机器之心报道
机器之心编辑部
3 月 21 日,在机器之心举办的 ChatGPT 及大模型技术大会上,哈尔滨工业大学计算学部长聘教授、博士生导师车万翔发表主题演讲《ChatGPT 浅析》,在演讲中,他回答了 ChatGPT 究竟解决了什么科学问题,是如何解决该问题的,以及未来还有哪些亟待解决的问题。
另外我们也了解到,车万翔教授大模型相关的科研成果也正在进行产业转化,机器之心后续将为大家带来报道。

在预训练模型阶段比较有代表性的研究是 GPT-3,它是 OpenAI 和微软在 2020 年发布的大模型,参数量达 1750 亿,以当时的视角来看,研究者认为这个模型太大没办法精调,所以「提示语」方法出现了。所谓提示语,即直接给出任务描述,可以让模型自动补全这个任务,这个补全过程就是在完成任务,如果再给出一些示例,模型性能可能会更好,这种也叫做情境学习。采用这种方式的一个好处是模型无需针对某一个任务再次训练,就可以完成不同文本生成任务。当然,这个文本生成任务是加引号的,因为它不仅能回答问题、文章续写,还可以完成生成网页,甚至生成代码等范文本任务。

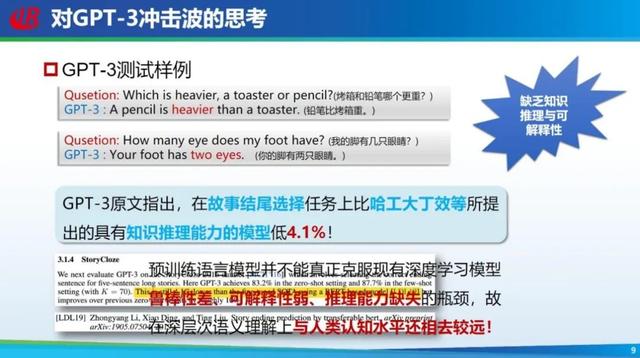
GPT-3 的出现并没有引起大家的特别关注,为什么呢?因为当时大家发现 GPT-3 虽然能够实现这些任务,但效果并不是很好。举几个典型的例子,比如问 GPT-3「烤箱和铅笔哪个重」,它会说「铅笔比较重」;再问「我的脚上有几只眼睛」,它会说「两只眼睛」。
GPT-3 给出的答案很多是错误的,有些人就认为花这么多钱构造这么大的模型也没有解决根本任务。当然 GPT-3 原文也指出,在故事结尾选择任务上比我们组丁效老师等所提出的具有知识推理能力的模型低 4.1%。因此大家认为这种大模型鲁棒性差、可解释性弱、推理能力也不强,因此需要有更多的知识。
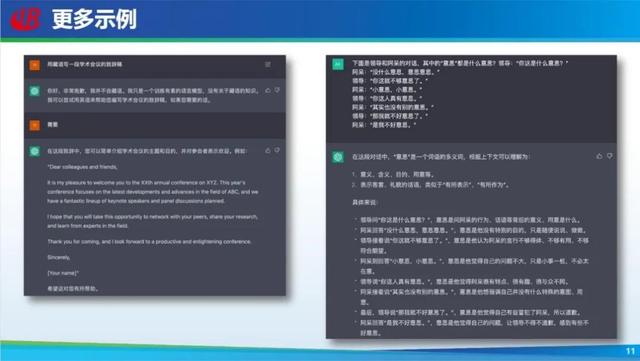
当然还有其他示例,比如让 ChatGPT 用藏语写学术会议致辞,它首先会否定,说自己不会。这是很厉害的,原来我们做问答和聊天模型很难否定一个问题。另外,它说会用英语写,如果我说可以,它就真的会用英语写。可见 ChatGPT 对会的语言掌握的很好。
还是前面那个例子,「领导和阿呆的对话」直接问 ChatGPT 这到底是什么意思,它会回答说有两个意思,具体每一句话的意思是什么,模型都解释的很清楚。这是非常惊艳的,仔细看未必准确,但模型至少理解了这个问题,这是很难做到的。
ChatGPT 的发展历程也非常励志,第一代 GPT 就是 OpenAI 提出来的,甚至比 BERT 提出的还要早,GPT 开启了自然语言处理预训练时代。但是大家记住更多的是 BERT,因为当时 OpenAI 还是个小公司,大家还没太关注它的工作,同时 BERT 是 Google 提出来的,从自然语言理解的角度来讲,BERT 参数量大,具有双向理解方式,所以它的效果比 GPT 好。但是 OpenAI 并没有模仿这种方式做双向,它继续沿着 GPT 单向结构进行,后来就产生了 GPT-2,学术界用的也比较多,GPT-3 的出现,风靡了一阵,不过之后大家觉得这模型浪费钱,效果还不怎么好,去年 3 月 InstructGPT 出现了,吸引了很多国际学术界的关注,但国内关注的相对较少。
直到去年 11 月底 ChatGPT 的发布,一炮打响,引起更多关注,以及今年 3 月份发布的 GPT-4,它不光处理文本,甚至融合了多模态。OpenAI 整个历程比较励志,它一直沿着 GPT 这条路线在走,最后还走通了,有人说 OpenAI 比较犟,比较执拗,但确实它有自己的信心和理想,走成了。

接下来是探究大模型背后的机理,现在的争议围绕到底是 Encoder-Decoder 结构好,还是 Decoder only 结构好。这些方法各有各的优缺点。Decoder only 如 GPT,其参数和数据利用率更高,但从对输入理解的角度,Encoder-Decoder 结构可能更好。这两者之间怎么平衡,或者说到底哪个好,现在也没有统一的结论,还处于探索阶段。

还有就是怎么对大模型进行评价。现在有很多评价模型的数据集发布,但这个数据集一旦发布就有可能泄漏,有些人会把数据集用到训练数据里,怎么解决这种问题,也是需要考虑的。
三是解释包括涌现现象、CoT 等出现的机理。

最后要推广大模型的应用。ChatGPT 是一种通用模型,怎么把它落地到各行各业,包括怎么做定制化、小型化、个性化,甚至角色化、安全性、隐私性等等,这些都是需要考虑和解决的问题。
再往后人工智能怎么走,现在 ChatGPT 比较好的解决了推理问题,以后可能要解决语用的问题,同样一段话所处的语境不一样,对象不一样,用的语气语调不一样,可能表达的含义就不一样。

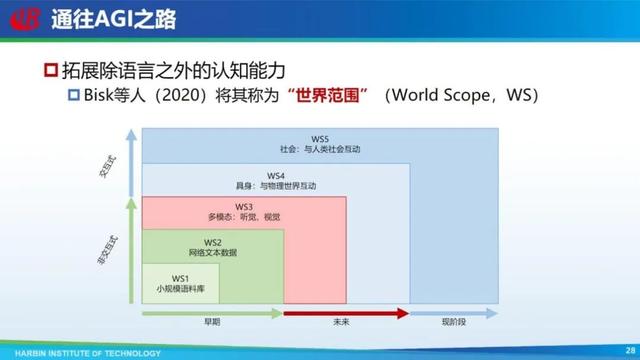
当然,只从文本入手没法解决这个问题,还是要往多模态等发展。结合更多的模态,通往真正的 AGI。
之前有学者把机器能够利用的数据范围划为五个,从最简单的小规模文本一直到和人类社会互动这五个范围。之前很长一段时间大家都只用文本端,现阶段等于是跨过中间的两个(多模态和具身),直接到了和人类社会的互动,因为现在 ChatGPT 就是和人类社会交互。在交互过程中,人也在教机器怎么说语言,怎么理解语言。但跨过中间两段不代表就真的包含这两段,还是要把这两段补齐。现在 GPT-4 补齐了多模态,Google、微软等也在做具身方面的研究。
总结和展望
最后是总结和展望,自然语言处理是人工智能皇冠上的明珠,ChatGPT 是继数据库和搜索引擎之后的全新一代知识表示和调用方式,模型同质化和规模化的趋势不可逆转。要想真正实现 AGI,需要结合多模态和具身智能。

以上就是我报告的全部内容,谢谢大家!
相关文章






关于作者
猜你喜欢
成员 网址收录40386 企业收录2981 印章生成229730 电子证书1009 电子名片58 自媒体46281































