给机器人发命令,从没这么简单过。
我们知道,在掌握了网络中的语言和图像之后,大模型终究要走进现实世界,「具身智能」应该是下一步发展的方向。
把大模型接入机器人,用简单的自然语言代替复杂指令形成具体行动规划,且无需额外数据和训练,这个愿景看起来很美好,但似乎也有些遥远。毕竟机器人领域,难是出了名的。
然而 AI 的进化速度比我们想象得还要快。
谷歌 DeepMind 宣布推出 RT-2:全球第一个控制机器人的视觉 - 语言 - 动作(VLA)模型。
现在不再用复杂指令,机器人也能直接像 ChatGPT 一样操纵了。

在此之前,机器人无法可靠地理解它们从未见过的物体,更无法做把「灭绝动物」到「塑料恐龙玩偶」联系起来这种有关推理的事。
跟机器人说,把可乐罐给泰勒・斯威夫特:

RT-2 架构及训练过程
其实早在去年,谷歌就曾推出过 RT-1 版本的机器人,只需要一个单一的预训练模型,RT-1 就能从不同的感官输入(如视觉、文本等)中生成指令,从而执行多种任务。
作为预训练模型,要想构建得好自然需要大量用于自监督学习的数据。RT-2 建立在 RT-1 的基础上,并且使用了 RT-1 的演示数据,这些数据是由 13 个机器人在办公室、厨房环境中收集的,历时 17 个月。
DeepMind 造出了 VLA 模型
前面我们已经提到 RT-2 建立在 VLM 基础之上,其中 VLMs 模型已经在 Web 规模的数据上训练完成,可用来执行诸如视觉问答、图像字幕生成或物体识别等任务。此外,研究人员还对先前提出的两个 VLM 模型 PaLI-X(Pathways Language and Image model)和 PaLM-E(Pathways Language model Embodied)进行了适应性调整,当做 RT-2 的主干,并将这些模型的视觉 - 语言 - 动作版本称为 RT-2-PaLI-X 以及 RT-2-PaLM-E 。
为了使视觉 - 语言模型能够控制机器人,还差对动作控制这一步。该研究采用了非常简单的方法:他们将机器人动作表示为另一种语言,即文本 token,并与 Web 规模的视觉 - 语言数据集一起进行训练。
对机器人的动作编码基于 Brohan 等人为 RT-1 模型提出的离散化方法。
如下图所示,该研究将机器人动作表示为文本字符串,这种字符串可以是机器人动作 token 编号的序列,例如「1 128 91 241 5 101 127 217」。
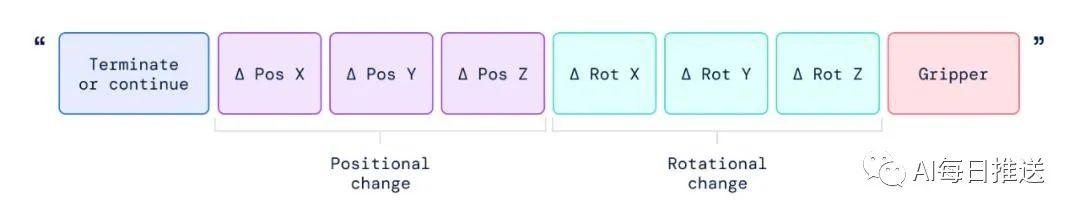
一系列结果表明,视觉 - 语言模型(VLM)是可以转化为强大的视觉 - 语言 - 动作(VLA)模型的,通过将 VLM 预训练与机器人数据相结合,可以直接控制机器人。
和 ChatGPT 类似,这样的能力如果大规模应用起来,世界估计会发生不小的变化。不过谷歌没有立即应用 RT-2 机器人的计划,只表示研究人员相信这些能理解人话的机器人绝不只会停留在展示能力的层面上。
简单想象一下,具有内置语言模型的机器人可以放入仓库、帮你抓药,甚至可以用作家庭助理 —— 折叠衣物、从洗碗机中取出物品、在房子周围收拾东西。
它可能真正开启了在有人环境下使用机器人的大门,所有需要体力劳动的方向都可以接手 —— 就是之前 OpenAI 有关的报告中,大模型影响不到的那部分,现在也能被覆盖。
具身智能,离我们不远了?
最近一段时间,具身智能是大量研究者正在探索的方向。本月斯坦福大学李飞飞团队就展示了一些新成果,通过大语言模型加视觉语言模型,AI 能在 3D 空间分析规划,指导机器人行动。
稚晖君的通用人形机器人创业公司「智元机器人(Agibot)」昨天晚上放出的视频,也展示了基于大语言模型的机器人行为自动编排和任务执行能力。

预计在 8 月,稚晖君的公司即将对外展示最近取得的一些成果。
可见在大模型领域里,还有大事即将发生。
获取最新AI头条,请关注公众号:AI每日推送
参考内容:
https://www.deepmind.com/blog/rt-2-new-model-translates-vision-and-language-into-action
https://www.blog.google/technology/ai/google-deepmind-rt2-robotics-vla-model/
https://www.theverge.com/2023/7/28/23811109/google-smart-robot-generative-ai
https://www.nytimes.com/2023/07/28/technology/google-robots-ai.html
相关文章








关于作者

猜你喜欢































