编辑:桃子 好困
【新智元导读】Transformer大模型工作原理究竟是什么样的?一位软件工程师打开了大模型的矩阵世界。
黑客帝国中,「矩阵模拟」的世界或许真的存在。

模拟人类神经元,不断进化的Transformer模型,一直以来都深不可测。
许多科学家都试着打开这个黑盒,看看究竟是如何工作的。
而现在,大模型的矩阵世界,真的被打开了!
一位软件工程师Brendan Bycroft制作了一个「大模型工作原理3D可视化」网站霸榜HN,效果非常震撼,让你秒懂LLM工作原理。

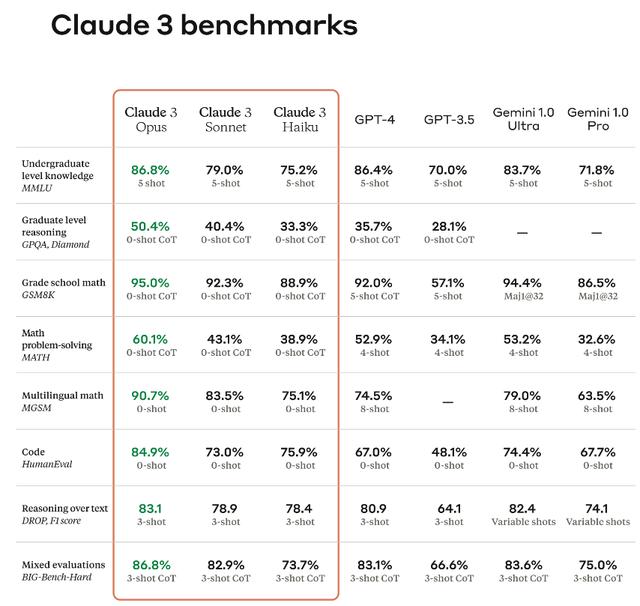
1750亿参数的GPT-3,模型层足足有8列,密密麻麻没遍布了整个屏幕。

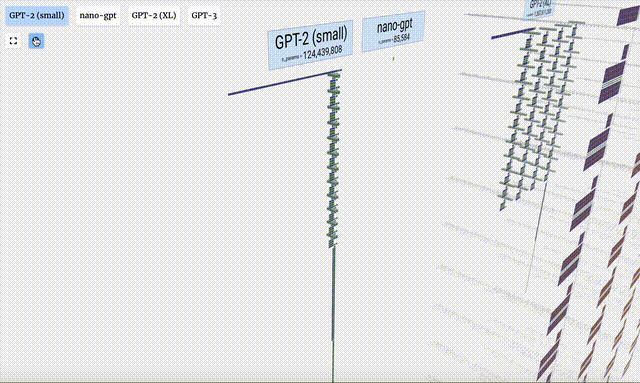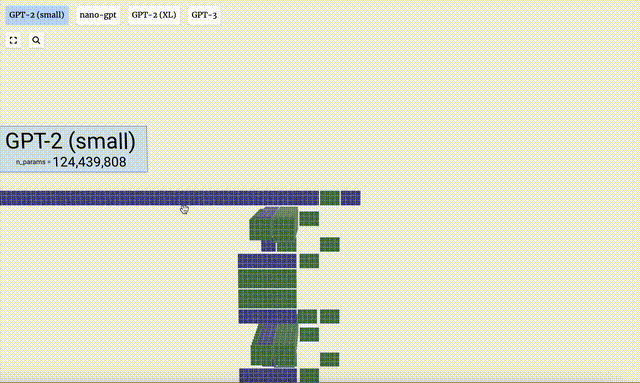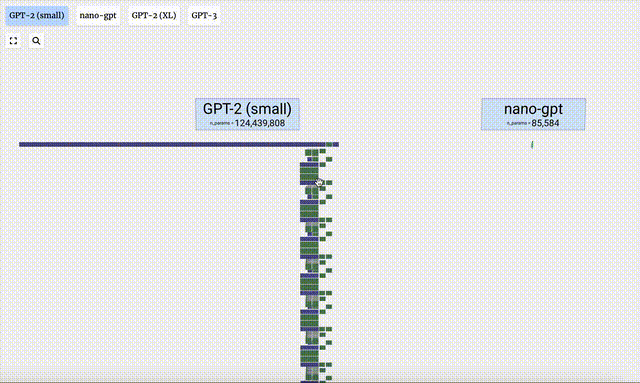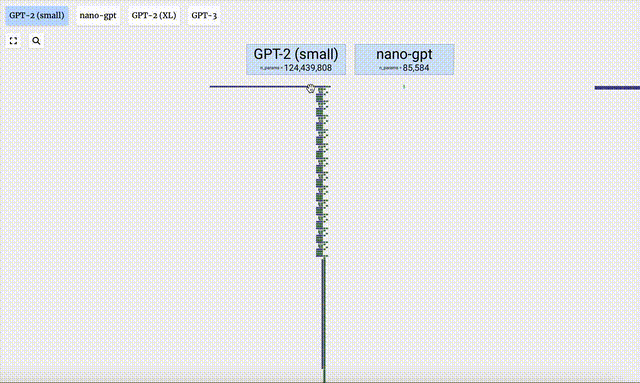
这个3D模型可视化还展示了,大模型生成内容的每一步。
这里,Bycroft主要分解了OpenAI科学家Andrej Karpathy打造的轻量级的GPT模型——NanoGPT,参数量为85000。
Bycroft称,这个指南侧重于模型的推理,而非训练,只是机器学习中的一小部分。在具体例子中,模型的权重已经预训练完成,使用推理过程来生成输出。
当然了,这个可视化网站也是收到了Karpathy在PyTorch中创建的minGPT,以及YouTube视频系列「Neural Networks: Zero to Hero」的启发。
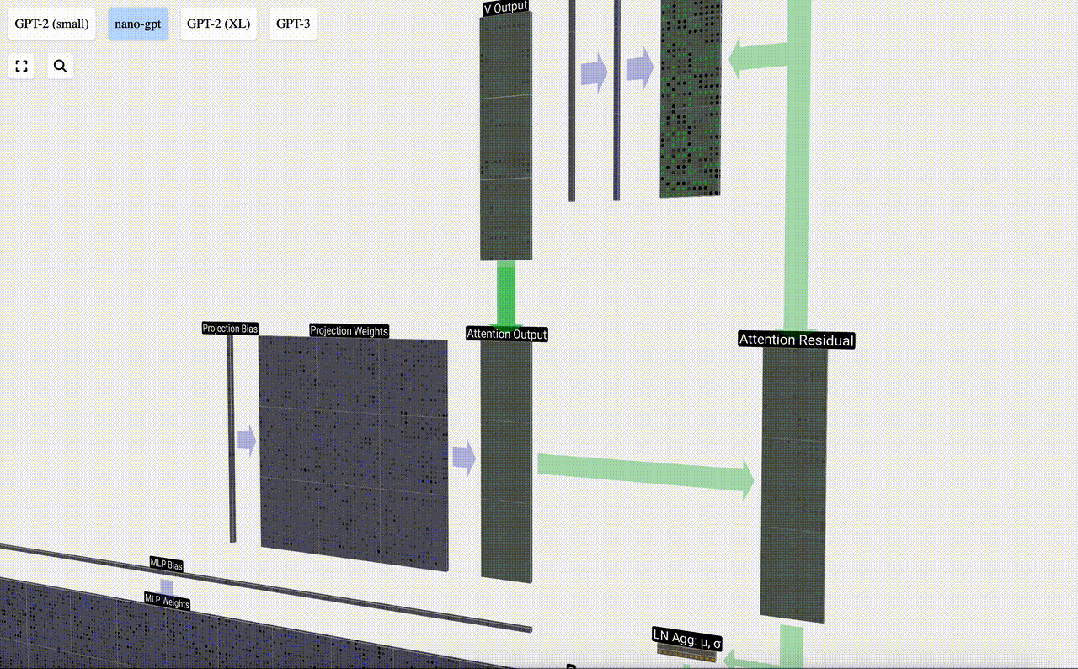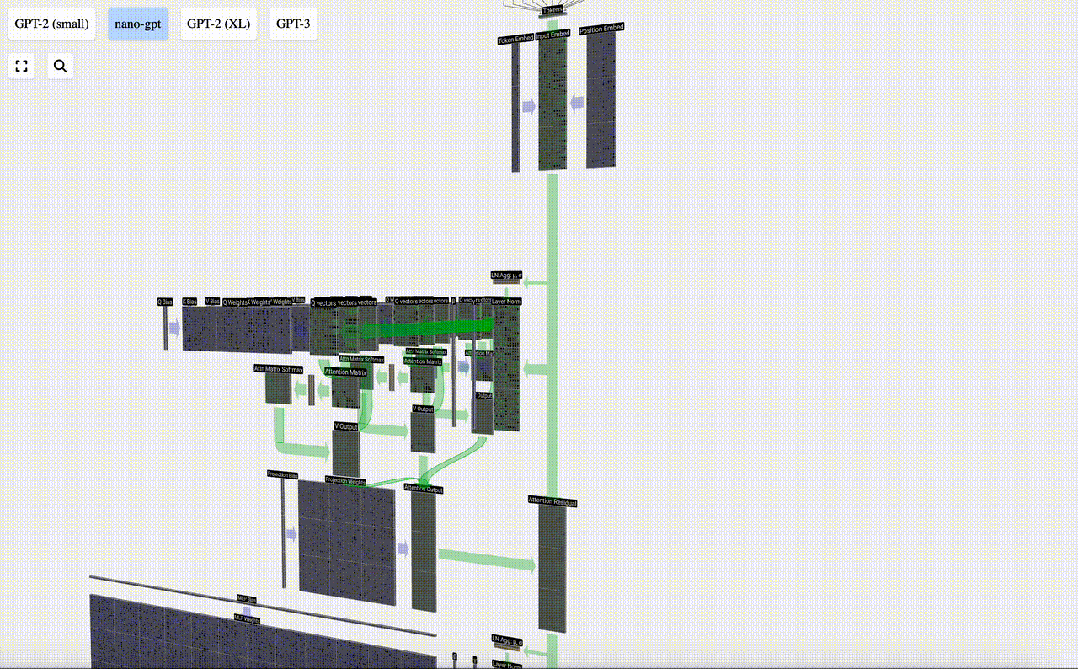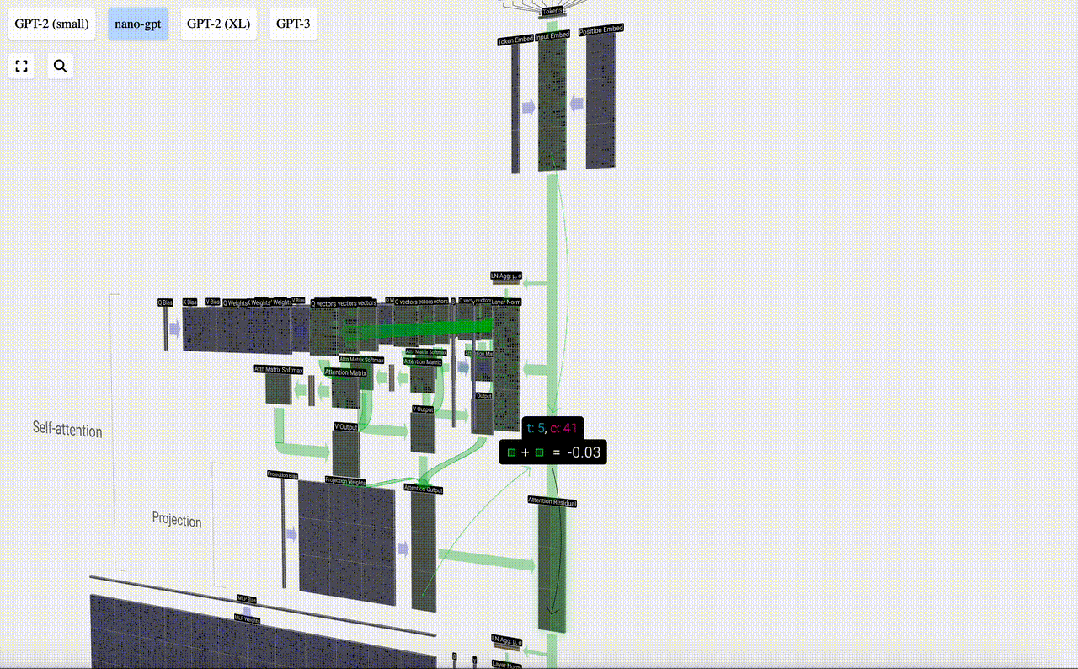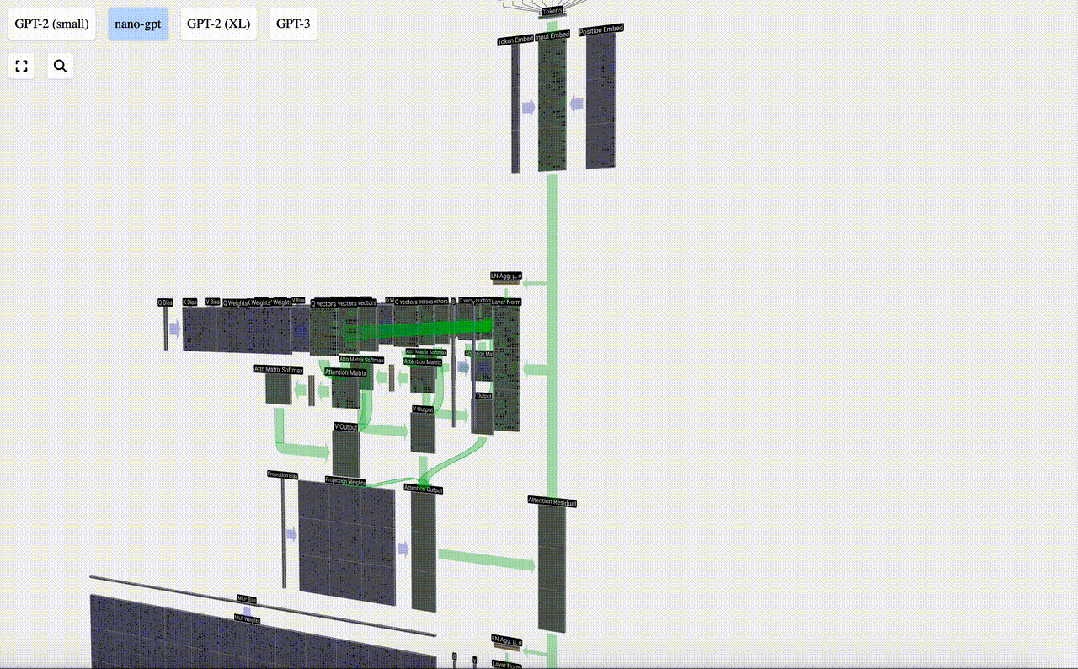
接下来,一起深入来了解,Transformer模型每一层。
介绍
为了方便进行演示,Brendan Bycroft给NanoGPT布置了一个非常简单的任务:
获取一个由六个字母组成的序列:C B A B B C,并按字母顺序排序,即「ABBBCC」。
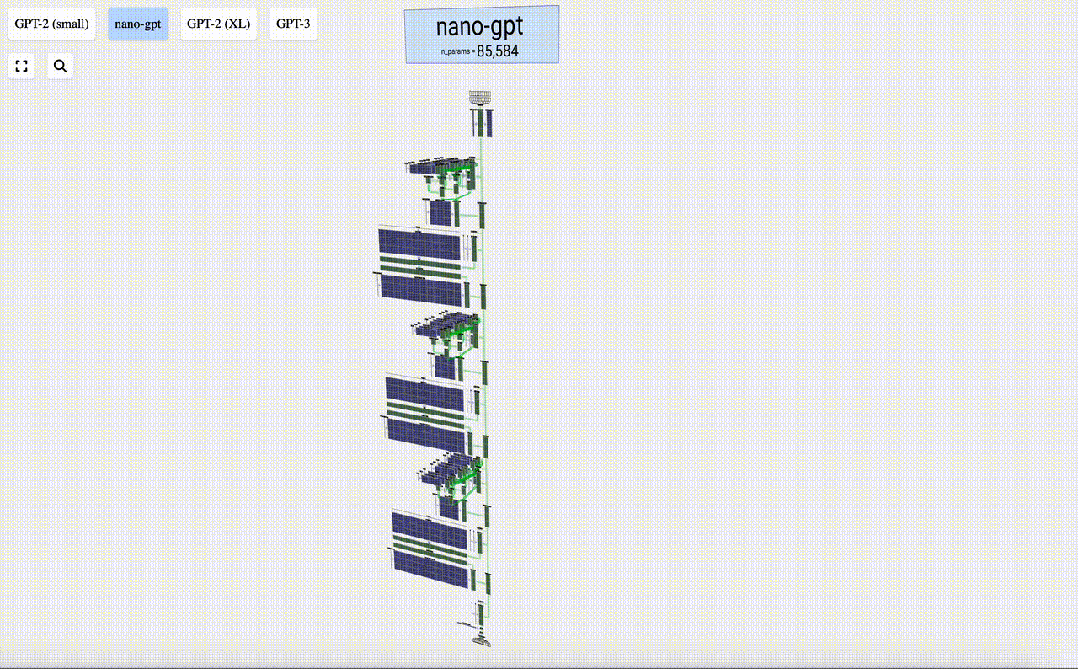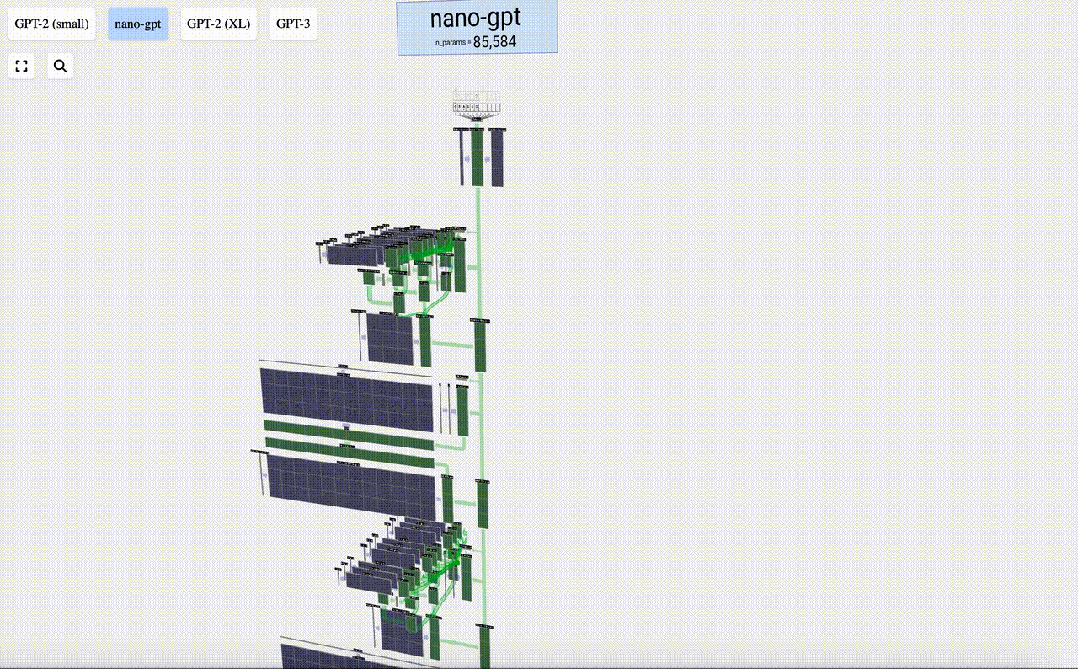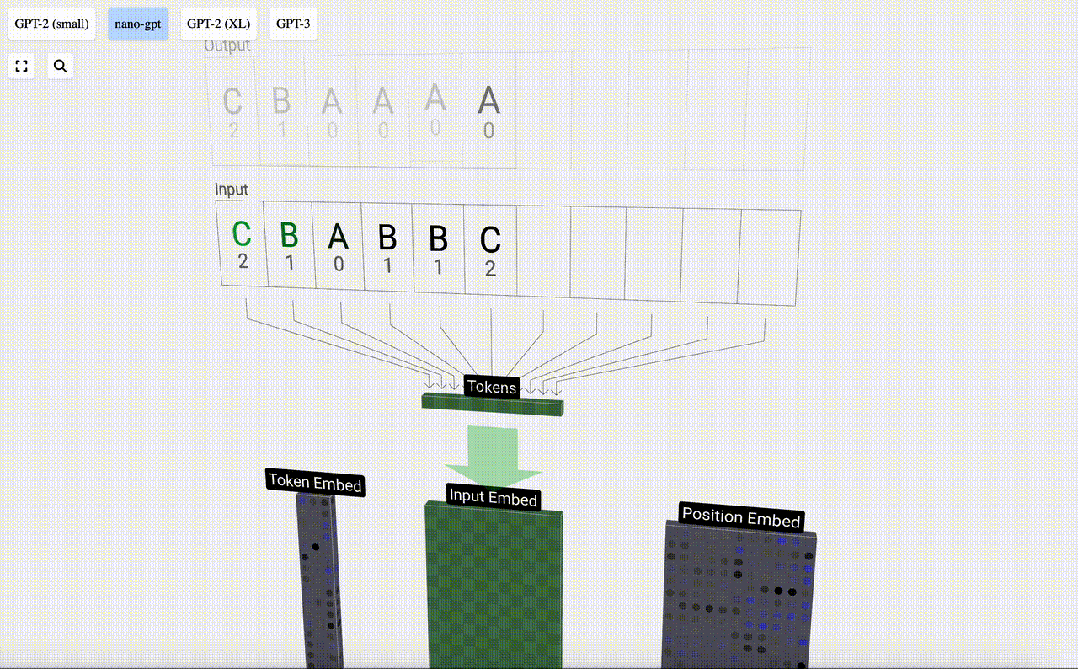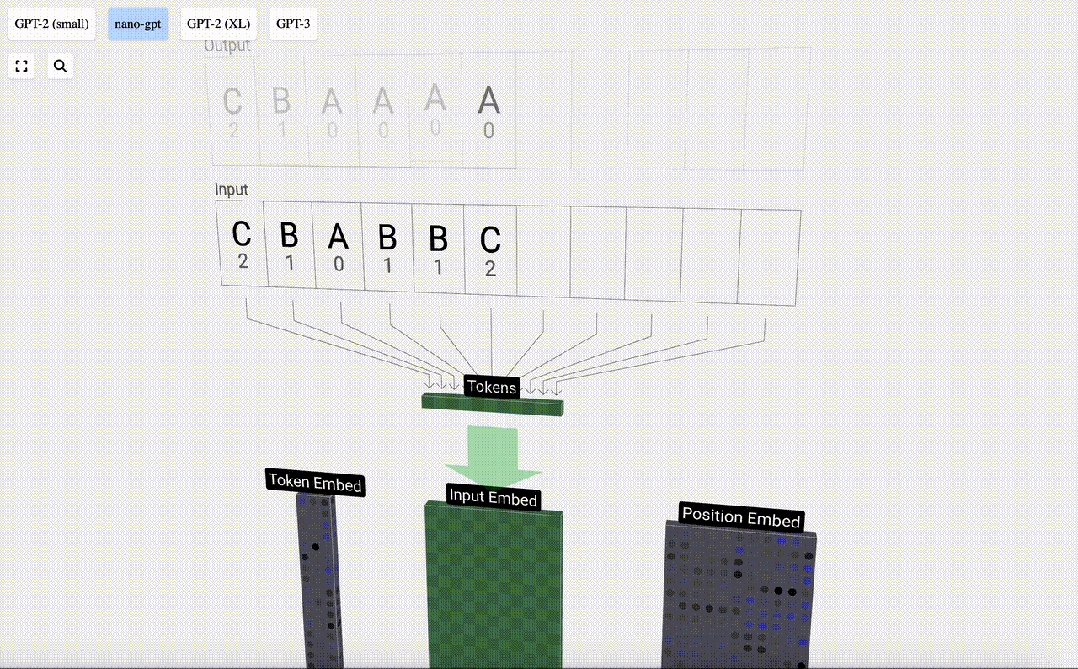
这个表中,每个token都被分配了一个数字,它是token index。现在我们可以将这一系列数字输入到模型中:「2 1 0 1 1 2」
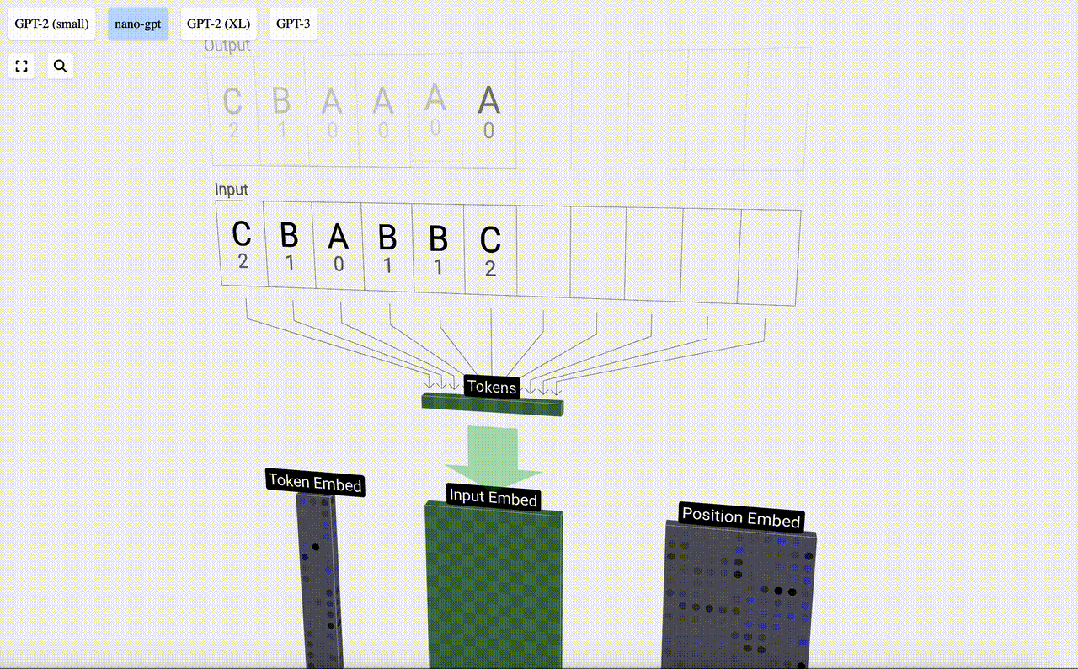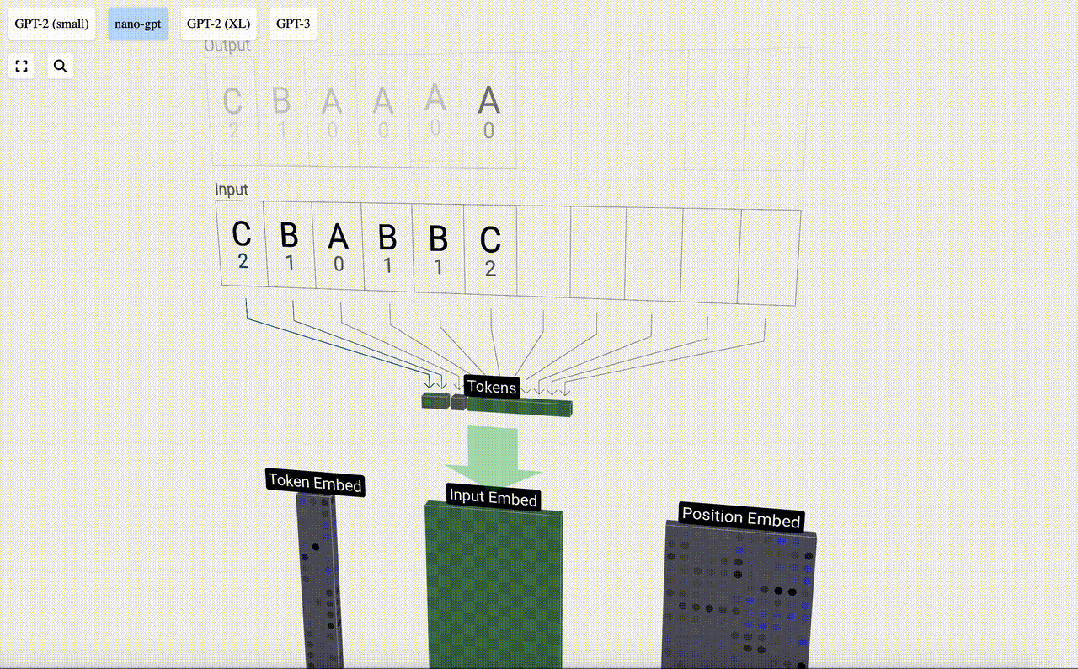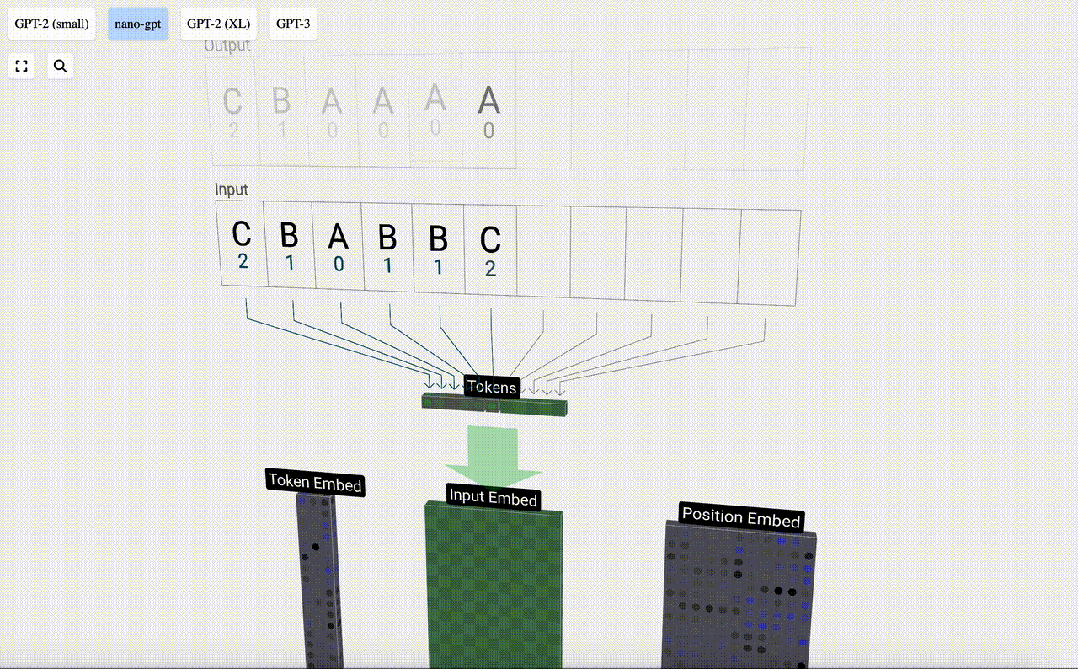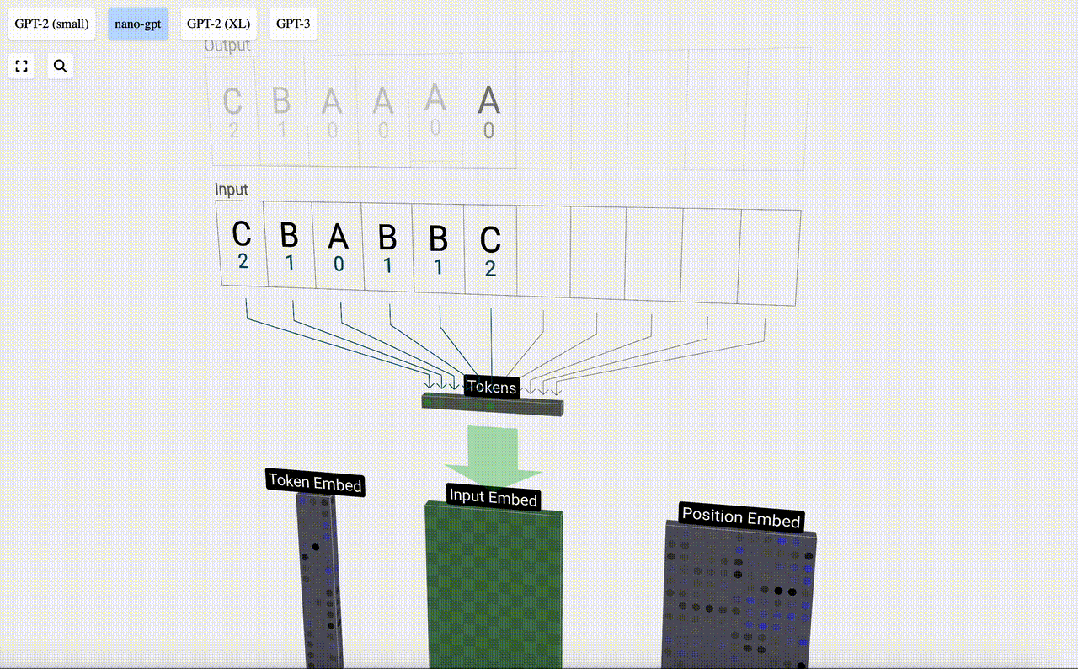
然后,「嵌入」被输入模型,传递通过一系列Transformer层,最后到达底层。

我们使用token index(在本例中为B = 1)来选择左侧token嵌入矩阵的第二列。请注意,我们在这里使用的是从0开始的index,因此第一列位于index 0处。
这将产生一个大小为C=48的列向量,我们将其描述为「token嵌入」(token embedding)。

请注意,这两个位置和token嵌入都是在训练期间学习的(由蓝色表示)。
现在我们有了这两个列向量,我们只需将它们相加即可生成另一个大小为C=48的列向量。

这里我们使用E[x]表示平均值,Var[x]表示方差(长度为C的列)。方差就是标准差的平方。ε项
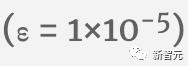
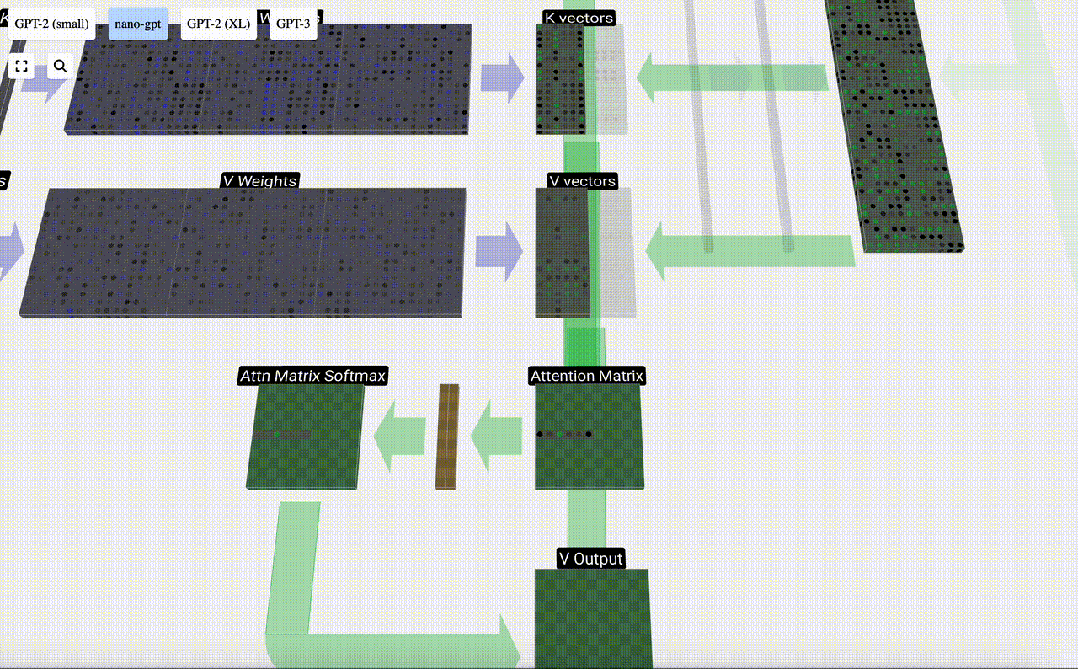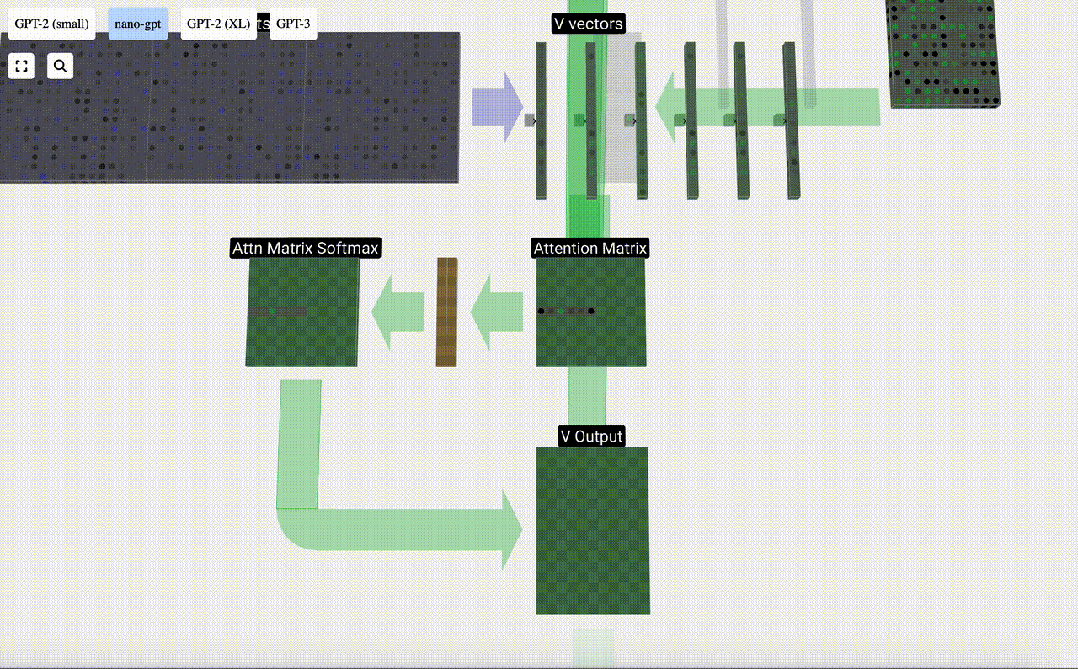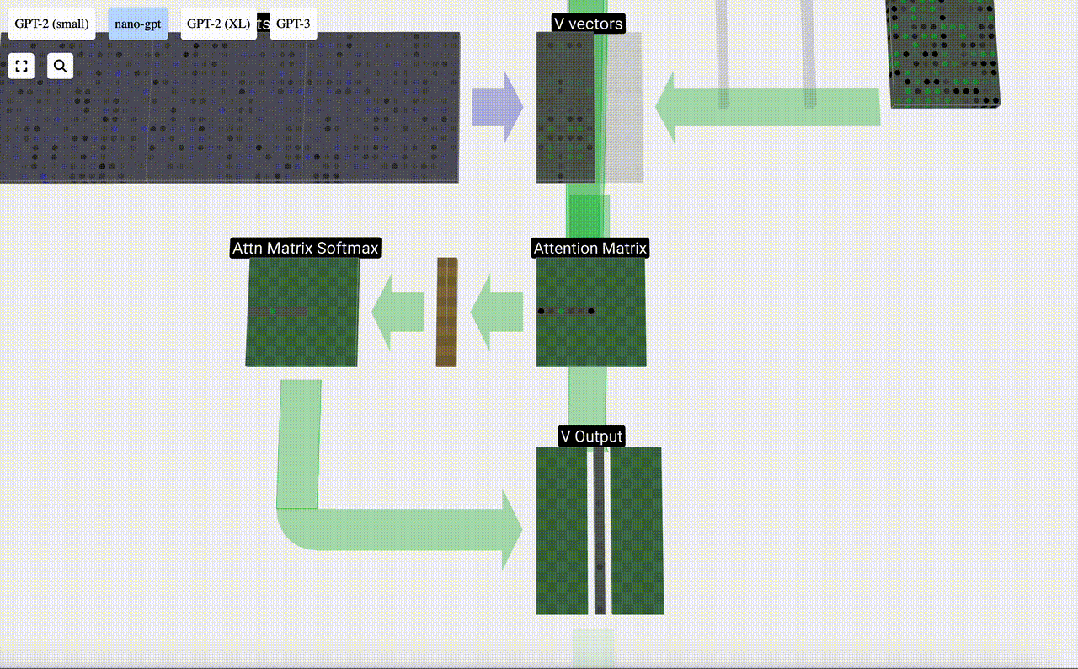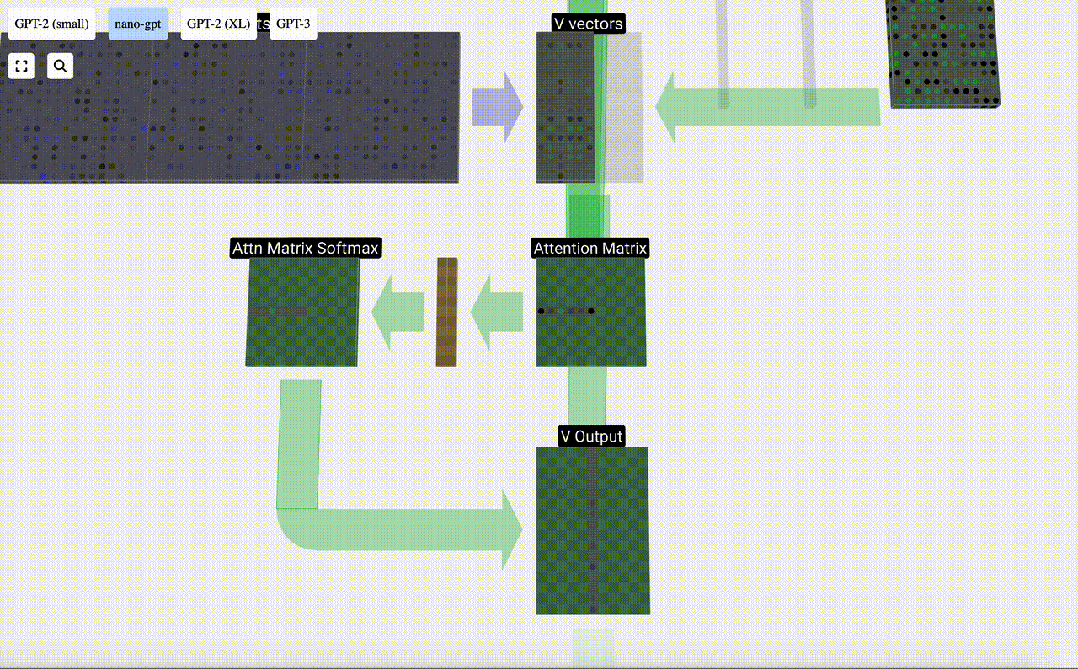
在自注意力的情况下,我们返回的不再是单个词条,而是词条的加权组合。
为了找到这个加权,我们在Q向量和K向量之间进行点乘。我们将加权归一化,最后用它与相应的V向量相乘,再将它们相加。

最后,我们就可以得出这一列(t=5)的输出向量。我们查看归一化自注意力矩阵的(t=5)行,并将每个元素与其他列的相应V向量相乘。
现在,我们得到了自注意力层的输出结果。
我们不会直接将这一输出传递到下一阶段,而是将其按元素顺序添加到输入嵌入中。绿色垂直箭头表示的这一过程被称为残差连接(residual connection)或残差路径(residual pathway)。
与「层归一化」一样,残差路径对于实现深度神经网络的有效学习非常重要。
有了自注意力的结果,我们就可以将其传递到Transformer的下一个部分:前馈神经网络。
MLP
在自注意力层之后,Transformer模块的下半部分是MLP(多层感知器)。虽然有点拗口,但在这里它是一个有两层的简单神经网络。
与自注意力一样,在向量进入MLP之前,我们要进行层归一化处理。
在MLP中,我们将每个长度为C=48的列向量(独立地)进行以下处理:
1. 添加偏置的线性变换,转换为长度为4*C的向量。
2. 一个GELU激活函数(按元素计算)
3. 进行线性变换并添加偏置,返回长度为C的向量
让我们追踪其中一个向量:
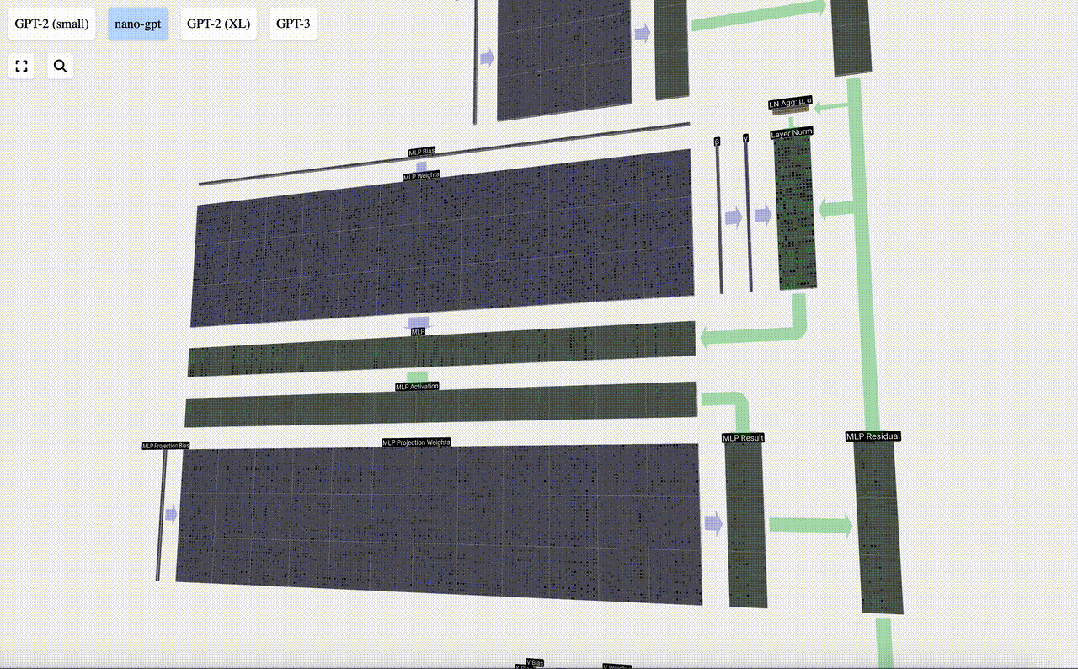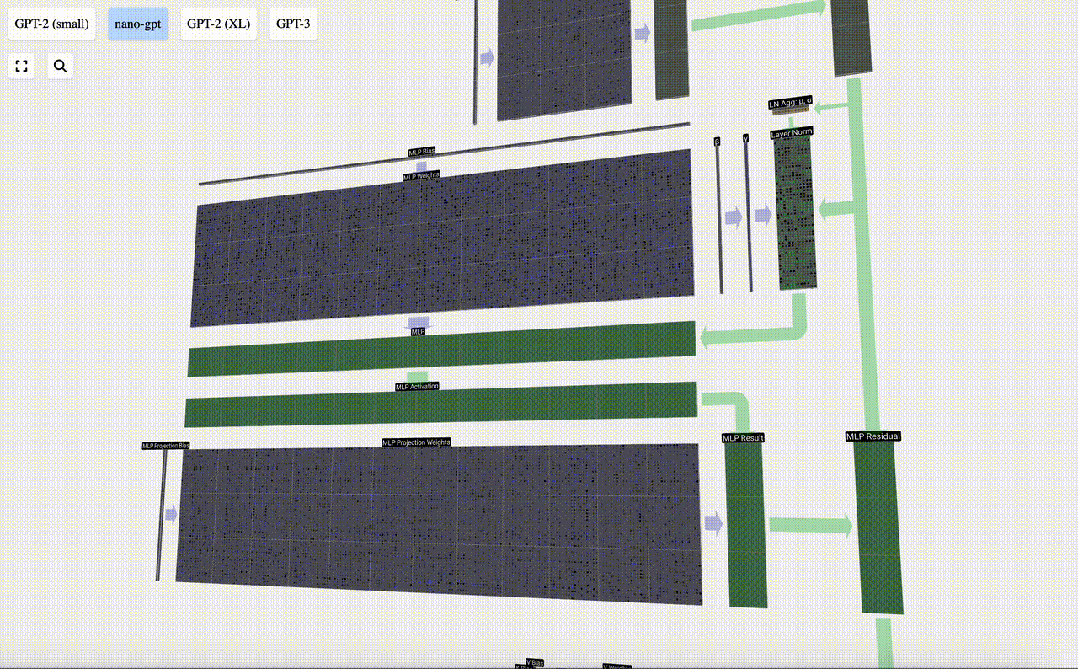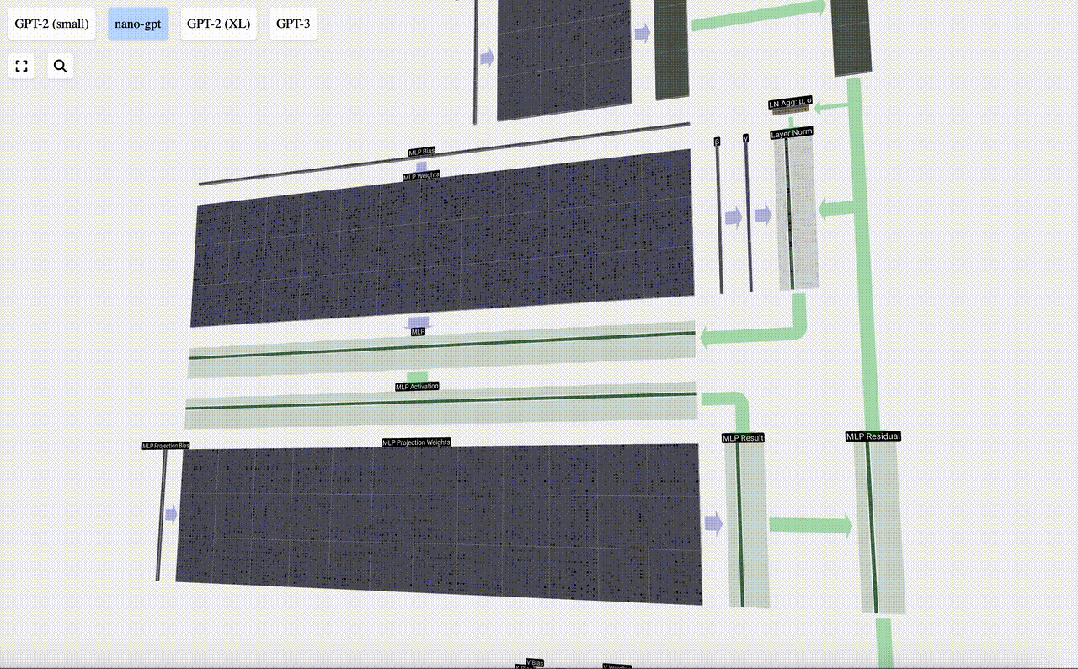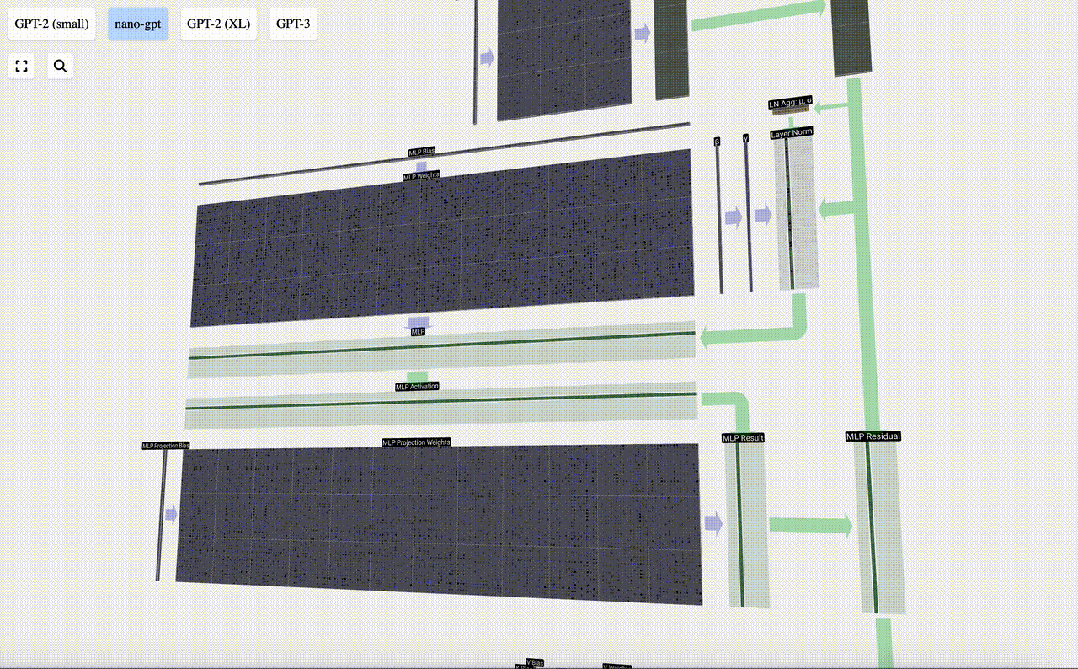
我们首先进行带偏置的矩阵-向量乘法运算,将向量扩展为长度为4*C 的矩阵。(请注意,输出矩阵在这里进行了转置,这纯粹是为了更加形象化)
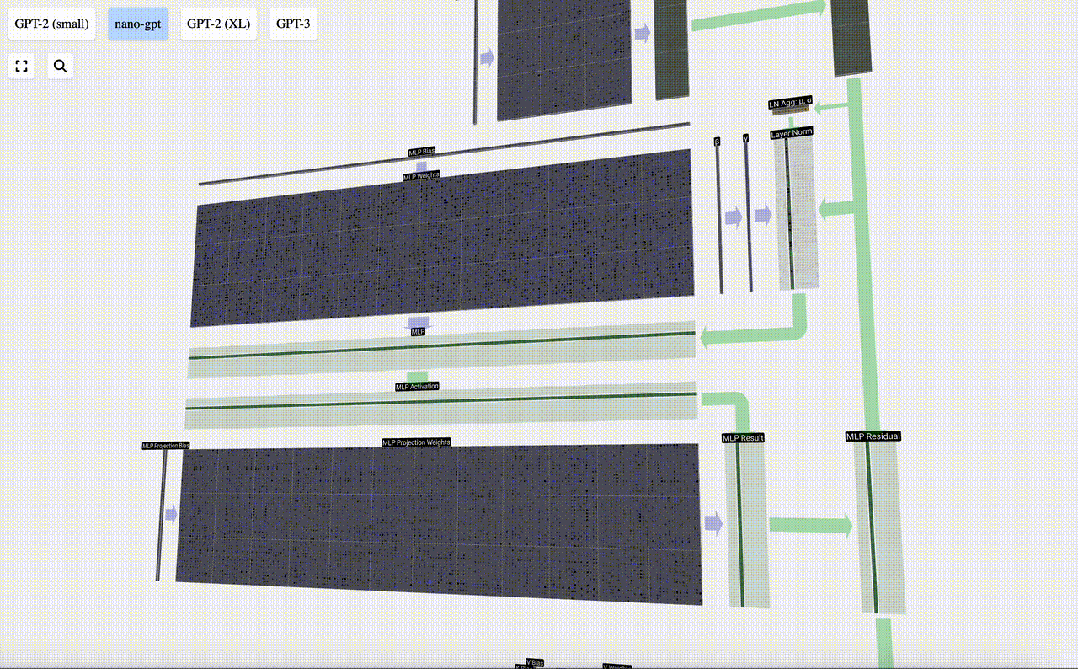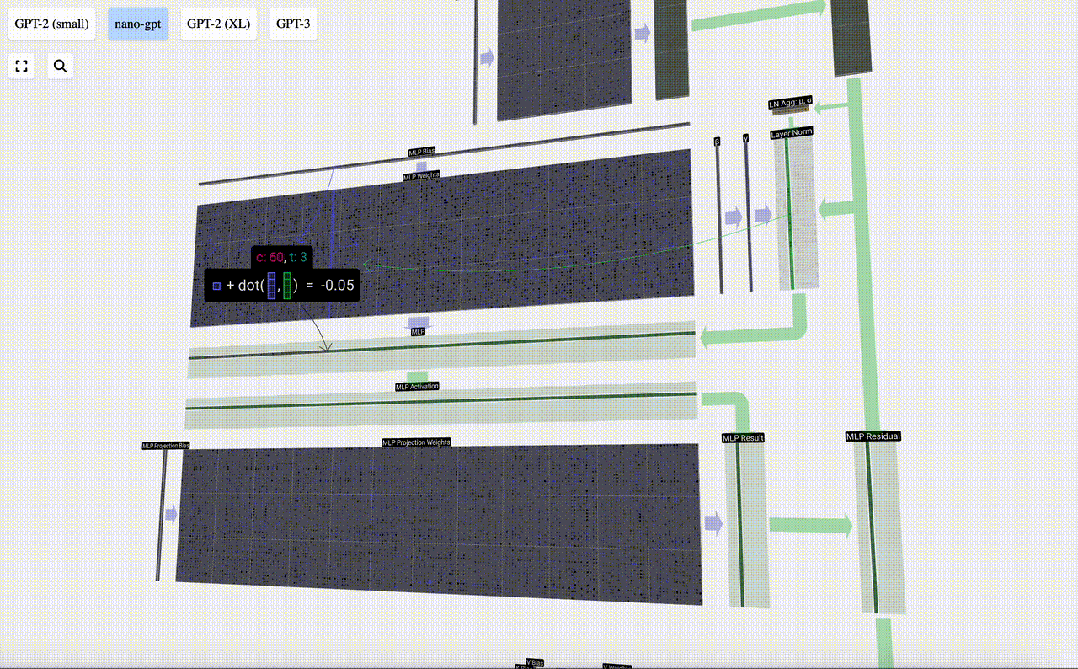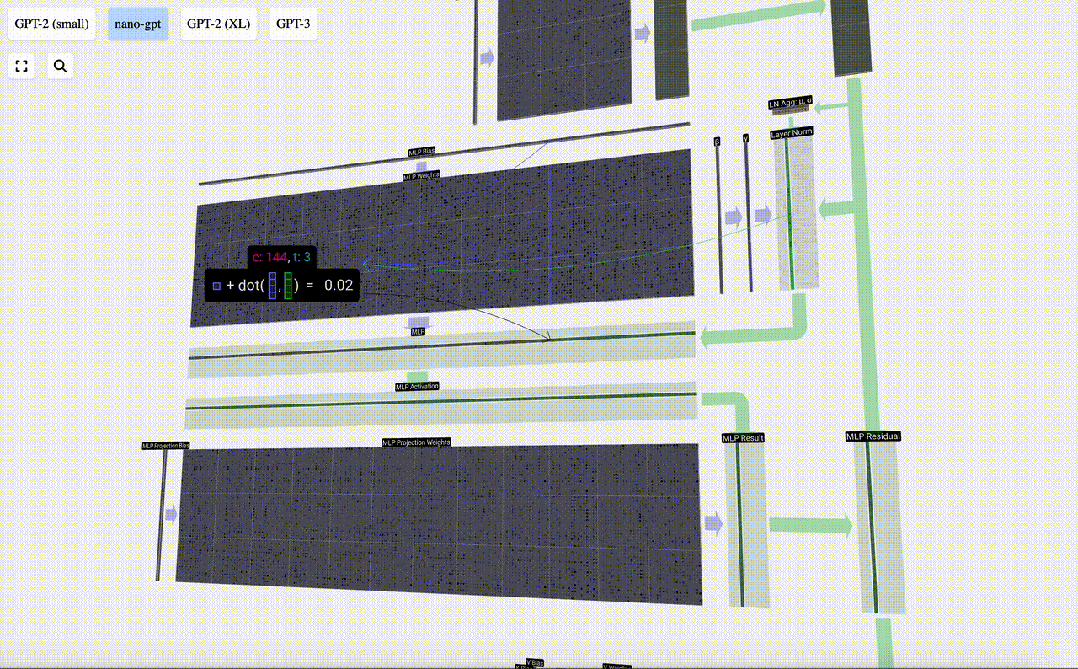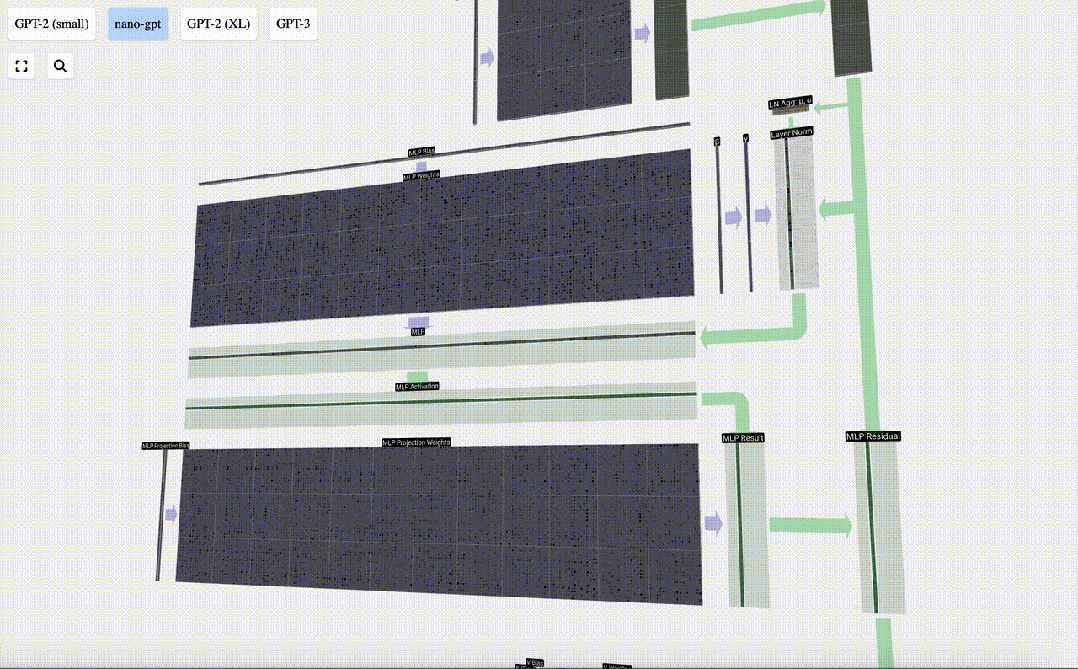
然后,我们通过另一个带偏置的矩阵-向量乘法,将向量投影回长度C。
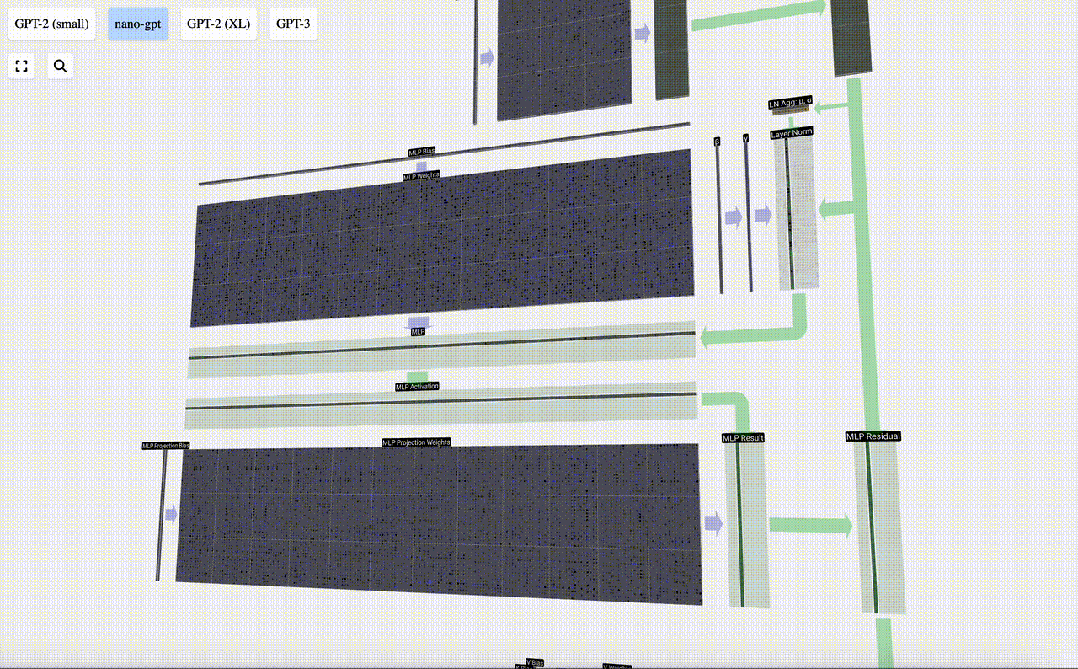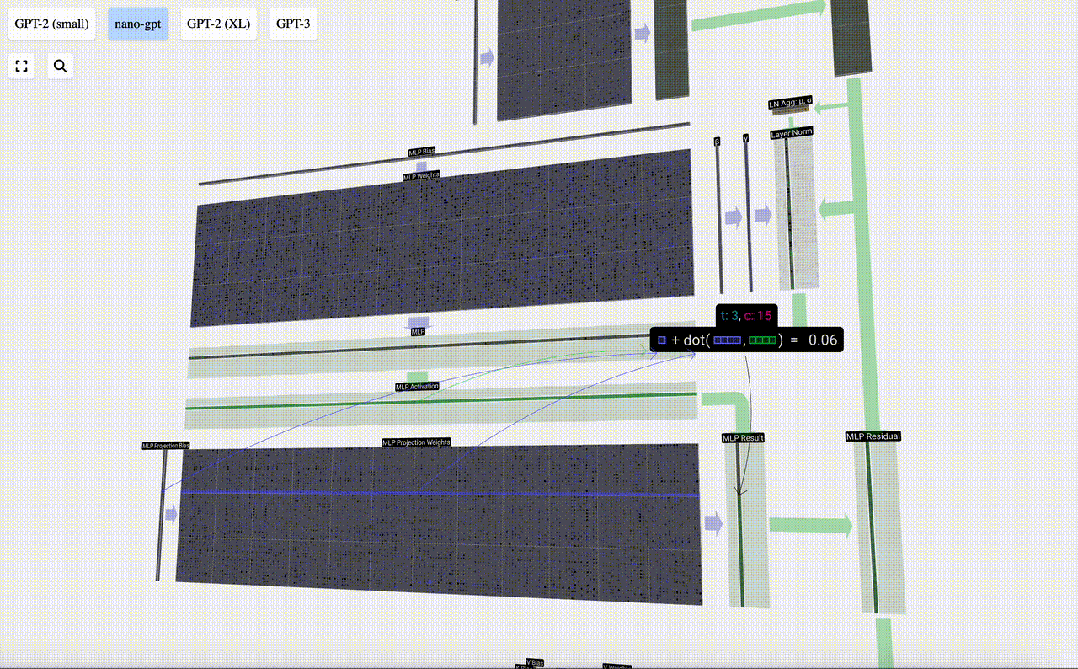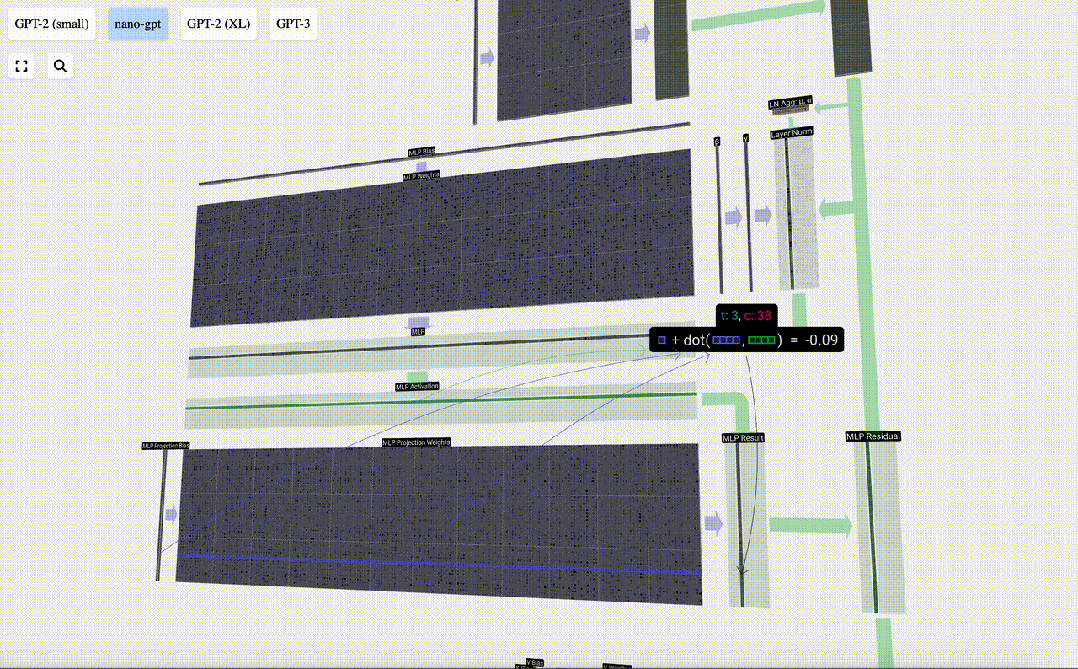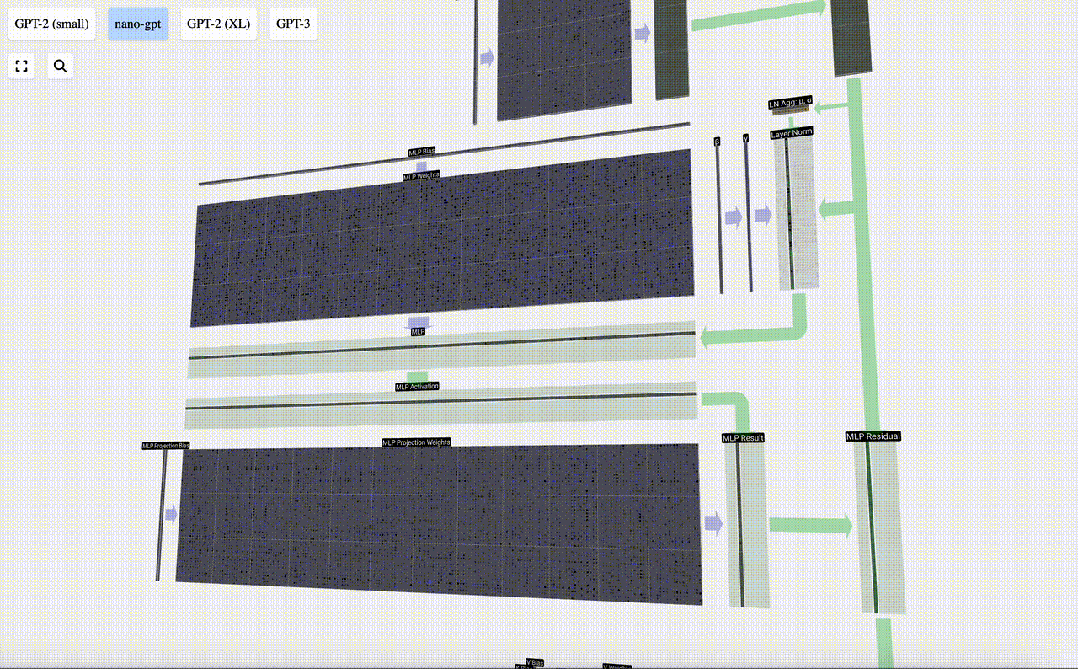
输出
最后一个Transformer块的输出,首先会经过层归一化,然后再进行线性变换(矩阵乘法),不过这次没有加入偏置项。
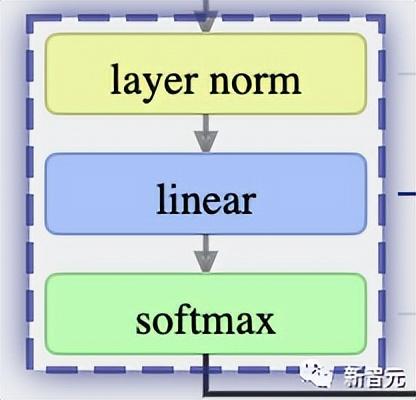
最后的transformation会将每个列向量的长度从C变为nvocab。因此,实际上是在为每一列的词汇库中的每个词产生一个得分——Logits。
「logits」这个术语源自「log-odds」,也就是每个token的对数几率。之所以会使用「Log」(对数),是因为接下来应用的softmax会进行指数转换,从而把这些得分变成「几率」或者说概率。
为了把这些得分转化为更加直观的概率值,需要先通过softmax来进行处理。现在,每一列都得到了模型对词汇表中每个词所分配的概率。
在这个特定的模型中,它已经有效地学会了所有关于如何排序三个字母的问题的答案,因此给出的概率值,也很大概率会倾向于正确答案。
在对模型进行时间步进时,需要利用最后一列的概率值来决定下一个要添加到序列中的token。举个例子,如果已经向模型输入了6个token,那么就会用第6列的输出概率来决策。
这一列输出的是一系列概率值,因此必须从中选择一个作为序列的下一个元素。这需要通过「从分布中采样」来实现。也就是说,会根据概率值的权重随机选择一个token。例如,一个概率为0.9的token有90%的概率被选中。
当然,还有其他选择方法,比如始终选择概率最高的token。
此外,还可以通过使用温度参数来控制分布的「平滑度」。较高的温度会让分布更均匀,而较低的温度则会让分布更集中于概率最高的token。
在应用softmax之前,先用温度除以logits(线性变换的输出)。由于softmax中的指数化对较大的数值影响较大,因此将所有数字拉近会减少这种影响。

参考资料:
相关文章






关于作者

猜你喜欢
成员 网址收录40386 企业收录2981 印章生成229738 电子证书1009 电子名片58 自媒体46284































