克雷西 发自 凹非寺
量子位 | 公众号 QbitAI
不希望网站数据被ChatGPT白嫖?现在终于有办法了!
两行代码就能搞定,而且是OpenAI官方公布的那种。

但至少,站主们拥有了选择的权利。
不过,也有网友指出了问题:
模型早就已经训练好了,现在提这个还有什么用?
 什么是robots.txt
什么是robots.txt上面提到的robots.txt是什么,为什么它能阻止GPT的爬虫?
这其实是一种用户协议,站主可以在其中设置禁止访问网站的爬虫或禁止爬虫抓取的内容。
根据这一协议,即使在有能力访问的情况下,爬虫遇到相关内容都会主动选择避开。
ChatGPT自身也在使用robots.txt,阻止爬虫抓取除了用户分享之外的其他内容。

这是一项君子协定,不过大多数厂商都会选择遵守,因为这体现了对行业规则和用户隐私的尊重。
如今,OpenAI也加入了这一行列。
One More Thing与此同时,Google的爬虫正在全网抓取内容。
不过,网友对此似乎有更高的容忍度:
至少Google是链接到你的网站,但ChatGPT用了你的内容之后根本不会进行说明。
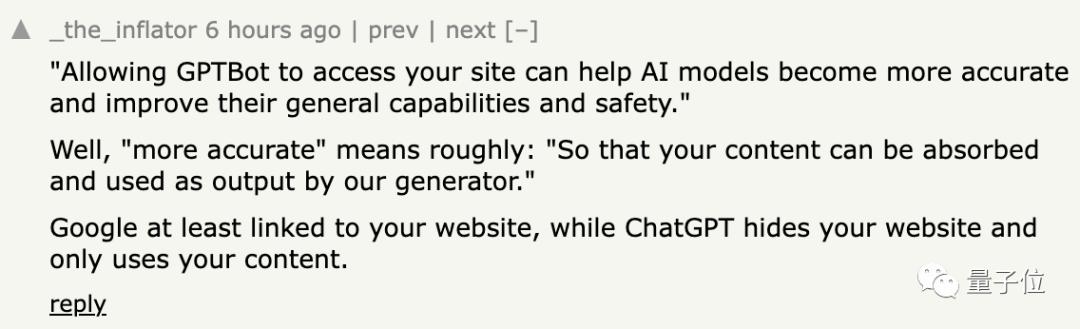
你认为在提高模型质量和保护创作者之间该如何找到平衡点呢?
参考链接:[1]https://platform.openai.com/docs/gptbot[2]https://www.theverge.com/2023/8/7/23823046/openai-data-scrape-block-ai[3]https://news.ycombinator.com/item?id=37030568
— 完 —
量子位 QbitAI · 头条号签约
关注我们,第一时间获知前沿科技动态
相关文章







关于作者

猜你喜欢































