美国心理学家测试了大型GPT-3语言模型通过类比解决不熟悉任务的能力。这是确定人的智力发展的经典方法,神经网络算法以意想不到的方式展现了自己。在 Raven 标准渐进矩阵适应测试中,他比大学高年级学生得到了更多正确答案。

《机械姬》剧照 (2014)
让神经网络做一些原本没有打算做的事情是一种有趣的娱乐,在开放像ChatGPT 这样的语言模型之后,几乎每个互联网用户都会遇到这种娱乐。然而,这样的行为可能有完全科学的理由。科学家们正在测试生成人工智能的能力极限,并寻找理解人类思维的方法。
也许GPT-3系列算法最令人印象深刻的是它们能够用最少的示例(零样本)解决某些新问题。最主要的是用文字描述问题。
这种思维机制——研究一两个样本,与一种新的、完全陌生但相似的情况进行类比,并找到出路——被称为类比推理。这是指“推理”是思维的一部分,而不是语言表达。人们相信这是人类的独特特征。也许也是一些智力最发达的动物物种。
加州大学洛杉矶分校 ( UCLA ) 的研究人员想知道GPT-3是否真的可以通过类比进行推理。为此,他们选择了模型在训练期间绝对不会遇到的任务。
科学家们使用 Raven 的标准渐进矩阵对经过时间考验的测试卡进行了改编,用于基于文本的人工智能。

基于 Raven 标准渐进矩阵原理构建的问题示例
这些是九个元素的一系列图像,分成三组,但第九个单元缺失。要求受试者从多个选项中选择正确答案。形状具有多个属性,这些属性在每一行中根据一组规则发生变化。要正确回答,您需要查看前两行,确定规则,并在进行类比后将其应用到第三行。这在语言上并不容易,但在视觉上却很容易被感知(见图)。接下来的每一项任务,难度都会增加。
由于GPT-3不是多模态模型,即它只能处理文本,因此矩阵已进行了调整,但原理保持不变。对照组是加州大学洛杉矶分校的大学生。他们输给了人工智能。
学生们给出的正确答案略低于 60%(正常水平),GPT-3 - 80%(高于人们的平均水平,但在正常范围内)。正如该研究的作者指出的那样,该算法犯了与人类相同的错误。换句话说,决策过程很可能非常相似。
除了Raven矩阵之外,研究人员还给出了来自美国标准化入学考试(SAT)的算法任务。它的大多数变体从未在公共领域发布过,因此 GPT-3 很可能也不熟悉它们。
该模型在“仇恨”的“爱”与这个词的“财富”相同,什么?(正确答案是“贫穷”)。因此,算法必须明白在这种情况下需要找到反义词,而无需直接指示。
正如预期的那样,GPT-3很好地解决了更困难的问题,其中必须在整个句子或段落之间进行类比。但模型不出所料地陷入了困境,那就是空间思维任务。
即使你详细描述了这个问题,比如“将软糖从一个碗转移到另一个碗的最佳方法是什么——用管子、剪刀或胶带”,算法也会提供无意义的文本作为回应。
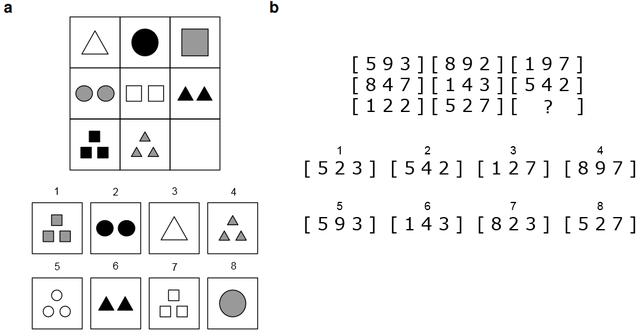
研究中使用的测试样本。左边 (a) 是标准 Raven 渐进矩阵的变体之一,右边 (b) 是其同构(根据同一组规则构建)文本格式的类似物 。
美国心理学家进行的一项研究在一个新的层面上提出了这个问题:大型语言模型是否模仿了人类思维的许多方面,或者我们面临着一种全新的思维方式?在第二种情况下,与著名的哲学概念“车里的幽灵”的类比不言而喻。根据他的一种解释,一个相当复杂的人工系统(机器)可以获得新的不可预见的特性,从外部看这些特性与人类意识无法区分。
这项科学工作有两个重大局限性,其作者正确地指出了这一点。首先,尽管研究人员做出了努力,但并不能保证GPT-3在训练过程中遇到与上述类似的任务。该模型不太可能是针对渐进 Raven 矩阵的文本表示进行训练的。最重要的是,可以在训练数据集中找到SAT 的一些变体。
第二个问题由此而来:科学家无法进入模型的“内部”,这就是为什么它的“思考”过程是一个黑匣子。这阻碍了神经科学的发展。
一篇详细介绍该研究的科学文章发表在《自然人类行为》杂志上。其预印本(未经审查的版本)可在arXiv门户网站上的公共领域获取。
相关文章









关于作者

猜你喜欢
成员 网址收录40400 企业收录2981 印章生成237605 电子证书1052 电子名片60 自媒体51891































