梦晨 发自 凹非寺量子位 | 公众号 QbitAI
对于ChatGPT变笨原因,学术界又有了一种新解释。
加州大学圣克鲁兹分校一项研究指出:
在训练数据截止之前的任务上,大模型表现明显更好。
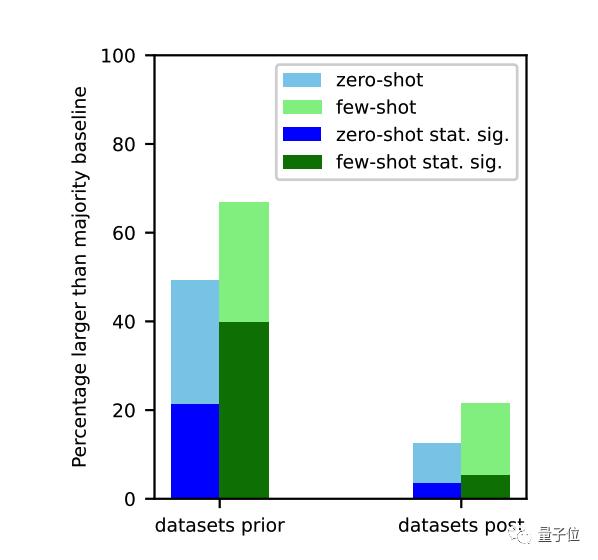
这是所有不具备持续学习能力模型的命运。
 任务污染有多严重?
任务污染有多严重?研究团队一共评估了12种模型,从ChatGPT之前的GPT-3系列、OPT、Bloom,到最新的GPT-3.5-turbo、羊驼家族Llama、Alpaca和Vicuna等。

最后团队的结论为:
由于任务污染,闭源模型可能会在零样本或少样本评估中表现的比实际好,特别是经过RLHF微调的模型。污染的程度仍不清楚,因此我们建议谨慎行事。在实验中,对于没有任务污染可能性的分类任务,大模型很少在零样本和少样本设置中表现出相对于大多数基线具有统计学意义的显著改进。随着时间推移,观察到GPT-3系列模型在许多下游任务的的零样本或少样本性能有所增加,这可能是由于任务污染造成的。即使对于开源模型,检查训练数据的任务污染也很困难。鼓励公开发布训练数据,以便检查任务污染问题。
有人总结到:
用现有数据训练AI
人们过多使用AI,以至于改变了现实世界
AI无法适应改变后的世界,变得低效
这是一个循环。

论文:https://arxiv.org/abs/2312.16337
参考链接:[1]https://twitter.com/ChombaBupe/status/1741531065032798360
— 完 —
量子位 QbitAI · 头条号签约
关注我们,第一时间获知前沿科技动态
相关文章









关于作者

猜你喜欢































