编辑:编辑部
【新智元导读】「地表最强」GPT-4在推理问题中接连出错!MIT校友,以及UCLA华人一作的最新研究引众多网友围观。GPT-4根本不会推理!
近来,有两篇研究称,GPT-4在推理方面表现不尽人意。
来自MIT的校友Konstantine Arkoudas,在21种不同类型推理集中,对GPT-4进行了评估。
然后,对GPT-4在这些问题上的表现进行了详细的定性分析。
研究发现,GPT-4偶尔会展现出「最强大脑」的天赋,但目前来看,GPT-4完全不具备推理能力。

论文地址:https://arxiv.org/pdf/2307.10635.pdf
研究人员引入了一个大学科学问题解决基础SCIBENCH,其中包含2个数据集:开放数据集,以及封闭数据集。
通过对GPT-4和GPT-3.5采用不同提示策略进行深入研究,结果显示,GPT-4成绩平均总分仅为35.8%。
这项研究同样再次引起马库斯的关注:
关于数学、化学和物理推理的系统调查,结果显示,目前的LLM无法提供令人满意的性能......没有一种提示策略明显优于其他策略。

2. 简单计数
虽然具体计数并不一定是一种推理活动 ,但它肯定是任何具有一般能力推理系统的必备条件。
在这里,给GPT-4一个命题变量,并在它前面加上27个否定符号,要求它计算否定符号的个数。
对于我们来讲,这简直轻而易举,尤其是否定符号是间隔5个写成的,并且有5组,最后一对否定符号紧随其后。
然而,GPT-4却给出了「28个」答案。

3. (医学)常识
当前,我们可以将常识性论证视为,从给定信息加上未说明的条件(默认的、普遍接受的背景知识)中得出的简单推理。
在这种特殊情况下,常识性知识就是「人在死前是活着的,死后就不会再活着」这样的命题。
比如,当你问GPT-4:Mable上午9点的心率为75 bpm,下午7点的血压为120/80。她于晚上11点死亡。她中午还活着吗?

值得注意的是,GPT-4认识到,P(x)实际上并不包含Q(x),并提出了x有可能是负数偶数,「不排除存在其他给定条件的模型」。
其实不然,一个反模型(countermodel)必须满足所有给定的条件,同时证伪结论。
此外,仅仅几句话之后, GPT-4就声称P(x)在给定的解释下确实蕴含Q(x),这与它自己之前的说法相矛盾。

显然,这三个句子都是共同可满足的,一个简单的模型是具有P(a1)、Q(a1)、¬P(a2) 和 ¬Q(a2)的域{a1, a2},然而GPT-4得出的结论确与之相反。
6. 简单图着色
首先考虑一个没有解决方案的图着色问题。
不难发现,对于这个问题中描述的图形,两种颜色是不足以满足问题中描述的图(例如,顶点0、2和4形成了一个簇,因此至少需要3种颜色)。

9. 简单安排计划
在时间安排问题上,GPT-4同样出错了。

上下滑动查看全部
10. 罗素悖论
罗素理发师悖论是指,存在一个理发师b,他为且仅为那些不给自己刮胡子的人刮胡子。
这句话的否定是一个同义反复,很容易用一阶逻辑推导出来。
如果我们把R(a,b)理解为a被b刮胡子,那么我们就可以提出这个同义反复,并要求GPT-4证明或反证它,如下面prompt所示:
如果存在这样一个理发师x,那么对于所有y,我们将有R(y,x) ∼ R(y,y),因此用x代替y将得到R(x,x) ∼ R(x,x),这是矛盾的。
GPT-4对所给句子的结构和需要做的事情的理解无可挑剔。然而,随后的案例分析却糊里糊涂。

有五个积木从上往下堆叠:
1. 从上往下数第二个积木是绿色的
2. 从上往下数第四个积木不是绿色的
在这些条件成立的情况下,证伪或证明以下结论:在一个非绿色积木的正上方,有一个绿色积木。
首先它在证明猜想时,就已经弄错了证明的策略——PT-4假定了两种特殊情况来进行推理。
此外,GPT-4在自己的推理中已经得出了结论(虽然是错的),但在回答时仍然告诉用户问题没有被解决。而这体现的便是模型的内部不一致性问题。

GPT-4第一次给出的答案是右边,但作者指出了它的错误,虽然从地图上来看,位于马萨诸塞州的波士顿的确在南达科他州的右边,但这里还有一个附加条件:身体的朝向是得克萨斯州。

这意味着波士顿在作者的左边。
之后,GPT-4在回答波士顿与南达科他州高低位置时,出现了更严重的问题:它在同一个回答中给出了两种矛盾的描述。

桌上放着7张牌,每张牌一面写着数字,另一面是单色色块。这些牌的正面显示的是50、16、红色、黄色、23、绿色、30。
要判断「如果一张牌正面显示4的倍数,则背面颜色为黄色」这个命题的真假,你需要翻转哪些牌?

错误标记为红色,更正内容为紫色
对此,研究中引入了一个大学水平的科学问题基准SCIBENCH。
其中,「开放数据集」包括从大学课程广泛使用的教科书中收集的5个问题,涵盖了基础物理、热力学、经典力学、量子化学、物理化学、微积分、统计学和微分方程。

开放教科书问题摘要(包括问题数量的比例,以及有详细解决方案的比例)
另一个是「封闭数据集」,为了模拟真实世界的评估,其中包含了计算机科学和数学三门大学课程的7套期中和期末考试题。
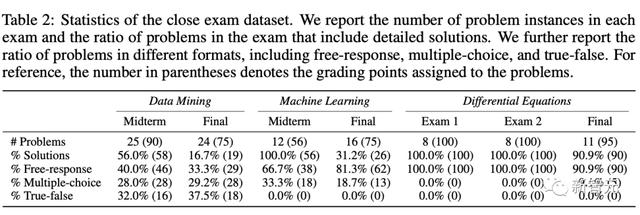
开放数据集中准确率的结果
在使用CoT提示 外部工具最强配置下,GPT-4在开放式数据集上取得了35.80%的平均分,在封闭数据集上取得了51.57%的平均分。
这些结果表明,在未来的LLM中,GPT-4有相当大的改进潜力。

考试数据集上零样本学习下总分的实验结果
为了全面了解LLM在科学问题解决中的局限性,研究人员提出了一种全新的「自我完善」的方法,以发现LLM所做解答中的不足之处。
便是如下的「评估协议」。

首先,将正确的解决方案与LLM生成的解决方案进行比较,并在人工标注员的协助下,总结出成功解决科学问题所需的10项基本技能。
具体包括:逻辑分解和分析能力;识别假设;空间感知;因果推理;问题演绎;抽象推理;科学素养;代码转换;逻辑推理;计算能力。
随后,团队采用了一种由LLM驱动的自我评价方法,对每个实验配置下基准LLM所做的解决方案中,缺乏的技能进行自动分类。
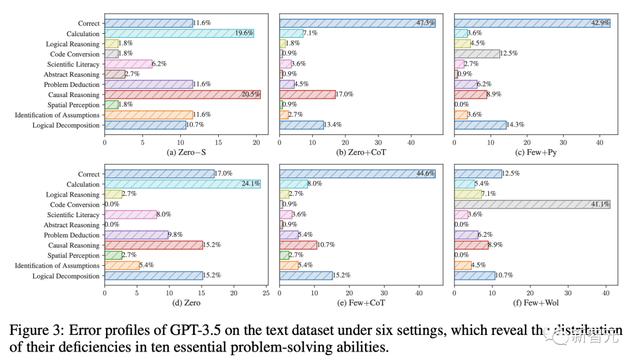
6种设置下GPT-3.5在文本数据集上的错误概况,揭示了其10种基本解决问题能力的缺陷分布
最后,通过分析发现:
(1) 虽然CoT显著提高了计算能力,但在其他方面的效果较差;
(2) 使用外部工具的提示可能会损害其他基本技能;
(3) 少样本学习并不能普遍提高科学问题解决能力。
总之,研究结果表明,当前大型语言模型在解决问题能力方面依旧很弱,并且在各种工具帮助下,依旧存在局限性。
参考资料:
相关文章







关于作者

猜你喜欢
成员 网址收录40399 企业收录2981 印章生成237499 电子证书1052 电子名片60 自媒体50829































