 16GB 的 RAM
在所有实验中,pytorch 只使用 CPU。
使用的软件包括:
JupyterLab
sentence-transformers 2.2.2
pytorch 2.0.1
Python 3.10 和 3.11
你认为 OpenAI 是目前最好的选择吗?为什么?欢迎发表你的看法和理由。
参考链接
首字节响应时间:https://en.wikipedia.org/wiki/Time_to_first_byte?ref=getzep.com
索相关信息:https://blog.langchain.dev/retrieval/?ref=getzep.com
近似最近邻:https://en.wikipedia.org/wiki/Nearest_neighbor_search?ref=getzep.com
语义搜索:https://www.sbert.net/examples/applications/semantic-search/README.html?ref=getzep.com
许多不同的嵌入模型:https://huggingface.co/spaces/mteb/leaderboard?ref=getzep.com
MTEB 基准性能:https://huggingface.co/spaces/mteb/leaderboard?ref=getzep.com
sentence-transformers:https://www.sbert.net/?ref=getzep.com
大幅降低了:https://openai.com/blog/function-calling-and-other-api-updates?ref=getzep.com
Azure OpenAI Service:https://azure.microsoft.com/en-us/products/cognitive-services/openai-service?ref=getzep.com
Langchain 示例:https://www.getzep.com/text-embedding-latency-a-semi-scientific-look/#using-sentencetransformer-models-with-langchain
大量不同的模型:https://huggingface.co/sentence-transformers?ref=getzep.com
HuggingFace:https://huggingface.co/?ref=getzep.com
sentence_transformers:https://pypi.org/project/sentence-transformers/?ref=getzep.com
相关文章








关于作者

猜你喜欢































