机器之心报道
编辑:魔王
为了衡量机器学习模型的数学求解能力,来自 UC 伯克利和芝加哥大学的研究者提出了一个包含 12, 500 道数学竞赛难题的新型数据集 MATH,以及帮助模型学习数学基础知识的预训练数据集 AMPS。研究发现,即使是大参数的 Transformer 模型准确率也很低。
许多学术研究探讨数学问题求解,但对于计算机而言这超出了其能力范畴。那么机器学习模型是否具备数学问题求解能力呢?
来自加州大学伯克利分校和芝加哥大学的研究者为此创建了一个新型数据集 MATH。该数据集包含 12, 500 道数学竞赛难题,每个数学题都有完整的逐步求解过程,可用来教机器学习模型生成答案和解释。为了促进未来研究,提升模型在 MATH 数据集上的准确率,研究者还创建了另一个大型辅助预训练数据集,它可以教模型数学基础知识。
尽管通过这些方法提升了模型在 MATH 数据集上的准确率,但实验结果表明,准确率仍然很低,即使 Transformer 模型也不例外。研究者还发现,仅靠增加预算和模型参数量并不能实现强大的数学推理能力。扩展 Transformer 能够自动解决大多数文本任务,但目前仍无法解决 MATH 问题。
该研究第一作者 Dan Hendrycks 发推表示:
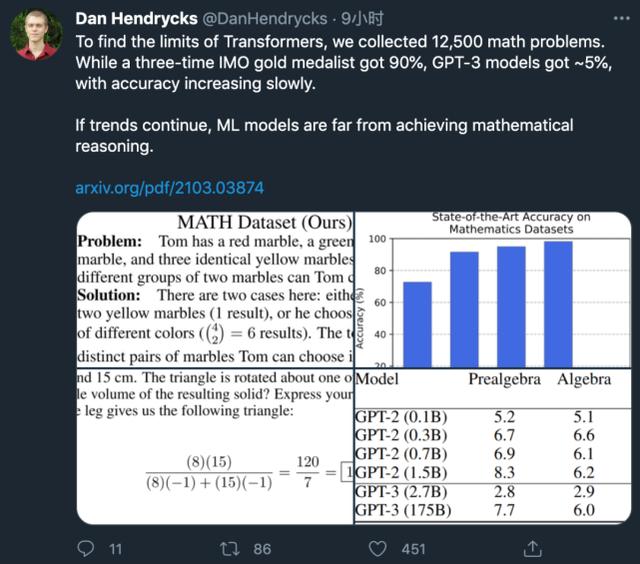
国际数学奥林匹克竞赛(IMO)三金得主能达到 90% 的准确率,而 GPT-3 的准确率只能达到约 5%。
如果这一趋势持续下去,那么机器学习模型距离获得数学推理能力还很遥远。
数据集
这部分介绍两个新型数据集,一个是用于测试模型数学问题求解能力的 MATH 数据集,另一个是用于辅助预训练的 AMPS 数据集。
MATH 数据集
MATH 数据集包含 12, 500 个数学问题(其中 7500 个属于训练集,5000 个属于测试集),这些问题收集自 AMC 10、AMC 12、AIME 等数学竞赛(这些数学竞赛已经持续数十年,旨在评估美国最优秀的年轻数学人才的数学问题求解能力)。与大多数之前的研究不同,MATH 数据集中的大部分问题无法通过直接应用标准 K-12 数学工具来解决,人类解决这类问题通常需要用到问题求解技术和「启发式」方法。
基于这些数学问题,模型可以学习多种有用的问题求解启发式方法,且每个问题都有逐步求解过程和最终答案。具备逐步求解过程的问题示例参见下图 1:

此外,研究者测试了使用 AMPS 预训练的效果。未经 AMPS 预训练时,GPT-2 (1.5B) 模型在 MATH 数据集上的准确率为 5.5%;而经过 AMPS 预训练后,GPT-2 (1.5B) 在 MATH 数据集上的准确率为 6.9%(参见表 2),准确率提升了 25%。也就是说,AMPS 预训练对准确率的提升效果相当于参数量 15 倍增加的效果,这表明 AMPS 预训练数据集是有价值的。
逐步求解
研究者对逐步求解过程进行了实验,发现模型在得到答案前先生成逐步求解过程会导致准确率下降。研究者利用 GPT-2 (1.5B) 进行评估,发现模型性能有所下降,从 6.9% 下降到了 5.3%。
研究者还对这些生成的逐步求解过程进行了定性评估,发现尽管很多步骤看似与问题相关,但其实存在逻辑问题。示例参见下图 3、4:

图 3:问题、GPT-2 (1.5B) 模型生成的逐步解、真值解。

相关文章









关于作者

猜你喜欢
成员 网址收录40400 企业收录2981 印章生成237605 电子证书1052 电子名片60 自媒体51892































