机器之心报道
机器之心编辑部
UltraChat 解决了数据荒的一大难题。
自 ChatGPT 发布以来,这段时间对话模型的热度只增不减。当我们赞叹这些模型表现惊艳的同时,也应该猜到其背后巨大的算力和海量数据的支持。
单就数据而言,高质量的数据至关重要,为此 OpenAI 对数据和标注工作下了很大力气。有多项研究表明,ChatGPT 是比人类更加可靠的数据标注者,如果开源社区可以获得 ChatGPT 等强大语言模型的大量对话数据,就可以训练出性能更好的对话模型。这一点羊驼系列模型 ——Alpaca、Vicuna、Koala—— 已经证明过。例如,Vicuna 使用从 ShareGPT 收集的用户共享数据对 LLaMA 模型进行指令微调,就复刻了 ChatGPT 九成功力。越来越多的证据表明,数据是训练强大语言模型的第一生产力。
ShareGPT 是一个 ChatGPT 数据共享网站,用户会上传自己觉得有趣的 ChatGPT 回答。ShareGPT 上的数据是开放但琐碎的,需要研究人员自己收集整理。如果能够有一个高质量的,覆盖范围广泛的数据集,开源社区在对话模型研发方面将会事半功倍。
基于此,最近一个名为 UltraChat 的项目就系统构建了一个超高质量的对话数据集。项目作者尝试用两个独立的 ChatGPT Turbo API 进行对话,从而生成多轮对话数据。
 基于以上元主题,该项目生成了 1100 子主题用于数据构建;对于每个子主题,最多生成 10 个具体问题;然后使用 Turbo API 为 10 个问题中的每一个生成新的相关问题;对于每个问题,如上所述迭代地使用两个模型生成 3~7 轮对话。
基于以上元主题,该项目生成了 1100 子主题用于数据构建;对于每个子主题,最多生成 10 个具体问题;然后使用 Turbo API 为 10 个问题中的每一个生成新的相关问题;对于每个问题,如上所述迭代地使用两个模型生成 3~7 轮对话。此外,该项目从维基数据中收集了最常用的 10000 个命名实体;使用 ChatGPT API 为每个实体生成 5 个元问题;对于每个元问题,生成 10 个更具体的问题和 20 个相关但一般的问题;采样 20w 个特定问题和 25w 个一般问题以及 5w 个元问题,并为每个问题生成了 3~7 轮对话。
接下来我们看一个具体的例子:

输入关键词「数学(math)」的搜索结果,有 3346 组多轮对话:

目前,UltraChat 涵盖的信息领域已经非常多,包括医疗、教育、运动、环保等多个话题。同时,笔者尝试使用开源的 LLaMa-7B 模型在 UltraChat 上进行监督的指令微调,发现仅仅训练 10000 步后就有非常可观的效果,一些例子如下:

世界知识:分别列出 10 个很好的中国和美国大学

假设问题:证明成龙比李小龙更出色
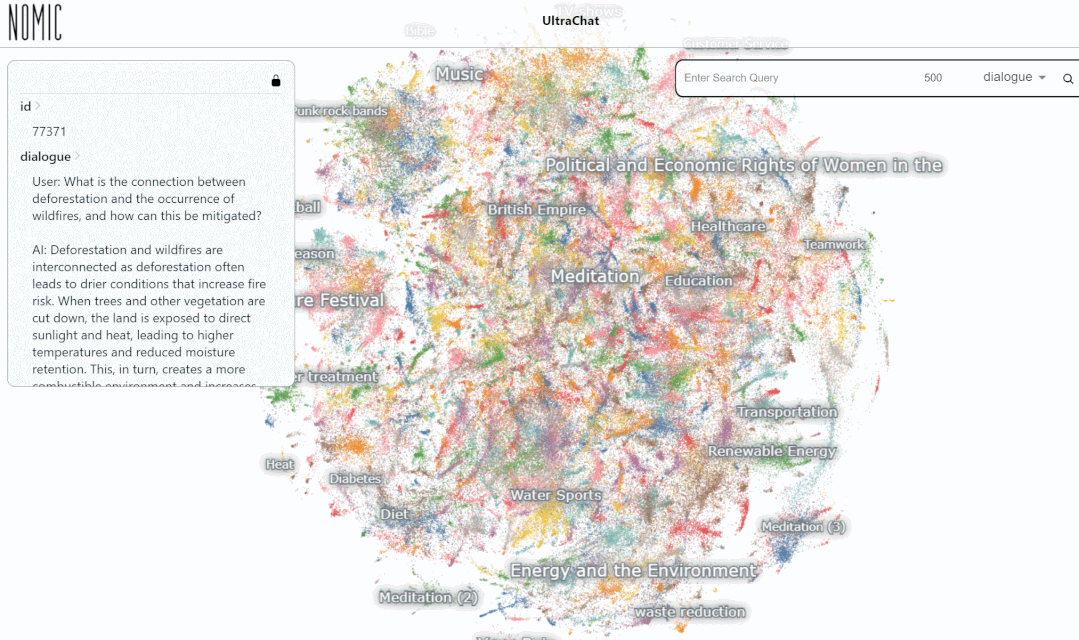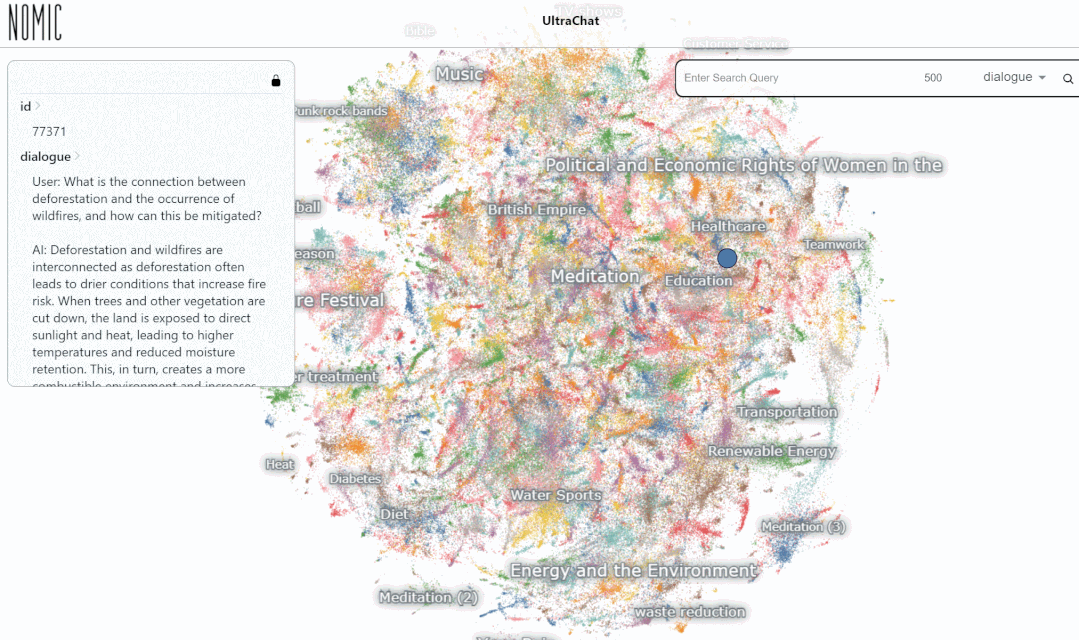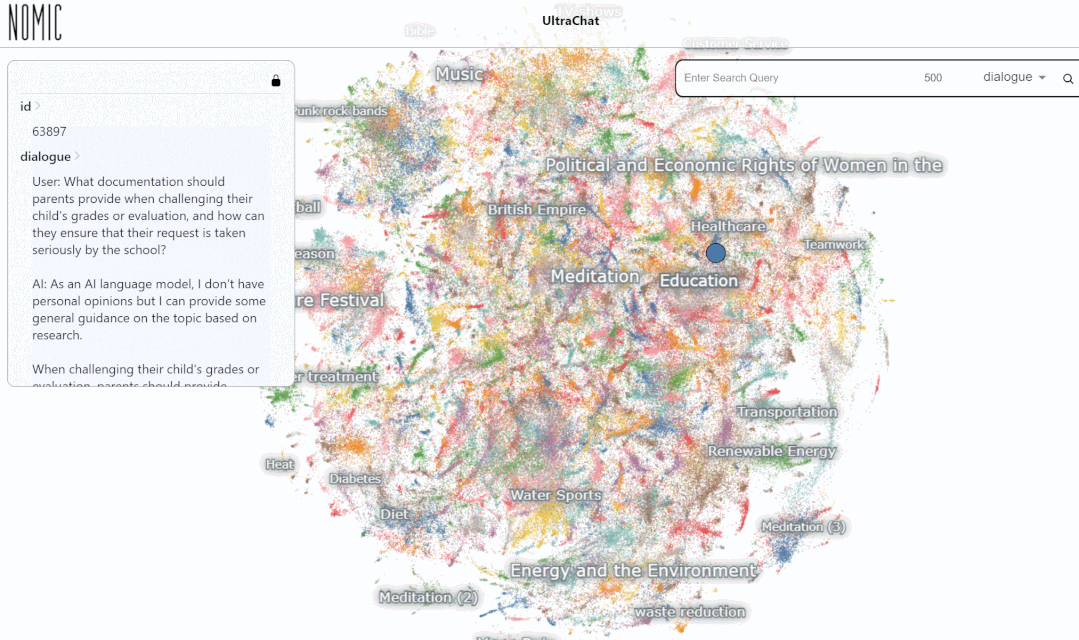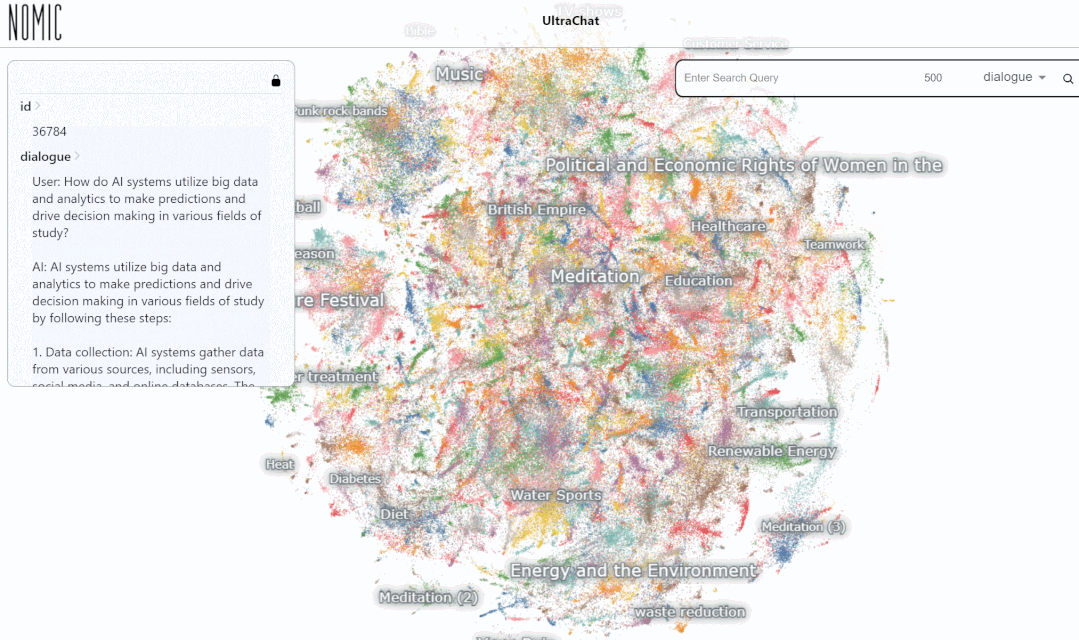
总体来说,UltraChat 是一个高质量、范围广的 ChatGPT 对话数据集,可以和其它数据集结合,显著地提升开源对话模型的质量。目前 UltraChat 还只放出了英文版,但也会在未来放出中文版的数据。感兴趣的读者快去探索一下吧。
相关文章








关于作者

猜你喜欢
成员 网址收录40400 企业收录2981 印章生成237624 电子证书1052 电子名片60 自媒体52467































