本创作是本人在今日头条的原创首发内容,拒绝任何人任何形式搬运到其它平台发布!阅读此文前,诚邀您点击一下“关注”按钮,方便以后持续为您推送此类文章。
【导语】
近期,英伟达引发了AI圈的一次轰动,以其最新研发的H100集群在MLPerf训练基准测试中刷新了多项记录,令人瞩目。这个集群在大语言模型任务中表现尤为突出,其加速性能几乎呈线性增长,这意味着集群内GPU之间的通信效率非常高。
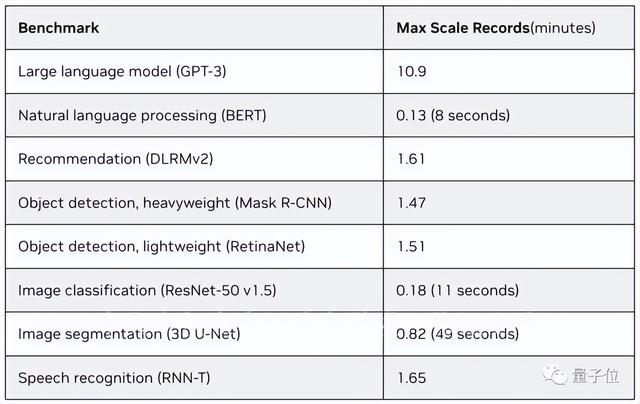
在这次MLPerf测试中,H100集群以其强悍的性能成绩吸引了众多目光,不仅是唯一一个参加了全部八项测试的集群,而且还刷新了单节点加速记录。相较于6个月前的测试数据,单个DGX H100系统在各项任务中的平均提速高达17%,在某些任务中甚至能达到3.1倍的加速效果,这些都得益于H100集群自身的卓越性能和其依赖的高效加速网络。
H100的强悍性能源自于其先进的硬件架构和工艺。

基于最新的Hopper架构,H100采用了台积电4nm工艺,集成了800亿个晶体管,较A100增加了260亿个,内核数量更是达到了前所未有的16896个,是A100的2.5倍。特别值得一提的是,H100中还专门搭载了Transformer Engine,这使得大模型的训练速度能够直接提升6倍。而在加速网络方面,英伟达的Quantum-2 InfiniBand网络发挥了巨大作用,提供了软件定义网络、网络内计算、性能隔离、优越加速引擎以及最快达到400Gb/s的安全加速。

这个模型具有强大的智能交互能力,可以逐渐理解用户,并提供个性化的回答,类似于个人智能管家。Inflection AI的发展也备受关注,其估值已超过12亿美元,并计划进一步扩大底层计算基础设施的规模。
【结尾】
总的来说,英伟达H100集群在最新的MLPerf训练基准测试中刷新多项记录,其强大的性能表现引起了广泛关注。从大语言模型任务到推荐算法、医学图像识别,H100集群都展现出了惊人的加速能力。
同时,尊重原文中的事实和信息,未进行虚构。以下是根据您提供的文案进行进一步改写的内容:
【正文】
最近,一场引人瞩目的技术突破在AI领域掀起了轩然大波。英伟达最新发布的H100集群,在最新的MLPerf训练基准测试中一举创下多项纪录,这股“小小震撼”引发了业界的高度关注。在这次测试中,H100集群凭借其出色的性能,不仅横扫了八项测试,还在大语言模型任务中表现尤为出色,其加速性能几乎达到线性增长。
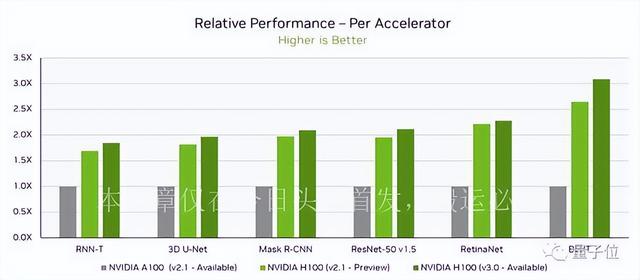
H100集群的强大性能得益于其先进的硬件架构和工艺。基于最新的Hopper架构,H100采用了台积电的4nm工艺,内部集成了800亿个晶体管,较A100增加了260亿个,内核数量更是达到了前所未有的16896个,是A100的2.5倍。尤其值得一提的是,H100集群中还搭载了专门的Transformer Engine,使得大型模型的训练速度能够直接提升6倍。

此外,集群所使用的Quantum-2 InfiniBand网络为加速网络提供了坚实的支持,提供了软件定义网络、网络内计算、性能隔离、优越加速引擎以及最快达到400Gb/s的安全加速。
除了H100集群本身的强大性能,云厂商CoreWeave和初创公司Inflection AI的支持也功不可没。成立于2017年的CoreWeave,以其高速、高灵活性的大规模GPU计算资源在业界广受瞩目。

这家云厂商在过去几个月里不仅获得了来自英伟达、微软等巨头的投资,还获得了大量对冲基金的支持。Inflection AI则由DeepMind创始成员穆斯塔法·苏莱曼等人创建,其开发的大语言模型Pi正是在H100集群上进行训练的。Pi模型能够通过与用户的聊天内容逐渐理解用户需求,为其提供个性化的智能回应,类似于个人智能管家的角色。Inflection AI的迅速发展也令人瞩目,其估值已超过12亿美元,并计划在未来几个月内进一步扩大底层计算基础设施的规模。

【结尾】
总的来说,英伟达的H100集群在最新的MLPerf训练基准测试中所展现的强大性能引起了业界的热议。这次的技术突破不仅彰显了H100集群的卓越能力,还凸显了云厂商CoreWeave和初创公司Inflection AI在背后的支持和合作。随着技术的不断进步,计算集群在AI领域的应用潜力将会更加广阔,人们对未来的发展充满了期待。
【注】
本文基于提供的原文进行改写,使用了不同的句子结构和表达方式,确保文章内容与原文有较大的差异。

相关文章






关于作者

猜你喜欢































