编辑:好困 桃子
【新智元导读】ChatGPT能力解禁,还是加入插件功能后,性能得到了强化。所有大模型皆是如此。面壁智能给大模型接入16000 真实API,性能匹敌ChatGPT。这段时间,开源大语言模型(LLM)可谓是进步飞快,像是 LLaMA 和 Vicuna 等模型在各种语言理解、生成任务上展现了极佳的水平。
然而,当它们面对更高级别的任务,例如根据用户指令使用外部工具(API)时,仍然有些力不从心。
为了解决这个问题,面壁智能联合来自 TsinghuaNLP、耶鲁、人大、腾讯、知乎的研究人员推出 ToolLLM 工具学习框架,加入 OpenBMB 大模型工具体系「全家桶」。

论文链接:https://arxiv.org/pdf/2307.16789.pdf
数据与代码链接:https://github.com/OpenBMB/ToolBench
开源模型下载链接:https://huggingface.co/ToolBench
ToolLLM 框架包括如何获取高质量工具学习训练数据、模型训练代码和模型自动评测的全流程。
其中,作者构建了 ToolBench 数据集,该数据集囊括 16464 个真实世界 API。
目前 ToolLLM 的所有相关代码均已开源,以下是作者训练的 ToolLLaMA 的与用户交互对话并实时进行推理的演示:
ToolLLM 框架的推出,将有助于促进开源语言模型更好地使用各种工具,增强其复杂场景下推理能力。
不仅可以协助研究人员更深入地探索 LLMs 的能力边界,也为更广泛的应用场景敞开了大门。
ToolLLM 研究背景
工具学习的目标是让LLM能给定用户指令与各种工具(API)高效交互,从而大大扩展LLM的能力边界,使其成为用户与广泛应用生态系统之间的高效桥梁。

ToolBench与之前相关工作的对比情况
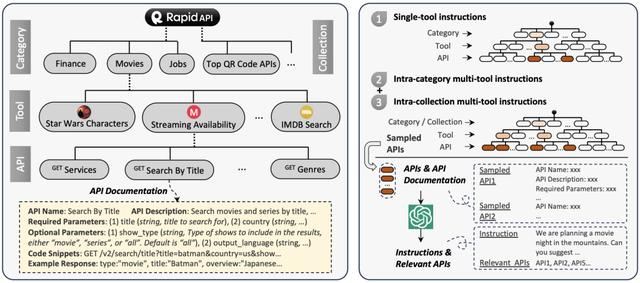
ToolBench 的构建包括三个阶段:API 收集,指令生成和解路径标注:
01 API收集API 收集分为 API 爬取、筛选和响应压缩三个步骤。
API 爬取:作者从 RapidAPI Hub 上收集了大量真实多样的 API。RapidAPI 是一个行业领先的 API 提供商,开发者可以通过注册一个 RapidAPI 密钥来连接各种现有 API。所有 RapidAPI 中的 API 可以分为 49 个类别,例如体育、金融和天气等;每个类别下面有若干工具,每个工具由一个或多个 API 组成。
API 筛选:作者对在 RapidAPI 收集到的 10,853 个工具(53,190 个 API)基于能否正常运行和响应时间、质量等因素进行了筛选,最终保留了3,451 个高质量工具(16,464个API)。
API 响应压缩:某些 API 返回的内容可能包含冗余信息导致长度太长无法输入 LLM,因此作者对返回内容进行压缩以减少其长度并同时保留关键信息。基于每个API的固定返回格式,作者使用 ChatGPT 自动分析并删除其中不重要信息,大大减少了 API 返回内容的长度。
02 指令生成
其中 表示真实的 API 响应。每个动作包括了调用的 API 名称,传递的参数和为什么这么做的「思维过程」。
为了利用 ChatGPT 新增的函数调用(function call)功能,作者将每个 API 视为一个特殊函数,并将其 API 文档放入 ChatGPT 的函数字段来让模型理解如何调用 API。
此外,作者也定义了「Give Up」和「Final Answer」两种函数标识行为序列的结束。

总而言之,DFSDT 算法显著提升了模型推理能力,增加了解路径标注的成功率。
最终,作者生成了 12000 条指令-解路径数据对用于训练模型。
ToolEval 模型评估
为了确保准确可靠的工具学习性能评测,作者开发了一个名为 ToolEval 的自动评估工具,它包含两个评测指标:通过率(Pass Rate)和获胜率(Win Rate)。
通过率是指在有限步骤内成功完成用户指令的比例;获胜率则基于 ChatGPT 衡量两个不同解路径的好坏(即让 ChatGPT 模拟人工偏好)。
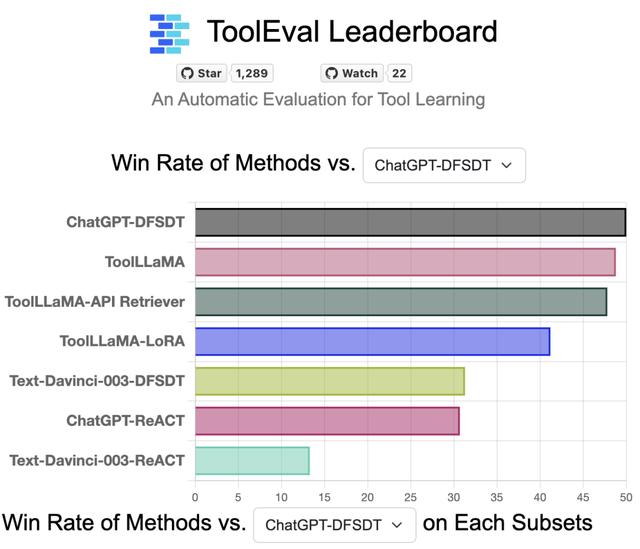
根据上图显示,ToolLLaMA 在 pass rate 和 win rate 上显著优于传统的工具使用方法 ChatGPT-ReACT,展现出优越的泛化能力,能够很容易地泛化到没有见过的新工具上,这对于用户定义新 API 并让 ToolLLaMA 高效兼容新 API 具有十分重要的意义。
此外,作者发现 ToolLLaMA 性能已经十分接近 ChatGPT,并且远超 Davinci, Alpaca, Vicuna 等 baseline。
将API检索器与ToolLLaMA结合
在实际情况下用户可能无法从大量的 API 中手动推荐和当前指令相关的 API,因此需要一个具备 API 自动推荐功能的模型。为解决这个问题,作者调用 ChatGPT 自动标注数据并依此训练了一个 sentence-bert 模型用作 dense retrieval。
为了测试API检索器的性能,作者比较了训练得到的 API 检索器和 BM25、Openai Ada Embedding 方法,发现该检索器效果远超 baseline,表现出极强的检索性能。
此外,作者也将该检索器与 ToolLLaMA 结合,得到了更加符合真实场景的工具使用模型 pipeline。

相关文章









关于作者

猜你喜欢
成员 网址收录40400 企业收录2981 印章生成237605 电子证书1052 电子名片60 自媒体51891































